This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we talk about conversational AI, were referring to systems designed to have a conversation, orchestrate workflows, and make decisions in real time. Its quick to implement and demos well. The prompt-and-pray approach is tempting because it demos well and feels fast.
Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO Data Lake with Buckets Demo Data Lake Management Conclusion References What is Data Engineering? Image Source: GitHub Table of Contents What is Data Engineering? Initially, we have the definition of Software […].
Someone hacks together a quick demo with ChatGPT and LlamaIndex. The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges?
For instructions, refer to Creating a general purpose bucket. For this demo, we use Amazon Bedrock to access the Amazon Nova FMs. For more information, refer to the Set up query engine for your structured data store in Amazon Bedrock Knowledge Bases. Create an Amazon Simple Storage Service (Amazon S3) bucket with a unique name.
For more information, refer to Amazon Redshift clusters. However, if you would like to implement this demo in your existing Amazon Redshift data warehouse, download Redshift query editor v2 notebook, Redshift Query profiler demo , and refer to the Data Loading section later in this post. Run cell #12.
For more detailed configuration, refer to Write properties in the Iceberg documentation. Replace with your database name, with your table name, amzn-s3-demo-bucket with your S3 bucket name. These conflicts are typically transient and can be automatically resolved through retries. config(f"spark.sql.catalog. groupBy("value").agg(max_("timestamp").alias("timestamp"))
Prerequisites Complete the following prerequisites before setting up the solution: Create a bucket in Amazon S3 called zero-etl-demo- - (for example, zero-etl-demo-012345678901-us-east-1 ). Create an AWS Glue database , such as zero_etl_demo_db and associate the S3 bucket zero-etl-demo- - as a location of the database.
In the following steps, replace amzn-s3-demo-destination-bucket with the name of the S3 bucket. For Role name , enter a role name (for this post, GlueJobRole-demo ). On the Job Details tab, under Basic properties, specify the IAM role that the job will use ( GlueJobRole-demo ). An AWS Glue Data Catalog database. Choose Next.
During the development of Operational Database and Replication Manager, I kept telling folks across the team it has to be “so simple that a 10 year old can demo it”. so simple that a 10 year old can demo it”. Watch this: Enterprise Software that is so easy a 10 year old can demo it.
Contact BladeBridge through Request demo and obtain an Analyzer key for your organization. For more details, refer to the BladeBridge Analyzer Demo. Refer to this BladeBridge documentation to get more details on SQL and expression conversion. This line ending also can be replaced with other breakers.
In your Google Cloud project, youve enabled the following APIs: Google Analytics API Google Analytics Admin API Google Analytics Data API Google Sheets API Google Drive API For more information, refer to Amazon AppFlow support for Google Sheets. Refer to the Amazon Redshift Database Developer Guide for more details.
The S3 object path can reference a set of folders that have the same key prefix. Automate ingestion from a single data source With a auto-copy job, you can automate ingestion from a single data source by creating one job and specifying the path to the S3 objects that contain the data. You can drop auto-copy job using following command.
Solution demo To demonstrate the exact match filter solution, we have ingested an individual asset loaded from the TPC-DS tables and also created data product bundling of assets. Refer to the product documentation to learn more about how to set up metadata rules for subscription and publishing workflows.
There may even be someone on your team who built a personalized video recommender before and can help scope and estimate the project requirements using that past experience as a point of reference. An AI pilot project, even one that sounds simple, probably won’t be something you can demo quickly. AI doesn’t fit that model.
