This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Last month, TheNew York Times claimed that tech giants OpenAI and Google have waded into a copyright gray area by transcribing the vast volume of YouTube videos and using that text as additional training data for their AI models despite terms of service that prohibit such efforts and copyright law that the Times argues places them in dispute. The Times also quoted Meta officials as saying that their models will not be able to keep up unless they follow OpenAI and Google’s lead.
Reading Time: 5 minutes The data landscape has evolved and become more complex as organizations recognize the need to leverage data and analytics. Generative artificial intelligence has further put pressure on organizations to manage this complexity. At TDWI, we see companies collecting traditional structured. The post Navigating the New Data Landscape: Trends and Opportunities appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information
How Can My Business Understand and Handle Those Pesky Data Anomalies? Why guess at the cause of your business results? Whether you are seeing positive or negative results, it is still important to understand the ‘why.’ Without this information, you cannot adapt and adjust to improve declining results, OR repeat and improve those great results you are experiencing.
Introduction Ever wonder how to get a complete picture of your company from different databases? SQL can help! Merging data from tables is like putting puzzle pieces together. This lets you analyze and report on all your information at once. In this article, we’ll explore how to use SQL queries like JOIN, UNION, etc. Overview Let’s dive […] The post 11 Ways to Merge Tables in SQL appeared first on Analytics Vidhya.
AI adoption is reshaping sales and marketing. But is it delivering real results? We surveyed 1,000+ GTM professionals to find out. The data is clear: AI users report 47% higher productivity and an average of 12 hours saved per week. But leaders say mainstream AI tools still fall short on accuracy and business impact. Download the full report today to see how AI is being used — and where go-to-market professionals think there are gaps and opportunities.
The world of Generative AI (GenAI) is rapidly evolving, with a wide array of models available for businesses to leverage. These models can be broadly categorized into two types: closed-source (proprietary) and open-source models. Closed-source models, such as OpenAI’s GPT-4o, Anthropic’s Claude 3, or Google’s Gemini 1.5 Pro, are developed and maintained by private and public companies.
Three years ago BSH Home Appliances completely rearranged its IT organization, creating a digital platform services team consisting of three global platform engineering teams, and four regional platform and operations teams. Berke Menekli, VP of digital platform services, says it’s one of the best things he ever did. BSH’s previous infrastructure and operations teams, which supported the European appliance manufacturer’s application development groups, simply acted as suppliers of infrastructur
Understanding LLMs is pivotal in unlocking the full potential of AI-driven solutions across various domains. As we navigate the process of building AI-driven solutions, it is essential to approach the development and deployment of LLMs with a focus on responsible AI practices.
Understanding LLMs is pivotal in unlocking the full potential of AI-driven solutions across various domains. As we navigate the process of building AI-driven solutions, it is essential to approach the development and deployment of LLMs with a focus on responsible AI practices.
Multimodal search enables both text and image search capabilities, transforming how users access data through search applications. Consider building an online fashion retail store: you can enhance the users’ search experience with a visually appealing application that customers can use to not only search using text but they can also upload an image depicting a desired style and use the uploaded image alongside the input text in order to find the most relevant items for each user.
“What’s a metaphor?” Mr. Biergel posed the question one morning to my high school grammar class. Being typical teenagers, we looked at him with blank-eyed stares. We expected that if we waited long enough, he’d write a paragraph-long definition on the blackboard. “What’s a metaphor?” he repeated. “A place for cows to graze!” We groaned.
On January 5, 2023, the Corporate Sustainability Reporting Directive (CSRD) came into effect – but what exactly does that mean? The European Parliament adopted this regulation as a significant step within the European Green Deal framework of 2019.
Introduction The advent of huge language models in the likes of ChatGPT ushered in a new epoch concerning conversational AI in the rapidly changing world of artificial intelligence. Anthropic’s ChatGPT model, which can engage in human-like dialogues, solve difficult tasks, and provide well thought-out answers that are contextually relevant, has fascinated people all over the […] The post Why Does ChatGPT Use Only Decoder Architecture?
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We’re planning a live virtual event later this year, and we want to hear from you. Are you using a powerful AI technology that seems like everyone ought to be using? Here’s your opportunity to show the world ! AI is too often seen as a “first world” enterprise of, by, and for the wealthy. We’re going to take a look at a Digital Green ’s Farmer.Chat , a generative AI bot that was designed to help small-scale farmers in developing countries access critical agricultural information.
Artificial intelligence, it is widely assumed, will soon unleash the biggest transformation in health care provision since the medical sector started its journey to professionalization after the flu pandemic of 1918. The catch is that bringing this about will require new institutional channels for knowledge, engineering, and ethical collaboration that don’t yet exist.
Introduction “AI Agentic workflow will drive massive progress this year,” commented Andrew Ng, highlighting the significant advancements anticipated in AI. With the growing popularity of large language models, Autonomous Agents are becoming a topic of discussion. In this article, we will explore Autonomous Agents, cover the components of building an Agentic workflow, and discuss the […] The post Building an Agentic Workflow with CrewAI and Groq appeared first on Analytics Vidhy
The DHS compliance audit clock is ticking on Zero Trust. Government agencies can no longer ignore or delay their Zero Trust initiatives. During this virtual panel discussion—featuring Kelly Fuller Gordon, Founder and CEO of RisX, Chris Wild, Zero Trust subject matter expert at Zermount, Inc., and Principal of Cybersecurity Practice at Eliassen Group, Trey Gannon—you’ll gain a detailed understanding of the Federal Zero Trust mandate, its requirements, milestones, and deadlines.
