This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines. Event-driven architectures – The enhanced API facilitates seamless integration with external events, enabling the triggering of Airflow DAGs based on these events.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats. XTable isn’t a new table format but provides abstractions and tools to translate the metadata associated with existing formats.
The proposed solution involves creating a custom subscription workflow that uses the event-driven architecture of Amazon DataZone. Amazon DataZone keeps you informed of key activities (events) within your data portal, such as subscription requests, updates, comments, and system events. Enter a name for the asset.
Know thy data: understand what it is (formats, types, sampling, who, what, when, where, why), encourage the use of data across the enterprise, and enrich your datasets with searchable (semantic and content-based) metadata (labels, annotations, tags). Do not covet thy data’s correlations: a random six-sigma event is one-in-a-million.
have a large body of tools to choose from: IDEs, CI/CD tools, automated testing tools, and so on. We have great tools for working with code: creating it, managing it, testing it, and deploying it. Metadata analysis makes it possible to build data catalogs, which in turn allow humans to discover data that’s relevant to their projects.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
Upon successful authentication, the custom claims provider triggers the custom authentication extensions token issuance start event listener. The custom authentication extension calls an Azure function (your REST API endpoint) with information about the event, user profile, session data, and other context. Choose Test this application.
It offers a wealth of books, on-demand courses, live events, short-form posts, interactive labs, expert playlists, and more—formed from the proprietary content of thousands of independent authors, industry experts, and several of the largest education publishers in the world.
Hydro is powered by Amazon MSK and other tools with which teams can move, transform, and publish data at low latency using event-driven architectures. To address this, we used the AWS performance testing framework for Apache Kafka to evaluate the theoretical performance limits.
Generally, the path from prototype to production starts with deploying your AI connectors , designing flows from a data sample, then exporting your flows from a development cluster to a preproduction environment for testing at-scale. Lets test our multimodal RAG flow by searching for sunset colored dresses.
You can now test the newly created application by running the following command: npm run dev By default, the application is available on port 5173 on your local machine. Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table.
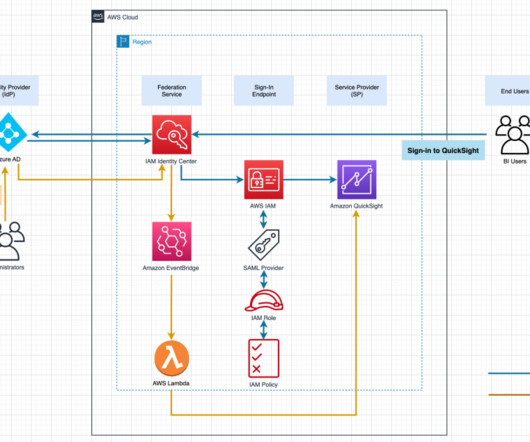
If your organization uses Microsoft Azure Active Directory (Azure AD) for centralized authentication and utilizes its user attributes to organize the users, you can enable federation across all QuickSight accounts as well as manage users and their group membership in QuickSight using events generated in the AWS platform.
There are no automated tests , so errors frequently pass through the pipeline. There is no process to spin up an isolated dev environment to quickly add a feature, test it with actual data and deploy it to production. The pipeline has automated tests at each step, making sure that each step completes successfully.
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations. with Spark 3.3.2,
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data fabric Metadata-rich integration layer across distributed systems. Implementation complexity, relies on robust metadata management.
When it comes to near-real-time analysis of data as it arrives in Security Lake and responding to security events your company cares about, Amazon OpenSearch Service provides the necessary tooling to help you make sense of the data found in Security Lake. Under Log and event sources , specify what the subscriber is authorized to ingest.
AppsFlyer develops a leading measurement solution focused on privacy, which enables marketers to gauge the effectiveness of their marketing activities and integrates them with the broader marketing world, managing a vast volume of 100 billion events every day. This led the team to examine partition indexing.
Data-driven decisions lead to more effective responses to unexpected events, increase innovation and allow organizations to create better experiences for their customers. Short overview of Cloudinary’s infrastructure Cloudinary infrastructure handles over 20 billion requests daily with every request generating event logs.
’ It assigns unique identifiers to each data item—referred to as ‘payloads’—related to each event. Payload DJs facilitate capturing metadata, lineage, and test results at each phase, enhancing tracking efficiency and reducing the risk of data loss.
This may require frequent truncation in certain tables to retain only the latest stream of events. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. Agent states are reported in agent-state events.
In the context of Data in Place, validating data quality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets. Running these automated tests as part of your DataOps and Data Observability strategy allows for early detection of discrepancies or errors.
This populates the technical metadata in the business data catalog for each data asset. The business metadata, can be added by business users to provide business context, tags, and data classification for the datasets. The successful completion of the AWS Glue crawler generates an event in the default event bus of Amazon EventBridge.
With the Amazon DataZone OpenLineage-compatible API, domain administrators and data producers can capture and store lineage events beyond what is available in Amazon DataZone, including transformations in Amazon Simple Storage Service (Amazon S3), AWS Glue , and other AWS services.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. S3 Metadata is designed to automatically capture metadata from objects as they are uploaded into a bucket, and to make that metadata queryable in a read-only table.
But Transformers have some other important advantages: Transformers don’t require training data to be labeled; that is, you don’t need metadata that specifies what each sentence in the training data means. It’s by far the most convincing example of a conversation with a machine; it has certainly passed the Turing test.
Maybe your AI model monitors sales data, and the data is spiking for one region of the country due to a world event. Metadata is the basis of trust for data forensics as we answer the questions of fact or fiction when it comes to the data we see. Lets give a for instance.
