This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Right now most organizations tend to be in the experimental phases of using the technology to supplement employee tasks, but that is likely to change, and quickly, experts say. But that’s just the tip of the iceberg for a future of AI organizational disruptions that remain to be seen, according to the firm.
It seems as if the experimental AI projects of 2019 have borne fruit. data cleansing services that profile data and generate statistics, perform deduplication and fuzzy matching, etc.—or A large share of survey respondents use AI in customer service, marketing, operations, finance, and other domains. But what kind?
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown. One reason to do ramp-up is to mitigate the risk of never before seen arms.
Finance: Data on accounts, credit and debit transactions, and similar financial data are vital to a functioning business. But for data scientists in the finance industry, security and compliance, including fraud detection, are also major concerns. Data scientists can help with this process.
As the preferred business introductory book, this book covers the business environment, job hunting, business management, human resources, marketing, finance, and other aspects, leading readers to master comprehensive knowledge of business operations. By William G Nickels, James McHugh, Susan McHugh. By Michael Milton.
After completing MTech from Indian Statistical Institute, I started my career at Cognizant. We developed multiple products on Sales, Collection, Operations, Credit and implemented products in HR, Finance, and other areas. What do you do to foster a culture of innovation and experimentation in your employees?
Its data entry system and support of decision-making platform provide a series of functions of data reporting, process approval, and authority management, which can flexibly respond to business needs such as operations, human resources, finance, and contracts. Application architecture of FineReport. From Google. Data Analysis Libraries.
In every Apache Flink release, there are exciting new experimental features. You can find valuable statistics you can’t normally find elsewhere, including the Apache Flink Dashboard. However, in this post, we are going to focus on the features most accessible to the user with this release.
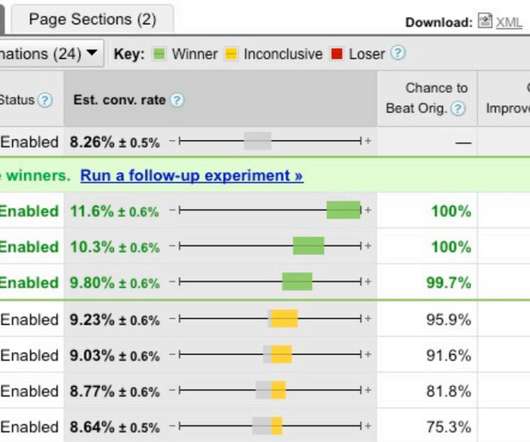
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. Buy Experimentation findings The following table shows Sharpe Ratios for various holding periods and two different trade entry points: announcement and effective dates. Sell 1 (PVH, PVH) 2022-09-06 18321.729571 55.15
Ignore the metrics produced as an experimental exercise nine months ago. Inspire each Marketer, Finance Analyst, Logistics Support Staff, Call Center Manager, and every VP to move one step up or one step to the right. Ignore the metrics whose only purpose is to float along the river of data pukes.
One of the most fundamental tenets of statistical methods in the last century has focused on correlation to determine causation. The quantitative models that make ML-enhanced analytics possible analyze business issues through statistical, mathematical and computational techniques.
Since you're reading a blog on advanced analytics, I'm going to assume that you have been exposed to the magical and amazing awesomeness of experimentation and testing. And yet, chances are you really don’t know anyone directly who uses experimentation as a part of their regular business practice. Wah wah wah waaah.
We develop an ordinary least squares (OLS) linear regression model of equity returns using Statsmodels, a Python statistical package, to illustrate these three error types. CI theory was developed around 1937 by Jerzy Neyman, a mathematician and one of the principal architects of modern statistics. and an error term ??
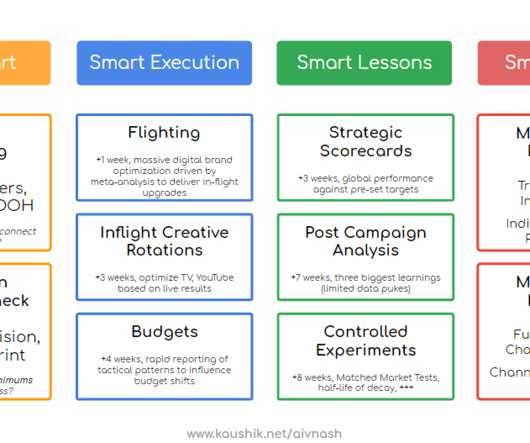
upgrades to processes to create deeper integration with Finance & Strategy teams. This is very hard to do, we now have a proven seven-step experimentation process, with one of the coolest algorithms to pick matched-markets (normally the kiss of death of any large-scale geo experiment). It is powered by the union of: 1.
If your Marketer is not savvy in basic finance and analytics and writing some html and creating mobile campaigns and tag clouds then you have a long term liability on your hands, and not an asset who is really, really, really, really good at writing copy for display campaigns. Increasingly, your people can't be one-trick ponies.
Unlike experimentation in some other areas, LSOS experiments present a surprising challenge to statisticians — even though we operate in the realm of “big data”, the statistical uncertainty in our experiments can be substantial. We must therefore maintain statistical rigor in quantifying experimental uncertainty.
In this post we explore why some standard statistical techniques to reduce variance are often ineffective in this “data-rich, information-poor” realm. Despite a very large number of experimental units, the experiments conducted by LSOS cannot presume statistical significance of all effects they deem practically significant.
They list several scenarios to avoid — political campaigns and highly sensitive events where use or misuse could be consequential to life opportunities or legal status — and others to be cautious about, such as high stakes areas in healthcare, education, finance and legal.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content