This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Supervised learning is the most popular ML technique among mature AI adopters, while deeplearning is the most popular technique among organizations that are still evaluating AI. Managing AI/ML risk. We asked respondents to select all of the applicable risks they try to control for in building and deploying ML models.
Consider deeplearning, a specific form of machine learning that resurfaced in 2011/2012 due to record-setting models in speech and computer vision. Machine learning is not only appearing in more products and systems, but as we noted in a previous post , ML will also change how applications themselves get built in the future.
John Myles White , data scientist and engineering manager at Facebook, wrote: “The biggest risk I see with data science projects is that analyzing data per se is generally a bad thing. So when you’re missing data or have “low-quality data,” you use assumptions, statistics, and inference to repair your data.
“The flashpoint moment is that rather than being based on rules, statistics, and thresholds, now these systems are being imbued with the power of deeplearning and deep reinforcement learning brought about by neural networks,” Mattmann says. Adding smarter AI also adds risk, of course. “At
Data science needs knowledge from a variety of fields including statistics, mathematics, programming, and transforming data. Mathematics, statistics, and programming are pillars of data science. In data science, use linear algebra for understanding the statistical graphs. It is the building block of statistics.
1] This includes C-suite executives, front-line data scientists, and risk, legal, and compliance personnel. These recommendations are based on our experience, both as a data scientist and as a lawyer, focused on managing the risks of deploying ML. That’s where model debugging comes in. Sensitivity analysis.
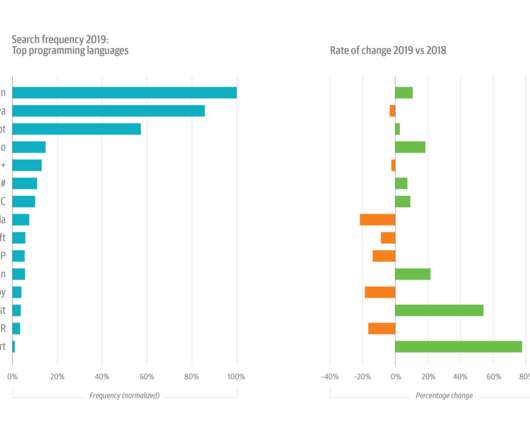
There’s plenty of security risks for business executives, sysadmins, DBAs, developers, etc., Normalized search frequency of top terms on the O’Reilly online learning platform in 2019 (left) and the rate of change for each term (right). to be wary of. Figure 1 (above).
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machine learning models from malicious actors. Like many others, I’ve known for some time that machine learning models themselves could pose security risks. Watermark attacks. Newer types of fair and private models (e.g.,
Pragmatically, machine learning is the part of AI that “works”: algorithms and techniques that you can implement now in real products. We won’t go into the mathematics or engineering of modern machine learning here. Machine learning adds uncertainty. Managing Machine Learning Projects” (AWS).
Predictive analytics definition Predictive analytics is a category of data analytics aimed at making predictions about future outcomes based on historical data and analytics techniques such as statistical modeling and machine learning. Financial services: Develop credit risk models. from 2022 to 2028.
The chief aim of data analytics is to apply statistical analysis and technologies on data to find trends and solve problems. Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance.
People tend to use these phrases almost interchangeably: Artificial Intelligence (AI), Machine Learning (ML) and DeepLearning. DeepLearning is a specific ML technique. Most DeepLearning methods involve artificial neural networks, modeling how our bran works.
It’s a role that requires experience with natural language processing , coding languages, statistical models, and large language and generative AI models. Deeplearning is a subset of AI , and vital to the development of gen AI tools and resources in the enterprise.
When you hear about Data Science, Big Data, Analytics, Artificial Intelligence, Machine Learning, or DeepLearning, you may end up feeling a bit confused about what these terms mean. A foundational data analysis tool is Statistics , and everyone intuitively applies it daily. So, what do these terms really mean?
Through a marriage of traditional statistics with fast-paced, code-first computer science doctrine and business acumen, data science teams can solve problems with more accuracy and precision than ever before, especially when combined with soft skills in creativity and communication. Math and Statistics Expertise.
Certified Information Systems Auditor (CISA); PMI Program, Portfolio, and Risk Management Professionals (PgMP, PfMP and PMI-RMP); Six Sigma Black Belt and Master Black Belt; Certified in Governance, Risk, and Compliance (ISC2); and Certified in Risk and Information Systems Control (CRISC) also drew large premiums.
From the statistics shown, this means that both AI and big data have the potential to affect how we work in the workplace. Above all, there needs to be a set methodology for data mining, collection, and structure within the organization before data is run through a deeplearning algorithm or machine learning.
To start with, SR 11-7 lays out the criticality of model validation in an effective model risk management practice: Model validation is the set of processes and activities intended to verify that models are performing as expected, in line with their design objectives and business uses.