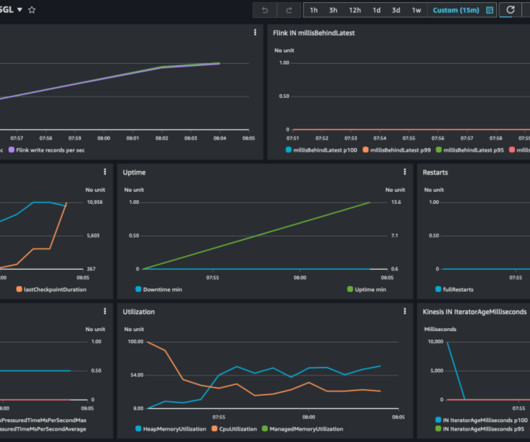
This post covers how you can implement data enrichment for near-online streaming events with Apache Flink and how you can optimize performance. To compare the performance of the enrichment patterns, we ran performance testing based on synthetic data. The result of this test is useful as a general reference.
Within Airflow, the metadata database is a core component storing configuration variables, roles, permissions, and DAG run histories. A healthy metadata database is therefore critical for your Airflow environment. The AWS Health Dashboard provides information about AWS Health events that can affect your account.
With Lake Formation, you can centralize data security and governance using the AWS Glue Data Catalog , letting you manage metadata and data permissions in one place with familiar database-style features. glue:GetUnfilteredTableMetadata – Allows a third-party analytical engine to retrieve unfiltered table metadata from the Data Catalog.
The rising trend in today’s tech landscape is the use of streaming data and event-oriented structures. You can do this by setting Amazon MSK as an event source for a Lambda function. For testing, this post includes a sample AWS Cloud Development Kit (AWS CDK) application. API Gateway forwards the request to a Lambda function.
Figure 1: Flow of actions for self-service analytics around data assets stored in relational databases First, the data producer needs to capture and catalog the technical metadata of the data asset. Second, the data producer needs to consolidate the data asset’s metadata in the business catalog and enrich it with business metadata.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
These logs can track activity, such as data access patterns, lifecycle and management activity, and security events. AWS Glue Data Catalog stores information as metadata tables, where each table specifies a single data store. Running the crawler on a schedule updates AWS Glue Data Catalog with new partitions and metadata.
Additionally, shard redistribution during failure events causes increased resource utilization, leading to increased latencies and overloaded nodes, further impacting availability and effectively defeating the purpose of fault-tolerant, multi-AZ clusters. This event is referred to as a zonal failover.
If you also needed to preserve the history of DAG runs, you had to take a backup of your metadata database and then restore that backup on the newly created environment. Amazon MWAA manages the entire upgrade process, from provisioning new Apache Airflow versions to upgrading the metadata database. or v2.0.2, and higher environment.
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. Also known as data validation, integrity refers to the structural testing of data to ensure that the data complies with procedures. Your Chance: Want to test a professional analytics software?
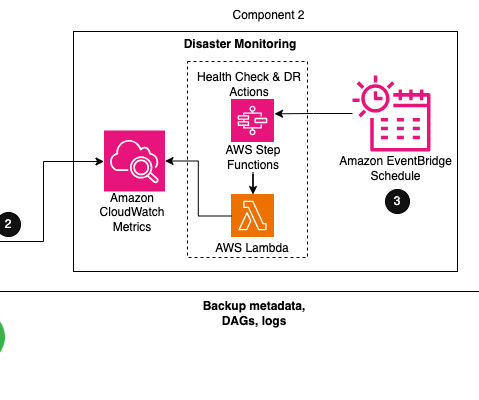
The company wanted the ability to continue processing operational data in the secondary Region in the rare event of primary Region failure. Finally, by testing the framework, we summarize how it meets the aforementioned requirements. The event rule forwards the object event notifications to the SQS queue as messages.
After all, it’s very likely that you are developing your flow against test systems but in production it needs to run against production systems, meaning that your source and destination connection configuration has to be adjusted. To meet this need we’ve introduced a new concept called test sessions with the DataFlow Designer. .
This JSON file contains the migration metadata, namely the following: A list of Google BigQuery projects and datasets. The state machine iterates on the metadata from this DynamoDB table to run the table migration in parallel, based on the maximum number of migration jobs without incurring limits or quotas on Google BigQuery.
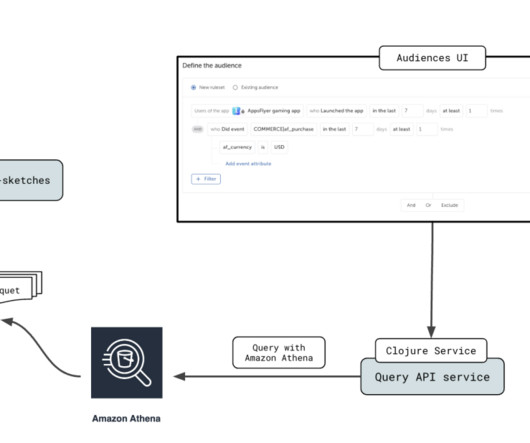
It will cover how you can get started with building a truly composable CDP with Amazon Redshift—from the solution architecture to setting up and testing the connector. Event tables: Fact or log-like tables contain events or actions your customers take. The primary key is typically a user_id and timestamp.
Everything is being tested, and then the campaigns that succeed get more money put into them, while the others aren’t repeated. This methodology of “test, look at the data, adjust” is at the heart and soul of business intelligence. Your Chance: Want to try a professional BI analytics software?
By querying across OpenSearch Service and S3 datasets, you can evaluate multiple data sources to perform forensic analysis of operational and security events. Many customers currently use Amazon S3 to store event data for their solutions. Solution overview Let’s take a test drive using VPC Flow Logs as your source!
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content