This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Although traditional scaling primarily responds to query queue times, the new AI-driven scaling and optimization feature offers a more sophisticated approach by considering multiple factors including query complexity and data volume. Consider using AI-driven scaling and optimization if your current workload requires 32 to 512 base RPUs.
Introduction Building and optimizing Retrieval-Augmented Generation (RAG) pipelines has been a rewarding experience. Evaluation ensures the RAG pipeline retrieves relevant documents, generates […] The post A Guide to Evaluate RAG Pipelines with LlamaIndex and TRULens appeared first on Analytics Vidhya.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. One more embellishment is to use a graph neural network (GNN) trained on the documents. Chunk your documents from unstructured data sources, as usual in GraphRAG. at Facebook—both from 2020.
Introduction Vector streaming in EmbedAnything is being introduced, a feature designed to optimize large-scale document embedding. Enabling asynchronous chunking and embedding using Rust’s concurrency reduces memory usage and speeds up the process.
Documents are the backbone of enterprise operations, but they are also a common source of inefficiency. From buried insights to manual handoffs, document-based workflows can quietly stall decision-making and drain resources. So how do you identify where to start and how to succeed?
Build toward intelligent document management Most enterprises have document management systems to extract information from PDFs, word processing files, and scanned paper documents, where document structure and the required information arent complex.
One study by Think With Google shows that marketing leaders are 130% as likely to have a documented data strategy. Optical Character Recognition, or OCR, is a technology for reading documents and extracting data. Optical Character Recognition, or OCR, is a technology for reading documents and extracting data.
And because these are our lawyers working on our documents, we have a historical record of what they typically do. We get a lot of documents from 20,000 customers, in all sorts of formats, says Brian Halpin, the companys senior managing director of automation. That adds up to millions of documents a month that need to be processed.
MongoDB was founded in 2007 and has established itself as one of the most prominent NoSQL database providers with its document-oriented database and associated cloud services. The launch of MongoDB 8.0 highlighted the recent advances the company has made in terms of performance, security, availability and resilience.
The game-changing potential of artificial intelligence (AI) and machine learning is well-documented. The optimal level of disclosure to AI stakeholders. Any organization that is considering adopting AI at their organization must first be willing to trust in AI technology. Why your organization’s values should be built into your AI.
Luckily, there are a few analytics optimization strategies you can use to make life easy on your end. Helps you to determine areas of abnormal losses and profits to optimize your trading algorithm. The post DirectX Visualization Optimizes Analytics Algorithmic Traders appeared first on SmartData Collective.
Amazon OpenSearch Service introduced the OpenSearch Optimized Instances (OR1) , deliver price-performance improvement over existing instances. For more details about OR1 instances, refer to Amazon OpenSearch Service Under the Hood: OpenSearch Optimized Instances (OR1). OR1 instances use a local and a remote store.
Key concepts To understand the value of RFS and how it works, let’s look at a few key concepts in OpenSearch (and the same in Elasticsearch): OpenSearch index : An OpenSearch index is a logical container that stores and manages a collection of related documents. to OpenSearch 2.x),
This makes sure your data models are well-documented, versioned, and straightforward to manage within a collaborative environment. Cost management and optimization – Because Athena charges based on the amount of data scanned by each query, cost optimization is critical.
In this post, we examine the OR1 instance type, an OpenSearch optimized instance introduced on November 29, 2023. We optimized the mapping to avoid any unnecessary indexing activity and use the flat_object field type to avoid field mapping explosion. KiB and the bulk size is 4,000 documents per bulk, which makes approximately 6.26
Analytics is especially important for companies trying to optimize their online presence. Website optimization is absolutely vital for any brand striving to do business online. Website optimization has been a key part of a business’s strategy since the late 1990s. Optimize for mobile. Have a call to action.
Any scenario in which a student is looking for information that the corpus of documents can answer. Wrong document retrieval : Debug chunking strategy, retrieval method. Slow response/high cost : Optimize model usage or retrieval efficiency. In what scenarios do you see them using the application? How will you measure success?
Optimizing GenAI Apps with RAG—Pure Storage + NVIDIA for the Win! document, image, video, audio clip) is reduced (transformed) to a condensed vector representation using deep neural networks. One of the most popular techniques associated with generative AI (GenAI) this past year has been retrieval-augmented generation (RAG).
Surveys and reports have documented that the strong improvement in call center staff EX is a source of significant value to the entire organization. Not only is the CX amplified, but so is the EX (Employee Experience). When the Voice of the Customer talks, the modern AI-powered Call Center listens and responds.
The power of AI operations (AIOps) and ServiceOps, including BMC Helix Discovery , can transform how you optimize IT operations (ITOps), change management, and service delivery. New migrations and continuous features were being deployed, and the team was unable to prioritize process optimization and noise reduction efforts.
Amazon OpenSearch Service recently introduced the OpenSearch Optimized Instance family (OR1), which delivers up to 30% price-performance improvement over existing memory optimized instances in internal benchmarks, and uses Amazon Simple Storage Service (Amazon S3) to provide 11 9s of durability.
However, that is only the case if they are properly maintained and optimized for speed. There are a lot of resources that can help optimize the processing speed of their computers, but they need to know how to use them appropriately. You may do so for documents, but your unused applications need to be uninstalled.
