This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, commits can still fail if the latest metadata is updated after the base metadata version is established. Iceberg uses a layered architecture to manage table state and data: Catalog layer Maintains a pointer to the current table metadata file, serving as the single source of truth for table state.
Whether youre a data analyst seeking a specific metric or a data steward validating metadata compliance, this update delivers a more precise, governed, and intuitive search experience. Refer to the product documentation to learn more about how to set up metadata rules for subscription and publishing workflows.
For instructions, refer to Creating a general purpose bucket. For this demo, we use Amazon Bedrock to access the Amazon Nova FMs. It reads metadata from your structured data store to generate SQL queries. For more information, refer to the Set up query engine for your structured data store in Amazon Bedrock Knowledge Bases.
What Is Metadata? Metadata is information about data. A clothing catalog or dictionary are both examples of metadata repositories. Indeed, a popular online catalog, like Amazon, offers rich metadata around products to guide shoppers: ratings, reviews, and product details are all examples of metadata.
The data is also registered in the Glue Data Catalog , a metadata repository. Prerequisites Complete the following prerequisites before setting up the solution: Create a bucket in Amazon S3 called zero-etl-demo- - (for example, zero-etl-demo-012345678901-us-east-1 ). For this post, choose Use AWS managed KMS key. Choose Next.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. In the following steps, replace amzn-s3-demo-destination-bucket with the name of the S3 bucket. An AWS Glue Data Catalog database.
Organization’s cannot hope to make the most out of a data-driven strategy, without at least some degree of metadata-driven automation. Metadata-Driven Automation in the BFSI Industry. Metadata-Driven Automation in the Pharmaceutical Industry. Metadata-Driven Automation in the Insurance Industry.
BladeBridge provides a configurable framework to seamlessly convert legacy metadata and code into more modern services such as Amazon Redshift. Contact BladeBridge through Request demo and obtain an Analyzer key for your organization. For more details, refer to the BladeBridge Analyzer Demo.
There may even be someone on your team who built a personalized video recommender before and can help scope and estimate the project requirements using that past experience as a point of reference. You might have millions of short videos , with user ratings and limited metadata about the creators or content. AI doesn’t fit that model.
Organizations with particularly deep data stores might need a data catalog with advanced capabilities, such as automated metadata harvesting to speed up the data preparation process. Three Types of Metadata in a Data Catalog. The metadata provides information about the asset that makes it easier to locate, understand and evaluate.
We use AWS Glue , a fully managed, serverless, ETL (extract, transform, and load) service, and the Google BigQuery Connector for AWS Glue (for more information, refer to Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors ). If you don’t have one, refer to Amazon Redshift Serverless. An S3 bucket.
AWS has invested in native service integration with Apache Hudi and published technical contents to enable you to use Apache Hudi with AWS Glue (for example, refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started ).
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
It also offers reference implementation of an object model to persist metadata along with integration to major data and analytics tools. Lineage form types – Form types, or facets , provide additional metadata or context about lineage entities or events, enabling richer and more descriptive lineage information. Choose Run.
Metadata management is essential to becoming a data-driven organization and reaping the competitive advantage your organization’s data offers. Gartner refers to metadata as data that is used to enhance the usability, comprehension, utility or functionality of any other data point. How the data has changed.
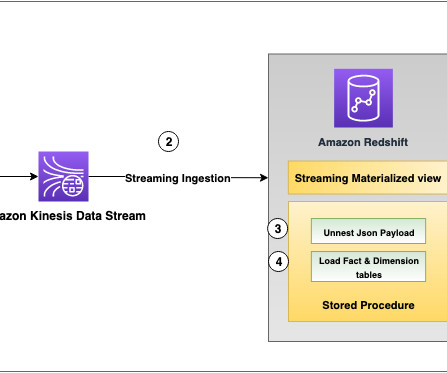
As shown in the following reference architecture, DynamoDB table data changes are streamed into Amazon Redshift through Kinesis Data Streams and Amazon Redshift streaming ingestion for near-real-time analytics dashboard visualization using Amazon QuickSight. For instructions, refer to Create a sample Amazon Redshift cluster.
Athena uses the AWS Glue Data Catalog to store and retrieve table metadata for the Amazon S3 data in Iceberg format. Before proceeding with the demo, create a folder named custdata under the created S3 bucket. For Data stream name , enter demo-data-stream. Select the Kinesis data stream demo-data-stream.
For more information about partitioning with Athena and Redshift Spectrum, refer to Partitioning data in Athena and Creating external tables for Redshift Spectrum , respectively. First, we create a database for this demo. For more information, refer to Why do I get zero records when I query my Amazon Athena table.
If my explanation above is the correct interpretation of the high percentage, and if the statement refers to successfully deployed applications (i.e., A similarly high percentage of tabular data usage among data scientists was mentioned here.
Bard Google’s code name for its chat-oriented search engine, based on their LaMDA model, and only demoed once in public. There’s a very important difference between these two almost identical sentences: in the first, “it” refers to the cup. In the second, “it” refers to the pitcher. These are questions we can’t not answer.
The Common Crawl corpus contains petabytes of data, regularly collected since 2008, and contains raw webpage data, metadata extracts, and text extracts. For instructions, refer to Create your first S3 bucket. For instructions, refer to Get started. For explanations of each field, refer to Common Crawl Index Athena.
To enable multimodal search across text, images, and combinations of the two, you generate embeddings for both text-based image metadata and the image itself. Note that you need to refer to the Jupyter Notebook in the GitHub repository to run the following steps using Python code in your client environment. OpenSearch version is 2.13
Now users seek methods that allow them to get even more relevant results through semantic understanding or even search through image visual similarities instead of textual search of metadata. To learn more, refer to Byte-quantized vectors in OpenSearch. The following screenshot shows an example of using the Compare Search Results tool.
