This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
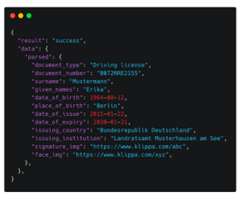
Introduction This article aims to create an AI-powered RAG and Streamlit chatbot that can answer users questions based on custom documents. Users can upload documents, and the chatbot can answer questions by referring to those documents.
Your companys AI assistant confidently tells a customer its processed their urgent withdrawal requestexcept it hasnt, because it misinterpreted the API documentation. When we talk about conversational AI, were referring to systems designed to have a conversation, orchestrate workflows, and make decisions in real time.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. One more embellishment is to use a graph neural network (GNN) trained on the documents. Chunk your documents from unstructured data sources, as usual in GraphRAG. at Facebook—both from 2020.
And because these are our lawyers working on our documents, we have a historical record of what they typically do. We get a lot of documents from 20,000 customers, in all sorts of formats, says Brian Halpin, the companys senior managing director of automation. That adds up to millions of documents a month that need to be processed.
According to the indictment, Jain’s firm provided fraudulent certification documents during contract negotiations in 2011, claiming that their Beltsville, Maryland, data center met Tier 4 standards, which require 99.995% uptime and advanced resilience features. From 2012 through 2018, the SEC paid Company A approximately $10.7
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
For example, Whisper correctly transcribed a speaker’s reference to “two other girls and one lady” but added “which were Black,” despite no such racial context in the original conversation. This phenomenon, known as hallucination, has been documented across various AI models. Whisper is not the only AI model that generates such errors.
Both Delta Lake and Iceberg metadata files reference the same data files. For more information about the table protocol versions, refer to What is a table protocol specification? in Delta Lake public document. For the information about enabling UniForm, refer to Enable Delta Lake UniForm in the Delta Lake public document.
Pure Storage empowers enterprise AI with advanced data storage technologies and validated reference architectures for emerging generative AI use cases. See additional references and resources at the end of this article. OVX Validated Reference Architecture for AI-ready Infrastructures First question: What is OVX validation?
Include documents: You can include documents as part of a prompt. Checking an AI is more like being a fact-checker for someone writing an important article: Can every fact be traced back to a documentable source? Is every reference correct and—even more important—does it exist? It may reduce hallucination.
Data poisoning refers to someone systematically changing your training data to manipulate your model’s predictions. Watermarking is a term borrowed from the deep learning security literature that often refers to putting special pixels into an image to trigger a desired outcome from your model. Data poisoning attacks. Watermark attacks.
Technology supports collaboration by enabling direct communications, facilitating document sharing (where comments by participants are easily accessed) and completing necessary reviews and sign-offs. Software assists in ensuring that steps in the processes are handled completely and correctly.
What this meant was the emergence of a new stack for ML-powered app development, often referred to as MLOps. Any scenario in which a student is looking for information that the corpus of documents can answer. Wrong document retrieval : Debug chunking strategy, retrieval method. Evaluation is the engine, not the afterthought.
Refer to this developer guide to understand more about index snapshots Understanding manual snapshots Manual snapshots are point-in-time backups of your OpenSearch Service domain that are initiated by the user. Snapshots are not instantaneous. They take time to complete and don’t represent perfect point-in-time views of the domain.
The scrum guide specifically refers to the Product Owner as “ Responsible for the product backlog, its content, availability and ordering”. From Requirements Specification Documents (RSDs) To Product Backlogs RSDs have their merit in the traditional software development lifecycle.
For log workloads, restore only recent or relevant logs to save time and use this opportunity to purge unnecessary documents or indexes. Create indexes and populate them with documents. We refer to this role as TheSnapshotRole in this post. For the request structure, see Take snapshots in the OpenSearch documentation.
For more details, refer to the BladeBridge Analyzer Demo. Refer to this BladeBridge documentation to get more details on SQL and expression conversion. If you encounter any challenges or have additional requirements, refer to the BladeBridge community support portal or reach out to the BladeBridge team for further assistance.
In the rest of this article, we will refer to IPA as intelligent automation (IA), which is simply short-hand for intelligent process automation. Process automation is relatively clear – it refers to an automatic implementation of a process, specifically a business process in our case. Sound similar?
And Miso had already built an early LLM-based search engine using the open-source BERT model that delved into research papers—it could take a query in natural language and find a snippet of text in a document that answered that question with surprising reliability and smoothness.
Search applications include ecommerce websites, document repository search, customer support call centers, customer relationship management, matchmaking for gaming, and application search. Before FMs, search engines used a word-frequency scoring system called term frequency/inverse document frequency (TF/IDF).
Complex queries, on the other hand, refer to large-scale data processing and in-depth analysis based on petabyte-level data warehouses in massive data scenarios. Referring to the data dictionary and screenshots, its evident that the complete data lineage information is highly dispersed, spread across 29 lineage diagrams. where(outV().as('a')),
dbt helps manage data transformation by enabling teams to deploy analytics code following software engineering best practices such as modularity, continuous integration and continuous deployment (CI/CD), and embedded documentation. To add documentation: Run dbt docs generate to generate the documentation for your project.
Now that we have covered AI agents, we can see that agentic AI refers to the concept of AI systems being capable of independent action and goal achievement, while AI agents are the individual components within this system that perform each specific task. Do you know what the user agent does in this scenario?