We built this AMP for two reasons: To add an AI application prototype to our AMP catalog that can handle both full document summarization and raw text block summarization. AMPs are all about helping you quickly build performant AI applications. More on AMPs can be found here.
For agent-based solutions, see the agent-specific documentation for integration with OpenSearch Ingestion, such as Using an OpenSearch Ingestion pipeline with Fluent Bit. This can help you optimize long-term cost for high-throughput use cases. This solution focuses on using CloudWatch logs as a data source for log aggregation.
Though loosely applied, agentic AI generally refers to granting AI agents more autonomy to optimize tasks and chain together increasingly complex actions. Agentic AI can make sales more effective by handling lead scoring, assisting with customer segmentation, and optimizing targeted outreach, he says.
The collaboration of these systems established a comprehensive digital ecosystem for the companys commercial operations, ensuring every aspect of the marketing and sales journey was data-informed and optimized. The following diagram shows the relationships between the key systems.
Search applications include ecommerce websites, document repository search, customer support call centers, customer relationship management, matchmaking for gaming, and application search. Before FMs, search engines used a word-frequency scoring system called term frequency/inverse document frequency (TF/IDF).
Versioning and documentation. And without proper documentation practices, users can accidentally deploy an outdated or vulnerable version of the API. Documentation should be thorough and consistent, including clearly stated input parameters, expected responses and security requirements.
dbt helps manage data transformation by enabling teams to deploy analytics code following software engineering best practices such as modularity, continuous integration and continuous deployment (CI/CD), and embedded documentation. To add documentation: Run dbt docs generate to generate the documentation for your project.
These large-scale, asset-driven enterprises generate an overwhelming amount of information, from engineering drawings and standard operating procedures (SOPs) to compliance documentation and quality assurance data. Document management and accessibility are vital for teamsworking on construction projects in the energy sector.
It’s a full-fledged platform … pre-engineered with the governance we needed, and cost-optimized. He estimates 40 generative AI production use cases currently, such as drafting and emailing documents, translation, document summarization, and research on clients.
However, inaccurate retrieval can lead to sub-optimal responses. Introduction The Retrieval-Augmented Generation approach combines LLMs with a retrieval system to improve response quality.
Each index shard may occupy different sizes based on its number of documents. In addition to the number of documents, one of the important factors that determine the size of the index shard is the compression strategy used for an index. As part of an indexing operation, the ingested documents are stored as immutable segments.
Data is typically organized into project-specific schemas optimized for business intelligence (BI) applications, advanced analytics, and machine learning. Finally, the challenge we are addressing in this document – is how to prove the data is correct at each layer.? How do you ensure data quality in every layer?
LLM-driven API mapping automates this alignment process based on API attributes and documentation. Learn how to automate and reclaim valuable time with generative AI-powered assistants The post AI assistants optimize automation with API-based agents appeared first on IBM Blog.
Regulators behind SR 11-7 also emphasize the importance of data—specifically data quality , relevance , and documentation. The authors also emphasize that documentation should be detailed enough so that “parties unfamiliar with a model can understand how the model operates, its limitations, and its key assumptions.”
Documentation and diagrams transform abstract discussions into something tangible. From documentation to automation Shawn McCarthy 3. Complex ideas that remain purely verbal often get lost or misunderstood. From control to enablement Shawn McCarthy 2.
It’s a full-fledged platform … pre-engineered with the governance we needed, and cost-optimized. He estimates 40 generative AI production use cases currently, such as drafting and emailing documents, translation, document summarization, and research on clients.
While a snapshot is in progress, you can still index documents and make other requests to the domain, but new documents and updates to existing documents generally aren’t included in the snapshot. They take time to complete and don’t represent perfect point-in-time views of the domain.
The term refers in particular to the use of AI and machine learning methods to optimize IT operations. The legacy challenge It is a paradox of IT infrastructure that unlike startups, which can simply start from scratch large companies in particular find it more difficult to modernize and optimize, as Marc Schmidt from Avodaq knows.
They had bugs, particularly if they were optimizing your code (were optimizing compilers a forerunner of AI?). As generative AI penetrates further into programming, we will undoubtedly see stylized dialects of human languages that have less ambiguous semantics; those dialects may even become standardized and documented.
We will also cover the pattern with automatic compaction through AWS Glue Data Catalog table optimization. Consider a streaming pipeline ingesting real-time event data while a scheduled compaction job runs to optimize file sizes. For more detailed configuration, refer to Write properties in the Iceberg documentation.
And by using digital twins of factories and processes, BMW plans, simulates, and optimizes processes using virtualization, the third pillar, before physical changes are made. Time is of the essence The vision is to optimize and control production in real time. BMW Group But until that point, the current situation had to be documented.
In retail, they can personalize recommendations and optimize marketing campaigns. Sustainable IT is about optimizing resource use, minimizing waste and choosing the right-sized solution. Think sentiment analysis of customer reviews, summarizing lengthy documents or extracting information from medical records.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







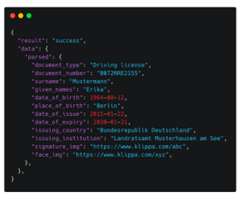












































Let's personalize your content