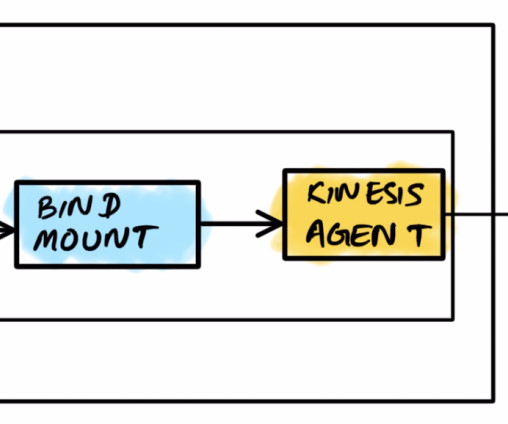
We also avoid the implementation details and packaging process of our test data generation application, referred to as the producer. log and publish them to a Kinesis Data Firehose delivery stream called kinesis-agent-demo : { "firehose.endpoint": "firehose.ap-southeast-2.amazonaws.com", southeast-2.amazonaws.com", southeast-2.amazonaws.com/producer:latest",
encounter_id : Unique number to refer to an encounter with a patient who has diabetes. In the Amazon Redshift Query Editor V2 , connect to serverless:rs-demo-wg , an Amazon Redshift Serverless instance created by the CloudFormation template. You can do this by connecting to serverless:rs-demo-wg as Federated user.
In this last installment, we’ll discuss a demo application that uses PySpark.ML For more context, this demo is based on concepts discussed in this blog post How to deploy ML models to production. In this demo, half of this training data is stored in HDFS and the other half is stored in an HBase table. Serving The Model .
AWS has invested in native service integration with Apache Hudi and published technical contents to enable you to use Apache Hudi with AWS Glue (for example, refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started ).
We use AWS Glue , a fully managed, serverless, ETL (extract, transform, and load) service, and the Google BigQuery Connector for AWS Glue (for more information, refer to Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors ). If you don’t have one, refer to Amazon Redshift Serverless. An S3 bucket.
Solution overview In this section, we present the solution architecture for the demo and explain the workflow. The historical application logs are stored in an S3 bucket for reference and for querying purposes. For this demo, MFA is not enabled. For additional details, refer to the Tableau licensing information.
To create your namespace and workgroup, refer to Creating a data warehouse with Amazon Redshift Serverless. For this exercise, name your workgroup sandbox and your namespace adx-demo. To configure Query Editor v2 for your AWS account, refer to Data load made easy and secure in Amazon Redshift using Query Editor V2.
Add a view that references a data lake table to a Redshift datashare When you create data lake tables that you intend to add to a datashare, the recommended and most common way to do this is to add a view to the datashare that references a data lake table or tables.
Refer to IAM Identity Center identity source tutorials for the IdP setup. For more details, refer to Creating a workgroup with a namespace. Refer to Authorization servers for more information about authorization servers in Okta. For more information, refer to the CreateTokenWithIAM API reference.
For additional information about roles, refer to Requirements for roles used to register locations. Refer to Registering an encrypted Amazon S3 location for guidance. For Target database , enter lf-demo-db. In the Athena query editor, run the following SELECT query on the shared table: SELECT * FROM "lf-demo-db"."consumer_iceberg"
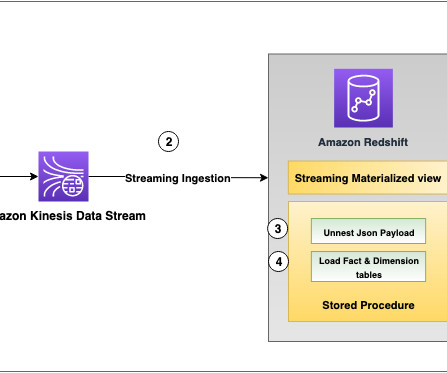
As shown in the following reference architecture, DynamoDB table data changes are streamed into Amazon Redshift through Kinesis Data Streams and Amazon Redshift streaming ingestion for near-real-time analytics dashboard visualization using Amazon QuickSight. For instructions, refer to Create a sample Amazon Redshift cluster.
For more information, refer to Amazon Redshift adds new AI capabilities, including Amazon Q, to boost efficiency and productivity. Refer to Managing IAM roles created for a cluster using the console for instructions. Set up an AWS Identity and Access Management (IAM) role as the default IAM role.
Preprocessing refers to mitigation methods applied to the training dataset before a model is trained on it. In-processing refers to mitigation techniques incorporated into the model training process itself. Request a Demo. Altering weights on rows of the data to achieve greater parity in assigned outcomes is one example.
