This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
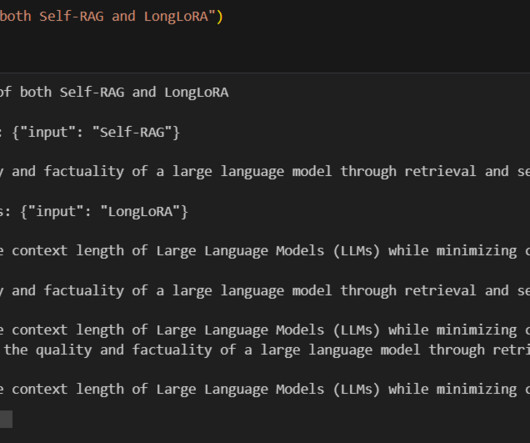
Introduction This article aims to create an AI-powered RAG and Streamlit chatbot that can answer users questions based on custom documents. Users can upload documents, and the chatbot can answer questions by referring to those documents.
Introduction LlamaParse is a document parsing library developed by Llama Index to efficiently and effectively parse documents such as PDFs, PPTs, etc. The nature of […] The post Simplifying Document Parsing: Extracting Embedded Objects with LlamaParse appeared first on Analytics Vidhya.
To address this challenge, Meta AI has introduced Nougat, or “Neural Optical Understanding for Academic Documents,”, a state-of-the-art Transformer-based model designed to transcribe scientific PDFs into […] The post Enhancing Scientific Document Processing with Nougat appeared first on Analytics Vidhya.
Introduction Large Language Models like langchain and deep lake have come a long way in Document Q&A and information retrieval. These models know a lot about the world, but sometimes, they struggle to know when they don’t know something. However, a […] The post Ask your Documents with Langchain and Deep Lake!
Introduction DocVQA (Document Visual Question Answering) is a research field in computer vision and natural language processing that focuses on developing algorithms to answer questions related to the content of a document, like a scanned document or an image of a text document.
Introduction LLMs (large language models) are becoming increasingly relevant in various businesses and organizations. Integrating with various tools allows us to build LLM applications that can automate tasks, provide […] The post What are Langchain Document Loaders? appeared first on Analytics Vidhya.
RAG is replacing the traditional search-based approaches and creating a chat with a document environment. The biggest hurdle in RAG is to retrieve the right document. Only when we get […] The post Enhancing RAG with Hypothetical Document Embedding appeared first on Analytics Vidhya.
Introduction In the world of information retrieval, where oceans of text data await exploration, the ability to pinpoint relevant documents efficiently is invaluable. Traditional keyword-based search has its limitations, especially when dealing with personal and confidential data.
Introduction A specific category of artificial intelligence models known as large language models (LLMs) is designed to understand and generate human-like text. For example, OpenAI’s GPT-3 model has 175 billion parameters. The term “large” is often quantified by the number of parameters they possess.
JPMorgan has unveiled its latest AI – DocLLM, an extension to large language models (LLMs) designed for comprehensive document understanding. In a bid to transform the landscape of generative pre-training, DocLLM goes beyond traditional models by incorporating spatial layout information.
Enter Multi-Document Agentic RAG – a powerful approach that combines Retrieval-Augmented Generation (RAG) with agent-based systems to create AI that can reason across multiple documents.
Google’s researchers have unveiled a groundbreaking achievement – Large Language Models (LLMs) can now harness Machine Learning (ML) models and APIs with the mere aid of tool documentation.
Introduction Training and inference with large neural models are computationally expensive and time-consuming. While new tasks and models emerge so often for many application domains, the underlying documents being modeled stay mostly unaltered. In light of this, to improve the efficiency of future […].
OpenAI has released the first draft of its Model Spec, a document outlining the desired behavior and guidelines for its AI models. This move is part of the company’s ongoing commitment to improving model behavior and engaging in a public conversation about the ethical and practical considerations of AI development.
Introduction In my previous blog post, Building Multi-Document Agentic RAG using LLamaIndex, I demonstrated how to create a retrieval-augmented generation (RAG) system that could handle and query across three documents using LLamaIndex.
A researcher within Google leaked a document on a public Discord server recently. There is much controversy surrounding the document’s authenticity. But what interests people most is […] The post Google Afraid of Open-Source Community Outpacing Tech Giants in Language Model Race appeared first on Analytics Vidhya.
Your companys AI assistant confidently tells a customer its processed their urgent withdrawal requestexcept it hasnt, because it misinterpreted the API documentation. This fueled a belief that simply making models bigger would solve deeper issues like accuracy, understanding, and reasoning. Development velocity grinds to a halt.
This article will provide you with a hands-on implementation on how to deploy an ML model in the Azure cloud. If you are new to Azure machine learning, I would recommend you to go through the Microsoft documentation that has been provided in the […].
Imagine an AI that can write poetry, draft legal documents, or summarize complex research papersbut how do we truly measure its effectiveness? As Large Language Models (LLMs) blur the lines between human and machine-generated content, the quest for reliable evaluation metrics has become more critical than ever.