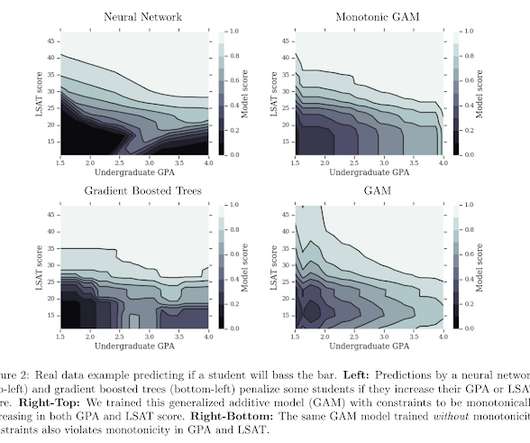
On the one hand, basic statistical models (e.g. On the other hand, sophisticated machine learning models are flexible in their form but not easy to control. More knots make the learned feature transformation smoother and more capable of approximating any monotonic function.
Companies that work on machine learning for health care, like Google, create large groups of medical images selected by physicians. Machine learning algorithms use these sets of visual data to look for statistical patterns to identify which image features allow you to assume that it is worthy of a particular label or diagnosis.
To build that trust and drive broad adoption, vendors of synthetic data generation tools will need to address two critical questions that many business leaders ask: Will synthetic data expose my business to additional data privacy risks? How accurately does synthetic data reflect my existing data? This is partially true for synthetic data.
Generative AI represents a significant advancement in deeplearning and AI development, with some suggesting it’s a move towards developing “ strong AI.” Generative AI uses advanced machine learning algorithms and techniques to analyze patterns and build statistical models.
Ludwig is a tool that allows people to build data-based deeplearning models to make predictions. When Google talked about releasing this tool in its blog, the brand pointed out that if you don’t protect user data, you risk losing people’s trust. Here are some open-source options to consider. Kubernetes.
Areas making up the data science field include mining, statistics, data analytics, data modeling, machine learning modeling and programming. Ultimately, data science is used in defining new business problems that machine learning techniques and statistical analysis can then help solve.
The US City of Atlanta , for example, uses IBM data collection, machine learning and AI to monitor public transit tunnel ventilation systems and predict potential failures that could put passengers at risk.
The unprecedented circumstances surrounding pandemic have increased awareness around insurable risks across different financial losses that can be covered as everyone in the world have faced financial losses like unemployment, travel cancellation, health issues, business interruptions, etc. The way ahead for insurers.
ML is a computer science, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. Supervised learning is commonly used for risk assessment, image recognition, predictive analytics and fraud detection, and comprises several types of algorithms.
Rules-based fraud detection (top) vs. classification decision tree-based detection (bottom): The risk scoring in the former model is calculated using policy-based, manually crafted rules and their corresponding weights. deeplearning) there is no guaranteed explainability. It can be implemented as either unsupervised (e.g.
LLMs like ChatGPT are trained on massive amounts of text data, allowing them to recognize patterns and statistical relationships within language. Building an in-house team with AI, deeplearning , machine learning (ML) and data science skills is a strategic move.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects.
O’Reilly Media had an earlier survey about deeplearning tools which showed the top three frameworks to be TensorFlow (61% of all respondents), Keras (25%), and PyTorch (20%)—and note that Keras in this case is likely used as an abstraction layer atop TensorFlow. The data types used in deeplearning are interesting.
It used deeplearning to build an automated question answering system and a knowledge base based on that information. This really rewards companies with an experimental culture where they can take intelligent risks and they’re comfortable with those uncertainties.
This isn’t always simple, since it doesn’t just take into account technical risk; it also has to account for social risk and reputational damage. A product needs to balance the investment of resources against the risks of moving forward without a full understanding of the data landscape. arbitrary stemming, stop word removal.).
First, 82% of the respondents are using supervised learning, and 67% are using deeplearning. Deeplearning is a set of algorithms that are common to almost all AI approaches, so this overlap isn’t surprising. 58% claimed to be using unsupervised learning. Risks checked for during development.
Models can predict things before they happen more accurately than humans, such as catastrophic weather events or who is at risk of imminent death in a hospital. PyTorch: used for deeplearning models, like natural language processing and computer vision. It’s used for developing deeplearning models.
That’s a risk in case, say, legislators – who don’t understand the nuances of machine learning – attempt to define a single meaning of the word interpret. For example, in the case of more recent deeplearning work, a complete explanation might be possible: it might also entail an incomprehensible number of parameters.
He was saying this doesn’t belong just in statistics. It involved a lot of work with applied math, some depth in statistics and visualization, and also a lot of communication skills. and drop your deeplearning model resource footprint by 5-6 orders of magnitude and run it on devices that don’t even have batteries.
You can sleep at night as a data scientician and you know you’re not building a random number generator, but the people from product, they don’t want to know just that you can predict who’s going to be at risk. They want to know what are the risky behaviors. ” But then I realized I could crowdsource it.
Observability” risks becoming the new name for monitoring. AI, Machine Learning, and Data. Healthy growth in artificial intelligence has continued: machine learning is up 14%, while AI is up 64%; data science is up 16%, and statistics is up 47%. And that’s unfortunate.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content