This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Generative AI models can translate natural language questions into valid SQL queries, a capability known as text-to-SQL generation.
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machine learning models from malicious actors. Like many others, I’ve known for some time that machine learning models themselves could pose security risks. This is like a denial-of-service (DOS) attack on your model itself.
We will explore Icebergs concurrency model, examine common conflict scenarios, and provide practical implementation patterns of both automatic retry mechanisms and situations requiring custom conflict resolution logic for building resilient data pipelines. Generate new metadata files. Commit the metadata files to the catalog.
Introduction With the advent of RAG (Retrieval Augmented Generation) and Large Language Models (LLMs), knowledge-intensive tasks like Document Question Answering, have become a lot more efficient and robust without the immediate need to fine-tune a cost-expensive LLM to solve downstream tasks.
As explained in a previous post , with the advent of AI-based tools and intelligent document processing (IDP) systems, ECM tools can now go further by automating many processes that were once completely manual. That relieves users from having to fill out such fields themselves to classify documents, which they often don’t do well, if at all.
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
Content includes reports, documents, articles, presentations, visualizations, video, and audio representations of the insights and knowledge that have been extracted from data. Datasphere provides full-spectrum data governance: metadata management, data catalogs, data privacy, data quality, and data lineage (provenance) tracking.
Metadata management is key to wringing all the value possible from data assets. What Is Metadata? Analyst firm Gartner defines metadata as “information that describes various facets of an information asset to improve its usability throughout its life cycle. It is metadata that turns information into an asset.”.
If the output of a model can’t be owned by a human, who (or what) is responsible if that output infringes existing copyright? In an article in The New Yorker , Jaron Lanier introduces the idea of data dignity, which implicitly distinguishes between training a model and generating output using a model.
This is accomplished through tags, annotations, and metadata (TAM). So, there must be a strategy regarding who, what, when, where, why, and how is the organization’s content to be indexed, stored, accessed, delivered, used, and documented. Smart content includes labeled (tagged, annotated) metadata (TAM).
And yeah, the real-world relationships among the entities represented in the data had to be fudged a bit to fit in the counterintuitive model of tabular data, but, in trade, you get reliability and speed. Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter. Graph Databases vs Relational Databases.
In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer. This ensures that each change is tracked and reversible, enhancing data governance and auditability.
While there has been a lot of talk about big data over the years, the real hero in unlocking the value of enterprise data is metadata , or the data about the data. And to truly understand it , you need to be able to create and sustain an enterprise-wide view of and easy access to underlying metadata. This isn’t an easy task.
Generative artificial intelligence ( genAI ) and in particular large language models ( LLMs ) are changing the way companies develop and deliver software. The commodity effect of LLMs over specialized ML models One of the most notable transformations generative AI has brought to IT is the democratization of AI capabilities.
Generative AI models are trained on large repositories of information and media. They are then able to take in prompts and produce outputs based on the statistical weights of the pretrained models of those corpora. The newest Answers release is again built with an open source model—in this case, Llama 3.
They consist of: A data sample of the documents you want to index. A pipeline of processors that apply transforms on ingested documents. An index constructed from the processed documents. This template requires us to select a text embedding model. Ingest flows are created to enrich data as its added to an index.
What is Data Modeling? Data modeling is a process that enables organizations to discover, design, visualize, standardize and deploy high-quality data assets through an intuitive, graphical interface. Data models provide visualization, create additional metadata and standardize data design across the enterprise.
Teams need to urgently respond to everything from massive changes in workforce access and management to what-if planning for a variety of grim scenarios, in addition to building and documenting new applications and providing fast, accurate access to data for smart decision-making. Enterprise Architecture & Business Process Modeling.
Users discuss how they are putting erwin’s data modeling, enterprise architecture, business process modeling, and data intelligences solutions to work. IT Central Station members using erwin solutions are realizing the benefits of enterprise modeling and data intelligence. They have documented 200 business processes in this way.
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documentingmetadata. But in many scenarios, it seems that the underlying driver of metadata collection projects is that it’s just something you do for data governance.
Data quality for AI needs to cover bias detection, infringement prevention, skew detection in data for model features, and noise detection. Not all columns are equal, so you need to prioritize cleaning data features that matter to your model, and your business outcomes. asks Friedman.
Often these enterprises are heavily regulated, so they need a well-defined data integration model that will help avoid data discrepancies and remove barriers to enterprise business intelligence and other meaningful use. The post Metadata Management, Data Governance and Automation appeared first on erwin, Inc.
They realized that the search results would probably not provide an answer to my question, but the results would simply list websites that included my words on the page or in the metadata tags: “Texas”, “Cows”, “How”, etc. The semantic layer bridges the gaps between the data cloud, the decision-makers, and the data science modelers.
These strategies, such as investing in AI-powered cleansing tools and adopting federated governance models, not only address the current data quality challenges but also pave the way for improved decision-making, operational efficiency and customer satisfaction. Data fabric Metadata-rich integration layer across distributed systems.
erwin has once again been positioned as a Leader in the Gartner “2020 Magic Quadrant for Metadata Management Solutions.”. The post erwin Positioned as a Leader in Gartner’s 2020 Magic Quadrant for Metadata Management Solutions for Second Year in a Row appeared first on erwin, Inc.
