This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. While RAG leverages nearest neighbor metrics based on the relative similarity of texts, graphs allow for better recall of less intuitive connections. at Facebook—both from 2020.
6) Data Quality Metrics Examples. Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose.
For instance, records may be cleaned up to create unique, non-duplicated transaction logs, master customer records, and cross-reference tables. Finally, the challenge we are addressing in this document – is how to prove the data is correct at each layer.? How do you ensure data quality in every layer?
What this meant was the emergence of a new stack for ML-powered app development, often referred to as MLOps. Business value : Once we have a rubric for evaluating our systems, how do we tie our macro-level business value metrics to our micro-level LLM evaluations? Wrong document retrieval : Debug chunking strategy, retrieval method.
To win in business you need to follow this process: Metrics > Hypothesis > Experiment > Act. We are far too enamored with data collection and reporting the standard metrics we love because others love them because someone else said they were nice so many years ago. That metric is tied to a KPI.
Understanding and tracking the right software delivery metrics is essential to inform strategic decisions that drive continuous improvement. Documentation and diagrams transform abstract discussions into something tangible. Complex ideas that remain purely verbal often get lost or misunderstood.
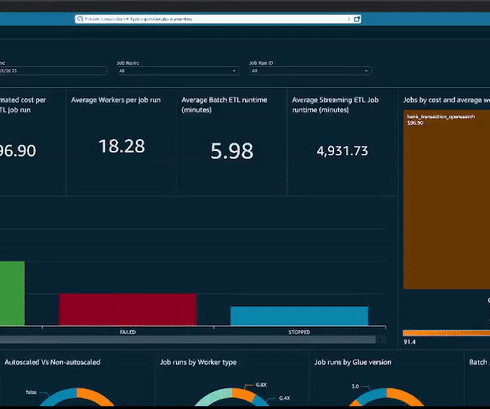
In this post, we explore how to combine AWS Glue usage information and metrics with centralized reporting and visualization using QuickSight. You have metrics available per job run within the AWS Glue console, but they don’t cover all available AWS Glue job metrics, and the visuals aren’t as interactive compared to the QuickSight dashboard.
Whether youre a data analyst seeking a specific metric or a data steward validating metadata compliance, this update delivers a more precise, governed, and intuitive search experience. This reduces time-to-insight and makes sure the right metric is used in reporting.
For more details, refer to the BladeBridge Analyzer Demo. Refer to this BladeBridge documentation to get more details on SQL and expression conversion. If you encounter any challenges or have additional requirements, refer to the BladeBridge community support portal or reach out to the BladeBridge team for further assistance.
One key advantage of opting for managed Kafka services is the delegation of responsibility for broker and operational metrics, allowing users to focus solely on metrics specific to applications. With Kafka, monitoring typically involves various metrics that are related to topics, partitions, brokers and consumer groups.
dbt helps manage data transformation by enabling teams to deploy analytics code following software engineering best practices such as modularity, continuous integration and continuous deployment (CI/CD), and embedded documentation. To add documentation: Run dbt docs generate to generate the documentation for your project.
In your Google Cloud project, youve enabled the following APIs: Google Analytics API Google Analytics Admin API Google Analytics Data API Google Sheets API Google Drive API For more information, refer to Amazon AppFlow support for Google Sheets. Refer to the Amazon Redshift Database Developer Guide for more details.
Now that we have covered AI agents, we can see that agentic AI refers to the concept of AI systems being capable of independent action and goal achievement, while AI agents are the individual components within this system that perform each specific task. Do you know what the user agent does in this scenario?
Search applications include ecommerce websites, document repository search, customer support call centers, customer relationship management, matchmaking for gaming, and application search. Before FMs, search engines used a word-frequency scoring system called term frequency/inverse document frequency (TF/IDF).
The S3 object path can reference a set of folders that have the same key prefix. It shows the aggregate metrics of the files that have been processed by a auto-copy job. In this example, we have multiple files that are being loaded on a daily basis containing the sales transactions across all the stores in the US.
