This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Consider a streaming pipeline ingesting real-time event data while a scheduled compaction job runs to optimize file sizes. However, commits can still fail if the latest metadata is updated after the base metadata version is established. Generate new metadata files. Commit the metadata files to the catalog.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Datasphere goes beyond the “big three” data usage end-user requirements (ease of discovery, access, and delivery) to include data orchestration (data ops and data transformations) and business data contextualization (semantics, metadata, catalog services). As you would guess, maintaining context relies on metadata.
Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats. XTable isn’t a new table format but provides abstractions and tools to translate the metadata associated with existing formats.
For example, you can use metadata about the Kinesis data stream name to index by data stream ( ${getMetadata("kinesis_stream_name") ), or you can use document fields to index data depending on the CloudWatch log group or other document data ( ${path/to/field/in/document} ).
Metadata has been defined as the who, what, where, when, why, and how of data. Without the context given by metadata, data is just a bunch of numbers and letters. But going on a rampage to define, categorize, and otherwise metadata-ize your data doesn’t necessarily give you the key to the value in your data. Hold on tight!
In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer. This ensures that each change is tracked and reversible, enhancing data governance and auditability.
The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines. Event-driven architectures – The enhanced API facilitates seamless integration with external events, enabling the triggering of Airflow DAGs based on these events.
The proposed solution involves creating a custom subscription workflow that uses the event-driven architecture of Amazon DataZone. Amazon DataZone keeps you informed of key activities (events) within your data portal, such as subscription requests, updates, comments, and system events. Enter a name for the asset.
An Iceberg table’s metadata stores a history of snapshots, which are updated with each transaction. Over time, this creates multiple data files and metadata files as changes accumulate. Additionally, they can impact query performance due to the overhead of handling large amounts of metadata.
Entities are the nodes in the graph — these can be people, events, objects, concepts, or places. Each of those cases deeply involves entities (people, objects, events, actions, concepts, and places) and their relationships (touch points, both causal and simple associations).
This is accomplished through tags, annotations, and metadata (TAM). Smart content includes labeled (tagged, annotated) metadata (TAM). The key to success is to start enhancing and augmenting content management systems (CMS) with additional features: semantic content and context. Collect, curate, and catalog (i.e.,
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products. A data portal for consumers to discover data products and access associated metadata. Subscription workflows that simplify access management to the data products.
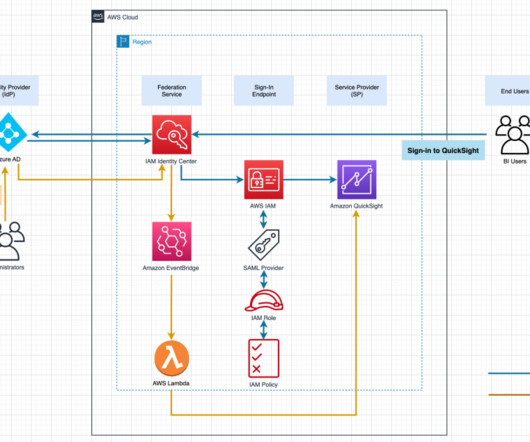
If your organization uses Microsoft Azure Active Directory (Azure AD) for centralized authentication and utilizes its user attributes to organize the users, you can enable federation across all QuickSight accounts as well as manage users and their group membership in QuickSight using events generated in the AWS platform.
Know thy data: understand what it is (formats, types, sampling, who, what, when, where, why), encourage the use of data across the enterprise, and enrich your datasets with searchable (semantic and content-based) metadata (labels, annotations, tags). Do not covet thy data’s correlations: a random six-sigma event is one-in-a-million.
It offers a wealth of books, on-demand courses, live events, short-form posts, interactive labs, expert playlists, and more—formed from the proprietary content of thousands of independent authors, industry experts, and several of the largest education publishers in the world.
From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. The data in the central data warehouse in Amazon Redshift is then processed for analytical needs and the metadata is shared to the consumers through Amazon DataZone. This process is shown in the following figure.
We recommend using AWS Step Functions Workflow Studio , and setting up Amazon S3 event notifications and an SNS FIFO queue to receive the filename as messages. Because a CDC file can contain data for multiple tables, the job loops over the tables in a file and loads the table metadata from the source table ( RDS column names).
Metadata analysis makes it possible to build data catalogs, which in turn allow humans to discover data that’s relevant to their projects. The customer demographics are different; but more than that, the event sources are different. Joe Hellerstein on how "Metadata services can lead to performance and organizational improvements".
When it comes to near-real-time analysis of data as it arrives in Security Lake and responding to security events your company cares about, Amazon OpenSearch Service provides the necessary tooling to help you make sense of the data found in Security Lake. Under Log and event sources , specify what the subscriber is authorized to ingest.
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data fabric Metadata-rich integration layer across distributed systems. Implementation complexity, relies on robust metadata management.
The data is also registered in the Glue Data Catalog , a metadata repository. Amazon EventBridge , a serverless event bus service, triggers a downstream process that allows you to build event-driven architecture as soon as your new data arrives in your target. Check CloudWatch log events for the SEED Load.