Understanding the benefits of data modeling is more important than ever. Data modeling is the process of creating a data model to communicate data requirements, documenting data structures and entity types. In this post: What Is a Data Model? Why Is Data Modeling Important? What Is a Data Model?
Data modeling supports collaboration among business stakeholders – with different job roles and skills – to coordinate with business objectives. What, then, should users look for in a data modeling product to support their governance/intelligence requirements in the data-driven enterprise? Nine Steps to Data Modeling.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. There is no GitHub for data, though we are starting to see version control projects for machine learning models, such as DVC. Automation is more than model building. Toward a sustainable ML practice.
While generative AI has been around for several years , the arrival of ChatGPT (a conversational AI tool for all business occasions, built and trained from large language models) has been like a brilliant torch brought into a dark room, illuminating many previously unseen opportunities. So, if you have 1 trillion data points (g.,
Shockingly, a lot of organizations, even today, manage this through, either homemade tools or documents, checklists, Excel files, custom-made databases and so on and so forth. Traditionally, these are manually documented, monitored and managed. Processes produce, process and consume data –information captured in the metadata layer.
The role of data modeling (DM) has expanded to support enterprise data management, including data governance and intelligence efforts. Metadata management is the key to managing and governing your data and drawing intelligence from it. Types of Data Models: Conceptual, Logical and Physical.
But even with the “need for speed” to market, new applications must be modeled and documented for compliance, transparency and stakeholder literacy. With all these diverse metadata sources, it is difficult to understand the complicated web they form much less get a simple visual flow of data lineage and impact analysis.
Data visualization enables you to: Make sense of the distributional characteristics of variables Easily identify data entry issues Choose suitable variables for data analysis Assess the outcome of predictive models Communicate the results to those interested. Choosing the right data storage model for your requirements is paramount.
This enables companies to directly access key metadata (tags, governance policies, and data quality indicators) from over 100 data sources in Data Cloud, it said. Additional to that, we are also allowing the metadata inside of Alation to be read into these agents.”
It’s important to understand that ChatGPT is not actually a language model. It’s a convenient user interface built around one specific language model, GPT-3.5, is one of a class of language models that are sometimes called “large language models” (LLMs)—though that term isn’t very helpful. with specialized training.
Generative AI (GenAI) models, such as GPT-4, offer a promising solution, potentially reducing the dependency on labor-intensive annotation. 70b-Instruct (via databricks), against state-of-the-art (SOTA) NER models like BioLinkBERT (trained on BioRED) and BERT (trained on AIDA). We benchmarked GPT-4o 3 and Llama-3.1-70b-Instruct
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. The solution integrates data in three tiers.
Almost 70 percent of CEOs say they expect their companies to change their business models in the next three years, and 62 percent report they have management initiatives or transformation programs underway to make their businesses more digital, according to Gartner. A change in the source-column header may impact 1,500 design mappings.
erwin positioned as a Leader in Gartner’s “2019 Magic Quadrant for Metadata Management Solutions”. We were excited to announce earlier today that erwin was named as a Leader in the @Gartner _inc “2019 Magic Quadrant for Metadata Management Solutions.”. The Gartner document is available upon request from www.erwin.com/GartnerMMMQleader.
It documents your data assets from end to end for business understanding and clear data lineage with traceability. Data governance and EA also provide many of the same benefits of enterprise architecture or business process modeling projects: reducing risk, optimizing operations, and increasing the use of trusted data.
In the Create function pane, provide the following information: For Select a template , choose v2 Programming Model. For Programming Model , choose the HTTP trigger template. Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. choose Next.
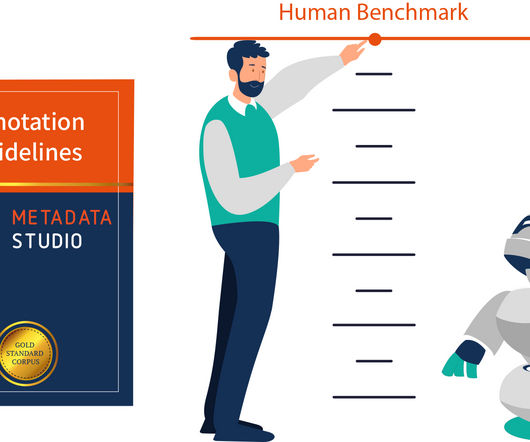
This data can then be easily analyzed to provide insights or used to train machine learning models. Ontotext’s approach is to optimize models and algorithms through human contribution and benchmarking in order to create better and more accurate AI. What Are The Benefits Of Using Ontotext Metadata Studio?
However, more than 50 percent say they have deployed metadata management, data analytics, and data quality solutions. erwin Named a Leader in Gartner 2019 Metadata Management Magic Quadrant. All of these factors have an impact on a well-defined data integration model. Stop Wasting Your Time.
We also detail how the feature works and what criteria was applied for the model and prompt selection while building on Amazon Bedrock. Data consumers need detailed descriptions of the business context of a data asset and documentation about its recommended use cases to quickly identify the relevant data for their intended use case.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content