A financial Key Performance Indicator (KPI) or metric is a quantifiable measure that a company uses to gauge its financial performance over time. These three statements are data rich and full of financial metrics. The Fundamental Finance KPIs and Metrics – Cash Flow. What is a Financial KPI? Current Ratio. View Guide Now.
For more details about OR1 instances, refer to Amazon OpenSearch Service Under the Hood: OpenSearch Optimized Instances (OR1). With the OpenSearch Benchmark tool, we conduct experiments to assess various performance metrics, such as indexing throughput, search latency, and overall cluster efficiency.
You can use the query from the Amazon Redshift documentation and add the same start and end times. Our elapsed time analysis demonstrates how each configuration achieved its performance objectives, as shown by the average consumption metrics for each endpoint, as shown in the following screenshot.
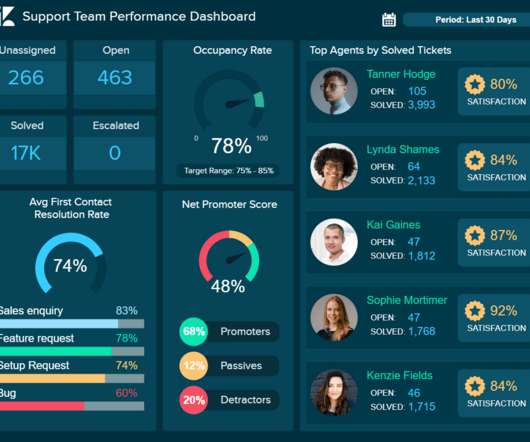
A report is a document that presents relevant business information in an organized and understandable format. This insightful report displays relevant metrics such as the top-performing agents, net promoter score, and first contact resolution rate, among others. This reporting type refers to the direction in which a report travels.
dbt lets data engineers quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, continuous integration and continuous delivery (CI/CD), and documentation. The gold model joins the technical logs with billing data and organizes the metrics per business unit.
RAG is a machine learning (ML) architecture that uses external documents (like Wikipedia) to augment its knowledge and achieve state-of-the-art results on knowledge-intensive tasks. Each service implements k-nearest neighbor (k-NN) or approximate nearest neighbor (ANN) algorithms and distance metrics to calculate similarity.
Another example is an AI-driven observability and monitoring solution where FMs monitor real-time internal metrics of a system and produces alerts. When the model finds an anomaly or abnormal metric value, it should immediately produce an alert and notify the operator. For more information, refer to Dynamic Tables.
It comes in two modes: document-only and bi-encoder. For more details about these two terms, see Improving document retrieval with sparse semantic encoders. Simply put, in document-only mode, term expansion is performed only during document ingestion. We care more about the recall metric.
Adoption of Copilot so far tends to be in what he refers to as pockets, which matches how McKinsey reports that most gen AI deployments are happening in specific departments: marketing and sales, service and support, and product development. It took them six months to do this work previously and now it takes them a week,” he says.
For instructions on how to set this up, refer to Amazon DataZone data products. Data producers can review the metadata, including document links and account IDs, to determine if the request meets compliance and workflow requirements before granting access, as shown in the following screenshot.
Now that you’re sold on the power of data analytics in addition to data-driven BI, it’s time to take your journey a step further by exploring how to effectively communicate vital metrics and insights in a concise, inspiring, and accessible format through the power of visualization. back on every dollar spent.
Lexical search In lexical search, the search engine compares the words in the search query to the words in the documents, matching word for word. It similarly codes the query as a vector and then uses a distance metric to find nearby vectors in the multi-dimensional space to find matches.
For other ingestion methods, see documentation. sts_role_arn – Provide the ARN for the IAM role that has permissions for the Amazon Document DB cluster, S3 bucket, and OpenSearch Service domain. For more information, refer to Securing Amazon OpenSearch Ingestion pipelines within a VPC. Create the OpenSearch Ingestion pipeline.