Second, while OpenAI’s GPT-4 announcement last March demoed generating website code from a hand-drawn sketch, that capability wasn’t available until after the survey closed. Third, while roughing out the HTML and JavaScript for a simple website makes a great demo, that isn’t really the problem web designers need to solve.
Before proceeding with the demo, create a folder named custdata under the created S3 bucket. For Data stream name , enter demo-data-stream. Wait for successful creation of demo-data-stream and for it to be in Active status. Select the Kinesis data stream demo-data-stream. Choose Create data stream.
Refer to Setting up roles and users in Amazon OpenSearch Ingestion to get more details on roles and permissions required to use OpenSearch Ingestion. In the demo, you use the AWS Cloud9 EC2 instance profile’s credentials to sign requests sent to OpenSearch Ingestion. For this post, select Public access under Network.
Streaming data refers to data that is continuously generated from a variety of sources. For instructions, refer to the following: Generate the private key Generate a public key Store the private and public keys securely Assign the public key to a Snowflake user Verify the user’s public key fingerprint An S3 bucket for error logging.
This effect is referred to as operational transparency. Request a demo. The research participants also reported more willingness to pay for the services, a perception of higher quality, and a greater likelihood to use the site again. See DataRobot in Action. The post Humans and AI: Should We Describe AI as Autonomous?
For an active-active setup, refer to Create an active-active setup using MSK Replicator. However, for the purpose of the demo, we are using console producer and consumers, so our clients are already stopped. For more information, refer to What is Amazon MSK Replicator?
Accuracy — this refers to a subset of model performance indicators that measure a model’s aggregated errors in different ways. Speed — for model performance, speed refers to the time it takes to use a model to score a prediction. Request a demo. AI You Can Trust. The post How to Build Trust in AI appeared first on DataRobot.
Donna and other executive leaders were deeply involved in our strategy, vision, and execution, including participating in early product demos and weekly check-ins,” says Peterson, noting that their involvement was critical to maintaining focus and removing roadblocks to execution. “I
Bard Google’s code name for its chat-oriented search engine, based on their LaMDA model, and only demoed once in public. There’s a very important difference between these two almost identical sentences: in the first, “it” refers to the cup. In the second, “it” refers to the pitcher. These are questions we can’t not answer.
To learn more about semantic search and cross-modal search and experiment with a demo of the Compare Search Results tool, refer to Try semantic search with the Amazon OpenSearch Service vector engine. To learn more, refer to Byte-quantized vectors in OpenSearch.
If my explanation above is the correct interpretation of the high percentage, and if the statement refers to successfully deployed applications (i.e., A similarly high percentage of tabular data usage among data scientists was mentioned here.
Traditional batch ingestion and processing pipelines that involve operations such as data cleaning and joining with reference data are straightforward to create and cost-efficient to maintain. Solution overview For our example use case, streaming data is coming through Amazon Kinesis Data Streams , and reference data is managed in MySQL.
To learn more about auto-mounting of the Data Catalog in Amazon Redshift, refer to Querying the AWS Glue Data Catalog. For this post, we add full AWS Glue, Amazon Redshift, and Amazon S3 permissions for demo purposes. For more information, refer to Changing the default settings for your data lake.
If you don’t have one, refer to How do I create and activate a new AWS account? If you’re new to Amazon DataZone, refer to Getting started. To understand how to associate multiple accounts and consume the subscribed assets using Amazon Athena , refer to Working with associated accounts to publish and consume data.
Check every free trial and demo to make sure you have covered all your bases. This refers to everything from having a great SEO app, meta titles, descriptions, and social images. Then sign up and take free tours and demos to be sure your user experience matches your company vision. Some AI tools make it easier to develop them.
The challenge with this approach is that companies end up in what we refer to as the ‘digital trap. Although Young “talked to some people” before hiring the provider, he acknowledges that officials could have dug deeper and found people the company didn’t refer them to for references.
In recognition of the diverse workload that data scientists face, Cloudera’s library of Applied ML Prototypes (AMPs) provide Data Scientists with pre-built reference examples and end-to-end solutions, using some of the most cutting edge ML methods, for a variety of common data science projects.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content