Eliminating dependency on business units – Redshift Spectrum uses a metadata layer to directly query the data residing in S3 data lakes, eliminating the need for data copying or relying on individual business units to initiate the copy jobs. If you don’t have one, refer to How do I create and activate a new AWS account?
In other words, using metadata about data science work to generate code. One of the longer-term trends that we’re seeing with Airflow , and so on, is to externalize graph-based metadata and leverage it beyond the lifecycle of a single SQL query, making our workflows smarter and more robust. BTW, videos for Rev2 are up: [link].
Here, the * indicates that this data source will bring into Amazon DataZone all the technical metadata from the database tables of your schema (in this case, a single table called catalog_sales ). On the next page, automated metadata generation is enabled. Choose Next. Choose Next. Review all settings and choose Create data source.
In Amazon DataZone, data owners can publish their data and its business catalog (metadata) to ATPCO’s DataZone domain. Data consumers can then search for relevant data assets using these human-friendly metadata terms. For Metadata generation methods , keep this box selected. For Publishing settings , select No.
In data governance terms, an automation framework refers to a metadata-driven universal code generator that works hand in hand with enterprise data mapping for: Pre-ETL enterprise data mapping. Governing metadata. The 100-percent metadata-driven approach is critical to creating reliable and consistent CATs.
This creates a demo environment, including an MSK Serverless cluster , three Lambda functions, and an API Gateway that consumes the messages from the Kafka topic. For information about how to configure the producer for connectivity, refer to IAM access control. Note that we don’t need to worry about Availability Zones.
Tags are key-value metadata that can be associated with AWS service resources. In the following screenshots, our example MSK Connect connector, plugin, and worker configuration have been tagged with the resource tag key project and value demo-tags. For a list of Region availability, refer to AWS Services by Region.
Please refer to our earlier Cloudera blog for more details about Ozone’s performance benefits and atomicity guarantees. Apache Ozone achieves this significant capability through the use of some novel architectural choices by introducing bucket type in the metadata namespace server. FILE_SYSTEM_OPTIMIZED Bucket (“FSO”). LEGACY Bucket.
Queries can be written to intersect and analyze data sources using common metadata elements (for example, geography, shared identifiers, or other demographic factors), generating row-level lists of the overlap between the data sources or aggregated counts by population, condition, or other strata.
If you’re new to Amazon DataZone, refer to Getting started. Use case 3: Amazon S3 file uploads In addition to the download functionality, users often need to retain and attach metadata to new versions of files. Otherwise, refer to Create domains for instructions to set up a domain. The role starts with AmazonDataZone*.
To learn more, refer to About dbt models. To learn more, refer to Materializations and Incremental models. Install dbt and the dbt CLI with the following code: $ pip3 install --no-cache-dir dbt-core For more information, refer to How to install dbt , What is dbt? , Data engineers define dbt models for their data representations.
In this blog, we will discuss performance improvement that Cloudera has contributed to the Apache Iceberg project in regards to Iceberg metadata reads, and we’ll showcase the performance benefit using Apache Impala as the query engine. Impala can access Hive table metadata fast because HMS is backed by RDBMS, such as mysql or postgresql.
As such, your chosen tool must provide data quality management, perform data movement, track modifications of metadata objects, support cascade changes, expose metadata, and be capable of printing visual representations of data lineage. This maintains a high priority in your data governance strategy.
Publish the table metadata to the Amazon DataZone business data catalog. This pulls any new or modified metadata from the source and updates the associated assets in the inventory. The data source status changes to Running as Amazon DataZone updates the asset metadata. The following diagram illustrates this workflow.
Refer appendix section for more information on this feature. After the processed data is stored in Amazon S3, we create an AWS Glue crawler to create a Data Catalog table that acts as a metadata layer for the data. Refer to the first stack’s output. Refer to the first stack’s output. Refer to the first stack’s output.
Atlas provides open metadata management and governance capabilities to build a catalog of all assets, and also classify and govern these assets. References. Security and governance policies are set once and applied across all data and workloads. Provide a name for the database in the Database Name field. Click Create Database.
Solution overview The AWS Serverless Data Analytics Pipeline reference architecture provides a comprehensive, serverless solution for ingesting, processing, and analyzing data. For more details about models and parameters available, refer to Anthropic Claude Text Completions API.
It has a consistent framework that secures and provides governance for all data and metadata on private clouds, multiple public clouds, or hybrid clouds. The data from your existing data warehouse is migrated to the storage option you choose, and all the metadata is migrated into SDX (Shared Data Experiences) layer of Cloudera Data Platform.
Additionally, a set of key features will accelerate data governance and simplify the security of sensitive metadata. Alation empowers customers to seamlessly connect and plug in data quality tools of choice: to become the single system of reference for data. Book a demo today. In the latest release of Alation, 2022.2,
To learn how to create a topic , refer to Creating Amazon QuickSight Q topics. To learn how to embed the Q bar, refer to Embedding the Amazon QuickSight Q search bar for registered users or anonymous (unregistered) users. To see examples of embedded dashboards with Q, refer to the QuickSight DemoCentral.
Given the potential repercussions from inaccurate information (from mis-set expectations, funding mismatch to project delays) it didn’t surprise us that data science leaders packed the room at the Rev 2 Data Science Leaders Summit in New York for a live demo of our new “Control Center” functionalities designed specially for them. .
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content