SaaS is less robust and less secure than on-premises applications: Despite some SaaS-based teething problems or technical issues reported by the likes of Google, these occurrences are incredibly rare with software as a service applications – and there hasn’t been one major compromise of a SaaS operation documented to date.
Data visualization methods refer to the creation of graphical representations of information. While pie charts have received a bad rep in recent years, we feel that they form a useful visualization tool that serves up important metrics in an easy-to-follow format. c) Pie charts. d) Gauge charts. d) Area chart. click to enlarge**.
Refer to the Configuration reference in the User Guide for detailed configuration values. To learn more about Setup and Teardown tasks, refer to the Apache Airflow documentation. The Cluster Activity page gathers useful data to monitor your cluster’s live and historical metrics. Set up a new Apache Airflow v2.7.2
The data, fetched from the Kubernetes Metric Server, feeds into statistical models that VPA constructs in order to build recommendations. For a deep-dive into the functionality, refer to the VPA Github repo. Real-time metric data is fetched from the Kubernetes Metric Server.
Refer to plugin changelog for released features and versions. For more information about role-based access, refer to Role-based access control (RBAC). Therefore, local Grafana could be an option if you need earlier access for the latest features.
We’ve got siloed expertise that would make medieval castle builders proud, documentation so sparse it could win a minimalist art competition, and a reliance on “data heroes” that would make Marvel envious. Use quantitative metrics where possible and gather qualitative feedback from data users.
” I, thankfully, learned this early in my career, at a time when I could still refer to myself as a software developer. In the past they understood the APIs of TensorFlow and Torch to build models by hand; today they are fluent in the autoML vendor’s APIs to train models, and they understand how to review the metrics.
In the simplest of terms, the latter refers to a system that examines large bodies of data with the goal of uncovering trends, patterns, correlations and other helpful information. The collection and use of relevant metrics can, therefore, potentially boost your chances of engaging new prospects while keeping existing customers satisfied.
Add a sheet to document your changes. This is also a good place to keep lookup tables, references, and links to sources. Solution : Either use a nested IF() function and reference a lookup table or use the SWITCH() function. The same metric is broken out into separate columns. Here’s an example : 2. Spreadsheet example.
Data consumers need detailed descriptions of the business context of a data asset and documentation about its recommended use cases to quickly identify the relevant data for their intended use case. This reduces the need for time-consuming manual documentation, making data more easily discoverable and comprehensible.
For more details, refer to the What’s New Post. The company’s business analysts want to generate metrics to identify ticket movement over time, success rates for sellers, and the best-selling events, venues, and seasons. They would like to get these metrics in near-real time using a zero-ETL integration.
We refer to this concept as outside-in data movement. For more details on data tiers within OpenSearch Service, refer to Choose the right storage tier for your needs in Amazon OpenSearch Service. For a list of supported metrics, refer to Monitoring pipeline metrics. Let’s look at an example use case. Example Corp.
If your updates to a dataset triggers multiple subsequent DAGs, then you can use the Airflow metric max_active_tasks_per_dag to control the parallelism of the consumer DAG and reduce the chance of overloading the system. For detailed release documentation with sample code, visit the Apache Airflow v2.4.0 Release Notes. Release Notes.
First, many LLM use cases rely on enterprise knowledge that needs to be drawn from unstructured data such as documents, transcripts, and images, in addition to structured data from data warehouses. For detailed implementation guidance, refer to Unstructured data management and governance using AWS AI/ML and analytics services.
White label reporting refers to the tools and features used by businesses and agencies to generate customizable interactive reports and dashboards that match their branding. In this regard, implementing white label reporting practices and tools can help boost this mentality while giving a professional look to all relevant company documents.