TIAA has launched a generative AI implementation, internally referred to as “Research Buddy,” that pulls together relevant facts and insights from publicly available documents for Nuveen, TIAA’s asset management arm, on an as-needed basis. When the research analysts want the research, that’s when the AI gets activated.
They use a lot of jargon: 10/10 refers to the intensity of pain. Generalized abd radiating to lower” refers to general abdominal (stomach) pain that radiates to the lower back. Jargon refers to the 100-200 new words you learn in the first month after you join a new school or workplace. They don’t have a subject.
For instance, records may be cleaned up to create unique, non-duplicated transaction logs, master customer records, and cross-reference tables. Finally, the challenge we are addressing in this document – is how to prove the data is correct at each layer.? Documentation and analysis become natural outcomes, not barriers to progress.
Enhance the table and column descriptions : Documenting table and column descriptions requires a good understanding of the business process, terminology, acronyms, and domain knowledge. This provides a way to document your tables and columns directly from the metadata defined in the underlying database.
For more details, refer to Tags for AWS Identity and Access Management resources and Pass session tags in AWS STS. For instructions, refer to Data analyst permissions. For instruction refer to: Job runtime roles for Amazon EMR Serverless Setup EMR Serverless application with Lake Formation enabled.
To learn more, refer to our documentation and the AWS News Blog. This allows for a seamless data ingestion and transformation across multiple data sources.
Refer to the detailed blog post on how you can use this to connect through various other tools. Get started with our technical documentation. You can now use your tool of choice, including Tableau, to quickly derive business insights from your data while using standardized definitions and decentralized ownership.
In addition, SAP Business Network Asset Collaboration (BNAC) will integrate with cloud-based ERP, gaining bi-directional integration of materials and models between BNAC and ERP systems, integration of inspection checklists, and additional application server document uploads to reduce data entry.
Refer to the product documentation to learn more about how to set up metadata rules for subscription and publishing workflows. Start using this enhanced search capability today and experience the difference it brings to your data discovery journey.
They consist of: A data sample of the documents you want to index. A pipeline of processors that apply transforms on ingested documents. An index constructed from the processed documents. From the designer, we see that Cohere Rerank requires a list of documents and the query context as input.
One study by Think With Google shows that marketing leaders are 130% as likely to have a documented data strategy. Optical Character Recognition, or OCR, is a technology for reading documents and extracting data. Optical Character Recognition, or OCR, is a technology for reading documents and extracting data.
In your Google Cloud project, youve enabled the following APIs: Google Analytics API Google Analytics Admin API Google Analytics Data API Google Sheets API Google Drive API For more information, refer to Amazon AppFlow support for Google Sheets. Refer to the Amazon Redshift Database Developer Guide for more details.
The term refers in particular to the use of AI and machine learning methods to optimize IT operations. In addition, there is often a lack of clear documentation and a deep understanding of the existing architecture. According to Henckel, the age structure in the admin area and a lack of documentation further complicates modernization.
E-signatures, or the digitized or scanned version of handwritten signatures, improve business processes, allowing fast signing and approval of documents. They are used to verify digital documents and messages. They can manipulate systems, show fake messages to validate signatures, and add content to already signed digital documents.
You can use the query from the Amazon Redshift documentation and add the same start and end times. Our findings serve as a reference point rather than a universal benchmark. Although our test results serve as a reference point, each organization should evaluate their specific workload requirements and price-performance targets.
For more information, refer SQL models. During the run, dbt creates a Directed Acyclic Graph (DAG) based on the internal reference between the dbt components. For more information, refer to Redshift set up. For creation instructions, refer to Create a cluster. Refer to installation for more information.
Organizations are collecting and storing vast amounts of structured and unstructured data like reports, whitepapers, and research documents. End-users often struggle to find relevant information buried within extensive documents housed in data lakes, leading to inefficiencies and missed opportunities.
Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose. While the digital age has been successful in prompting innovation far and wide, it has also facilitated what is referred to as the “data crisis” – low-quality data.
Though loosely applied, agentic AI generally refers to granting AI agents more autonomy to optimize tasks and chain together increasingly complex actions. Think summarizing, reviewing, even flagging risk across thousands of documents. Agentic AI is the new frontier in AI evolution, taking center stage in todays enterprise discussion.
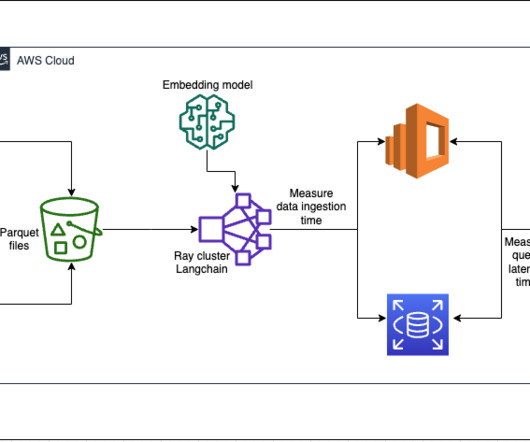
RAG is a machine learning (ML) architecture that uses external documents (like Wikipedia) to augment its knowledge and achieve state-of-the-art results on knowledge-intensive tasks. We introduce the integration of Ray into the RAG contextual document retrieval mechanism. Outputs[?
With CloudSearch, you can search large collections of data such as webpages, document files, forum posts, or product information. You send your documents to OpenSearch Serverless, which indexes them for search using the OpenSearch REST API. Because OpenSearch Service uses a REST API, numerous methods exist for indexing documents.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content