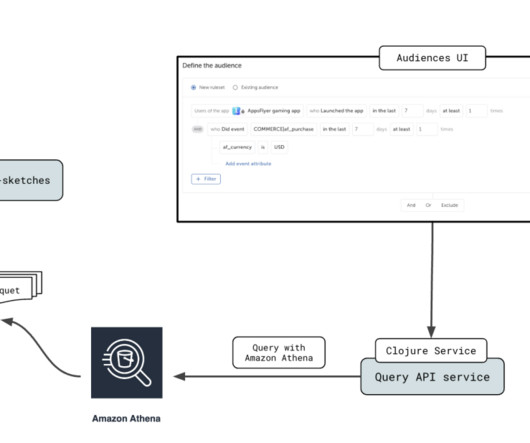
Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products. Users can search for assets in the Amazon DataZone catalog, view the metadata assigned to them, and access the assets. Amazon Athena is used to query, and explore the data.
Upon successful authentication, the custom claims provider triggers the custom authentication extensions token issuance start event listener. The custom authentication extension calls an Azure function (your REST API endpoint) with information about the event, user profile, session data, and other context. Select it and choose Next.
The following diagram illustrates an indexing flow involving a metadata update in OR1 During indexing operations, individual documents are indexed into Lucene and also appended to a write-ahead log also known as a translog. In the event of an infrastructure failure, an OpenSearch domain can end up losing one or more nodes.
This may require frequent truncation in certain tables to retain only the latest stream of events. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. Agent states are reported in agent-state events.
With the Amazon DataZone OpenLineage-compatible API, domain administrators and data producers can capture and store lineage events beyond what is available in Amazon DataZone, including transformations in Amazon Simple Storage Service (Amazon S3), AWS Glue , and other AWS services.
Ontotext’s Relation and Event Detector (RED) is designed to assess and analyze the impact of market-moving events. Entity linking allows events to be associated with specific companies in the graph and correlated with information from 3rd party databases, namely Crunchbase, and public information about stock prices.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. S3 Metadata is designed to automatically capture metadata from objects as they are uploaded into a bucket, and to make that metadata queryable in a read-only table.
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations.
using high-dimensional data feature space to disambiguate events that seem to be similar, but are not). The thing itself (or the data about the thing) may not be surprising (though it could be), but the context (the “metadata”, which is “other data about the primary data”) provides a signal that something needs attention here.
Data-driven decisions lead to more effective responses to unexpected events, increase innovation and allow organizations to create better experiences for their customers. Short overview of Cloudinary’s infrastructure Cloudinary infrastructure handles over 20 billion requests daily with every request generating event logs.
’ It assigns unique identifiers to each data item—referred to as ‘payloads’—related to each event. Payload DJs facilitate capturing metadata, lineage, and test results at each phase, enhancing tracking efficiency and reducing the risk of data loss.
AppsFlyer develops a leading measurement solution focused on privacy, which enables marketers to gauge the effectiveness of their marketing activities and integrates them with the broader marketing world, managing a vast volume of 100 billion events every day. This led the team to examine partition indexing.
As we enter 2021, we will also be building off the events of 2020 – both positive and negative – including the acceleration of digital transformation as the next normal begins to be defined. Technical metadata is what makes up database schema and table definitions.
In this blog, we discuss the technical challenges faced by Cargotec in replicating their AWS Glue metadata across AWS accounts, and how they navigated these challenges successfully to enable cross-account data sharing. Solution overview Cargotec required a single catalog per account that contained metadata from their other AWS accounts.
Maybe your AI model monitors sales data, and the data is spiking for one region of the country due to a world event. Metadata is the basis of trust for data forensics as we answer the questions of fact or fiction when it comes to the data we see. Lets give a for instance.
Initially called Onetable, the project became Apache XTable in September 2024 and provides a lightweight translation layer to translate metadata between table formats without the need to duplicate or modify the data. In 2023, Onehouse announced an initiative to provide interoperability across table formats.
Enter metadata. Metadata describes data and includes information such as how old data is, where it was created, who owns it, and what concepts (or other data) it relates to. As a result, leveraging metadata has become a core capability for businesses trying to extract value from their data. Knowledge (metadata) layer.
Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table. Get table data and metadata for this user to see how Lake Formation permissions are enforced and so the two users can see different data (on the Authorized Data tab).
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
Gartner Data & Analytics Summit is a must-attend event for Data Leaders and experts. To kick off the conference season Octopai and Cloudera will be attending and sponsoring the Gartner D&A Orlando event from March 3-5 in Orlando Florida.
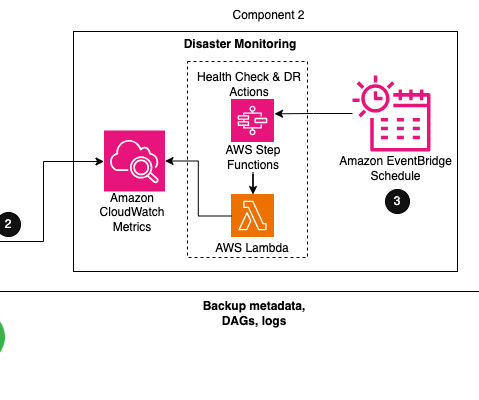
Within Airflow, the metadata database is a core component storing configuration variables, roles, permissions, and DAG run histories. A healthy metadata database is therefore critical for your Airflow environment. The AWS Health Dashboard provides information about AWS Health events that can affect your account.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content