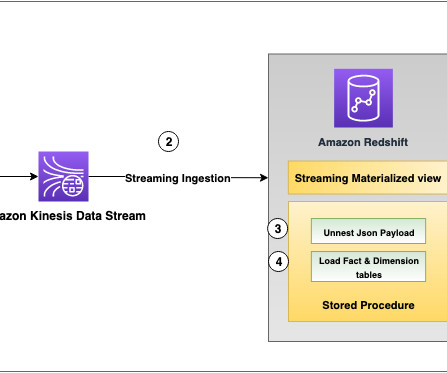
We also walk through using PartiQL in Amazon Redshift to unnest nested JSON documents and build fact and dimension tables that are used in your data warehouse refresh. Use a combination of a PartiQL statement and dot notation to unnest the JSON document into data columns of a staging table in Amazon Redshift. Open your table.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























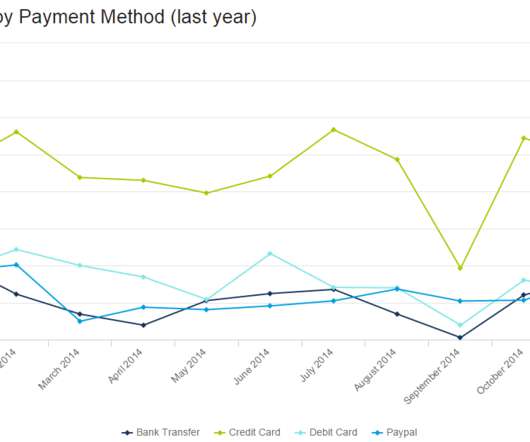


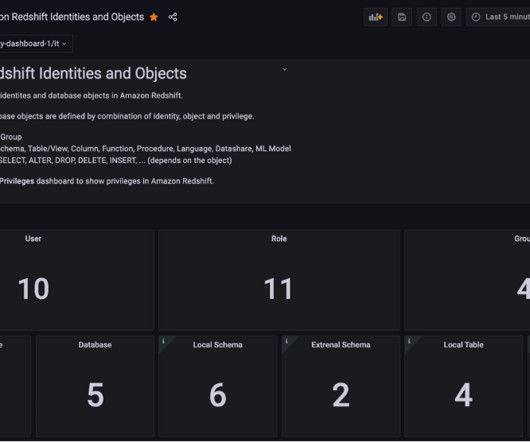



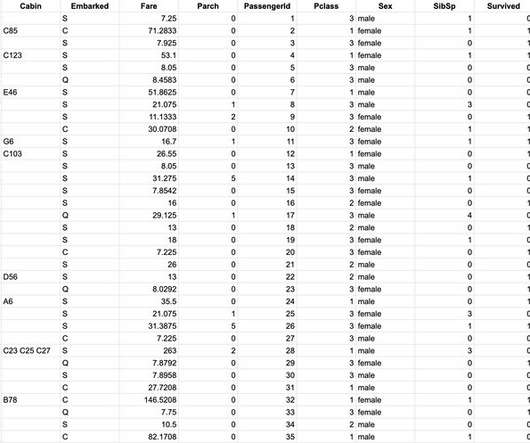





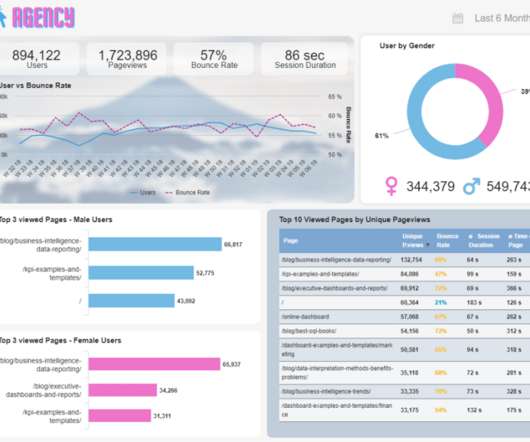








Let's personalize your content