This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
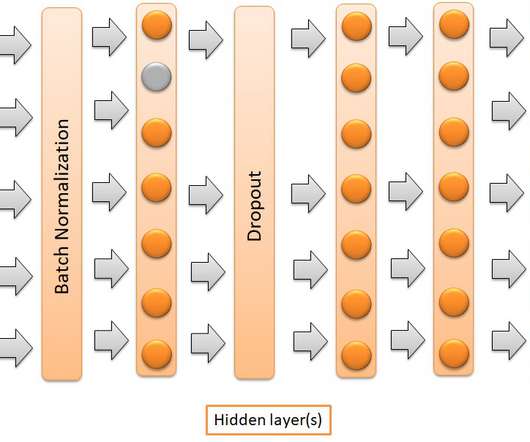
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Last time I wrote about hyperparameter-tuning using Bayesian Optimization: bayes_opt. The post Tuning the Hyperparameters and Layers of Neural Network DeepLearning appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon In terms of ML, what neural network means? The post Neural network and hyperparameter optimization using Talos appeared first on Analytics Vidhya. A neural network.
We talked about enterprise data warehouses in the past, so let’s contrast them with data lakes. Both data warehouses and data lakes are used when storing big data. Many people are confused about these two, but the only similarity between them is the high-level principle of data storing. Data Warehouse.
While artificial intelligence (AI), machine learning (ML), deeplearning and neural networks are related technologies, the terms are often used interchangeably, which frequently leads to confusion about their differences. How do artificial intelligence, machine learning, deeplearning and neural networks relate to each other?
As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. Newer data lakes are highly scalable and can ingest structured and semi-structureddata along with unstructured data like text, images, video, and audio.
From automating tedious tasks to unlocking insights from unstructured data, the potential seems limitless. Think about it: LLMs like GPT-3 are incredibly complex deeplearning models trained on massive datasets. In retail, they can personalize recommendations and optimize marketing campaigns. Theyre impressive, no doubt.
In terms of representation, data can be broadly classified into two types: structured and unstructured. Structureddata can be defined as data that can be stored in relational databases, and unstructured data as everything else. Here we briefly describe some of the challenges that data poses to AI.
Data is often divided into three categories: training data (helps the model learn), validation data (tunes the model) and test data (assesses the model’s performance). For optimal performance, AI models should receive data from a diverse datasets (e.g.,
O’Reilly Media had an earlier survey about deeplearning tools which showed the top three frameworks to be TensorFlow (61% of all respondents), Keras (25%), and PyTorch (20%)—and note that Keras in this case is likely used as an abstraction layer atop TensorFlow. The data types used in deeplearning are interesting.
Data extraction Once you’ve assigned numerical values, you will apply one or more text-mining techniques to the structureddata to extract insights from social media data. A targeted approach will optimize the user experience and enhance an organization’s ROI. positive, negative or neutral).
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. Amazon Redshift’s advanced Query Optimizer is a crucial part of that leading performance.
Recent AI developments are also helping businesses automate and optimize HR recruiting and professional development, DevOps and cloud management, and biotech research and manufacturing. How will you empower teams to make use of your data? One of the key elements in data democratization is the concept of data as a product.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content