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., Split each document into chunks.
With the current models, every time you generate code, you’re likely to get something different. Another limit is that the model itself can’t change—but models change all the time, and those changes aren’t under the programmer’s control. An updated model is likely to produce completely different source code.
Introduction A highly effective method in machine learning and natural language processing is topic modeling. A corpus of text is an example of a collection of documents. This technique involves finding abstract subjects that appear there.
Introduction With the advent of RAG (Retrieval Augmented Generation) and Large Language Models (LLMs), knowledge-intensive tasks like Document Question Answering, have become a lot more efficient and robust without the immediate need to fine-tune a cost-expensive LLM to solve downstream tasks.
Overview Learn about Information Retrieval (IR), Vector Space Models (VSM), and Mean Average Precision (MAP) Create a project on Information Retrieval using word2vec based. The post Information Retrieval using word2vec based Vector Space Model appeared first on Analytics Vidhya.
Combining retrieval mechanisms with language models to create contextually aware responses is fascinating. Evaluation ensures the RAG pipeline retrieves relevant documents, generates […] The post A Guide to Evaluate RAG Pipelines with LlamaIndex and TRULens appeared first on Analytics Vidhya.
Introduction In the previous article, we experimented with Cohere’s Command-R model and Rerank model to generate responses and rerank doc sources. We have implemented a simple RAG pipeline using them to generate responses to user’s questions on ingested documents.
But even though technologies like Building Information Modelling (BIM) have finally introduced symbolic representation, in many ways, AECO still clings to outdated, analog practices and documents. Here, one of the challenges involves digitizing the national specifics of regulatory documents and building codes in multiple languages.
Introduction Microsoft Research has introduced a groundbreaking Document AI model called Universal Document Processing (UDOP), which represents a significant leap in AI capabilities.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
In this hands-on guide, we explore creating a sophisticated Q&A assistant powered by LLamA2 and LLamAIndex, leveraging state-of-the-art language models and indexing frameworks to navigate a sea of PDF documents effortlessly.
Meanwhile, in December, OpenAIs new O3 model, an agentic model not yet available to the public, scored 72% on the same test. Were developing our own AI models customized to improve code understanding on rare platforms, he adds. That adds up to millions of documents a month that need to be processed.
Introduction Before the large language models era, extracting invoices was a tedious task. For invoice extraction, one has to gather data, build a document search machine learning model, model fine-tuning etc. The introduction of Generative AI took all of us by storm and many things were simplified using the LLM model.
This new artificial intelligence (AI) model has recently emerged and is causing quite a stir in the tech community. This enigmatic model has been released without official documentation, leading to speculation about its origins and capabilities. Introduction Have you heard about GPT2-chatbot? It has set the whole town abuzz!
These models can understand and generate human-like text, enabling applications like chatbots and document summarization. Introduction to Ludwig The development of Natural Language Machines (NLP) and Artificial Intelligence (AI) has significantly impacted the field.
Introduction The field of artificial intelligence has seen remarkable advancements in recent years, particularly in the area of large language models. LLMs can generate human-like text, summarize documents, and write software code.
Build toward intelligent document management Most enterprises have document management systems to extract information from PDFs, word processing files, and scanned paper documents, where document structure and the required information arent complex.
Introduction Question and answering on custom data is one of the most sought-after use cases of Large Language Models. Human-like conversational skills of LLMs combined with vector retrieval methods make it much easier to extract answers from large documents.
Intelligent document processing (IDP) is changing the dynamic of a longstanding enterprise content management problem: dealing with unstructured content. The ability to effectively wrangle all that data can have a profound, positive impact on numerous document-intensive processes across enterprises. Not so with unstructured content.
As explained in a previous post , with the advent of AI-based tools and intelligent document processing (IDP) systems, ECM tools can now go further by automating many processes that were once completely manual. That relieves users from having to fill out such fields themselves to classify documents, which they often don’t do well, if at all.
It would have been very difficult to develop the expertise to build and train a model, and much more effective to work with a company that already has that expertise. Think about how the answers to those questions affect your business model. This data goes to our compensation model, which is designed to be revenue-neutral.
The adaptability of transformers makes these models invaluable for handling various document formats. Extracting critical information from PDFs is vital today, and transformers offer an efficient solution for automating PDF summarization. Applications span industries like law, finance, and academia.
Throughout this article, well explore real-world examples of LLM application development and then consolidate what weve learned into a set of first principlescovering areas like nondeterminism, evaluation approaches, and iteration cyclesthat can guide your work regardless of which models or frameworks you choose. Which multiagent frameworks?
Nate Melby, CIO of Dairyland Power Cooperative, says the Midwestern utility has been churning out large language models (LLMs) that not only automate document summarization but also help manage power grids during storms, for example. Only 13% plan to build a model from scratch.
If the output of a model can’t be owned by a human, who (or what) is responsible if that output infringes existing copyright? In an article in The New Yorker , Jaron Lanier introduces the idea of data dignity, which implicitly distinguishes between training a model and generating output using a model.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content