Navigating the Storm: How Data Engineering Teams Can Overcome a Data Quality Crisis Ah, the data quality crisis. It’s that moment when your carefully crafted data pipelines start spewing out numbers that make as much sense as a cat trying to bark. You know you’re in trouble when the finance team uses your reports as modern art installations rather than decision-making tools.
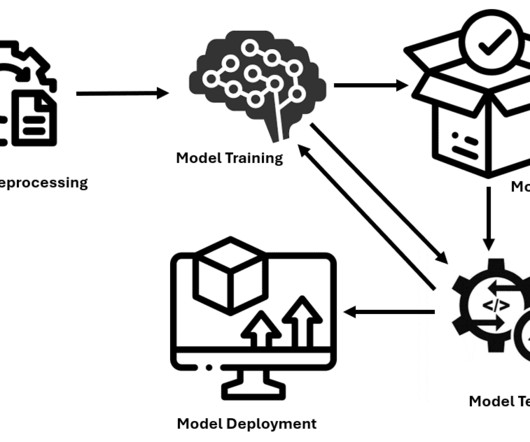
Image by author Model deployment is the process of trained models being integrated into practical applications. This includes defining the necessary environment, specifying how input data is introduced into the model and the output produced, and the capacity to analyze new data and provide relevant predictions or categorizations.
As a nonprofit R&D center for the US government, MITRE is no stranger to AI. Its researchers have long been working with IBM’s Watson AI technology, and so it would come as little surprise that — when OpenAI released ChatGPT based on GPT 3.5 in late November 2022 — MITRE would be among the first organizations looking to capitalize on the technology, launching MITREChatGPT a month later.
Introduction In the fast-evolving world of AI, it’s crucial to keep track of your API costs, especially when building LLM-based applications such as Retrieval-Augmented Generation (RAG) pipelines in production. Experimenting with different LLMs to get the best results often involves making numerous API requests to the server, each request incurring a cost.
GAP's AI-Driven QA Accelerators revolutionize software testing by automating repetitive tasks and enhancing test coverage. From generating test cases and Cypress code to AI-powered code reviews and detailed defect reports, our platform streamlines QA processes, saving time and resources. Accelerate API testing with Pytest-based cases and boost accuracy while reducing human error.
AWS Glue is a serverless data integration service that enables you to run extract, transform, and load (ETL) workloads on your data in a scalable and serverless manner. One of the main advantages of using a cloud platform is its flexibility; you can provision compute resources when you actually need them. However, with this ease of creating resources comes a risk of spiraling cloud costs when those resources are left unmanaged or without guardrails.
Enterprise resource planning (ERP) is ripe for a major makeover thanks to generative AI, as some experts see the tandem as a perfect pairing that could lead to higher profits at enterprises that combine them. The use of gen AI with ERP systems is still in its early days, but the combination is expected to provide several benefits, including helping employees create specialized ERP functionality on their own through code wizards, says Liz Herbert, a Forrester analyst and lead author of the report
Introduction Land segmentation is significant in farther detecting and geological data frameworks (GIS) for analyzing and classifying diverse arrive cover sorts in partisan symbolism. This direct will walk you through making a arrive division demonstrate utilizing Google Soil Motor (GEE) and joining it with Python for upgraded usefulness. By the conclusion of this direct, you’ll […] The post Guide to Land Cover Classification using Google Earth Engine appeared first on Analytics Vidh
Savvy B2B marketers know that a great account-based marketing (ABM) strategy leads to higher ROI and sustainable growth. In this guide, we’ll cover: What makes for a successful ABM strategy? What are the key elements and capabilities of ABM that can make a real difference? How is AI changing workflows and driving functionality? This Martech Intelligence Report on Enterprise Account-Based Marketing examines the state of ABM in 2024 and what to consider when implementing ABM software.
In the 2022 Spring Playoffs for multiplayer video game League of Legends, Team Liquid suffered a shocking 0-3 loss to rival team Evil Geniuses, which prevented it from moving on to the 2022 World Championships. “Out of nowhere, they pulled some counter picks [during the draft] that we just had no visibility on,” says Jesse Hart, senior director of sports science and analytics for Team Liquid.
Introduction If you have been working with data, I’m sure you use Microsoft Excel or Google Sheets on a daily basis. These tools make data storage and organization so easy, that they’ve become indispensable for data analysts, finance professionals, and even students. The best part of using these programs is the built-in functions they have, […] The post Standard Deviation in Excel and Sheets appeared first on Analytics Vidhya.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
The Amazon EMR runtime for Apache Spark is a performance-optimized runtime that is 100% API compatible with open source Apache Spark. It offers faster out-of-the-box performance than Apache Spark through improved query plans, faster queries, and tuned defaults. Amazon EMR on EC2 , Amazon EMR Serverless , Amazon EMR on Amazon EKS , and Amazon EMR on AWS Outposts all use this optimized runtime, which is 4.5 times faster than Apache Spark 3.5.1 and has 2.8 times better price-performance based on an
A medida que el trabajo 100% remoto que instauró la pandemia comienza a retroceder, las organizaciones están optando por un modelo híbrido , que tiene a los empleados repartiéndose sus horas laborales entre la oficina y el hogar. Esta nueva forma de trabajar tiene, sin duda, sus beneficios, como una mayor flexibilidad, productividad y satisfacción de los trabajadores.
Introduction A fundamental component of statistical technique, regression analysis is essential for examining and measuring connections between variables. Its uses are numerous and diverse, from forecasting financial trends to evaluating medical results. This in-depth manual explores the essence of regression analysis, explaining its various kinds, applications, and underlying concepts.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content