This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Without clarity in metrics, it’s impossible to do meaningful experimentation. AI PMs must ensure that experimentation occurs during three phases of the product lifecycle: Phase 1: Concept During the concept phase, it’s important to determine if it’s even possible for an AI product “ intervention ” to move an upstream business metric.
Chatbots cannot hold long, continuing human interaction. Traditionally they are text-based but audio and pictures can also be used for interaction. They provide more like an FAQ (Frequently Asked Questions) type of an interaction. Consequently, they can have extended adaptable human interaction. 4) Prosthetics.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. However, if we experiment with both parameters at the same time we will learn something about interactions between these system parameters.
Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature. Among these, only statistical uncertainty has formal recognition.
For teams that want to boil down their own data into predictive tools, Model Builder will turn all those records of past purchases sitting in the data lake into a big statistical hair ball of tendencies that passes for an AI these days. Salesforce is pushing the idea that Einstein 1 is a vehicle for experimentation and iteration.
Candidates are required to complete a minimum of 12 credits, including four required courses: Algorithms for Data Science, Probability and Statistics for Data Science, Machine Learning for Data Science, and Exploratory Data Analysis and Visualization. Candidates have 90 minutes to complete the exam.
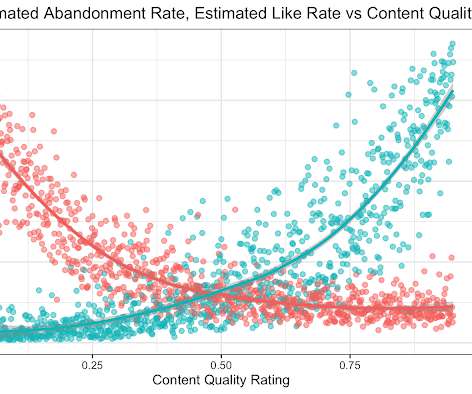
Remember that the raw number is not the only important part, we would also measure statistical significance. It essentially allowed you to create a group of friends who could interact and share content, much as people do today with Google+, before such features were part of Facebook. The result? The graph is impressive, right?
When multiple independent but interactive agents are combined, each capable of perceiving the environment and taking actions, you get a multiagent system. But multiagent AI systems are still in the experimental stages, or used in very limited ways. According to Gartner, an agent doesn’t have to be an AI model.
For example auto insurance companies offering to capture real-time driving statistics from policy-holders’ cars to encourage and reward safe driving. And it’s become a hyper-competitive business, so enhancing customer service through data is critical for maintaining customer loyalty.
The other dimension to consider is most Analtyics teams kick into gear after the campaign is concluded, after the customer interaction has taken place in the call center, and after the funds budgeted have already been spent. That’s not really surprising, if your view of your scope is narrow… Your impact will be narrow as well.
Two years later, I published a post on my then-favourite definition of data science , as the intersection between software engineering and statistics. Like other authors, they argue that causal inference has been neglected by traditional statistics and some scientific disciplines. In a recent article , Hernán et al.
In addition, Jupyter Notebook is also an excellent interactive tool for data analysis and provides a convenient experimental platform for beginners. Pandas incorporates a large number of analysis function methods, as well as common statistical models and visualization processing. From Google. Data Analysis Libraries.
Quantum computers naturally re-create the behavior of atoms and even subatomic particles—making them valuable for simulating how matter interacts with its environment. Enterprises have a large appetite for tackling complex combinatorial and black-box problems to generate more robust insights for strategic planning and investments.
Unlike experimentation in some other areas, LSOS experiments present a surprising challenge to statisticians — even though we operate in the realm of “big data”, the statistical uncertainty in our experiments can be substantial. We must therefore maintain statistical rigor in quantifying experimental uncertainty.
by MICHAEL FORTE Large-scale live experimentation is a big part of online product development. This means a small and growing product has to use experimentation differently and very carefully. This blog post is about experimentation in this regime. But these are not usually amenable to A/B experimentation.
Part of it is fueled by a vocal minority genuinely upset that 10 years on we are still not a statistically powered bunch doing complicated analysis that is shifting paradigms. If you don't have a robust experimentation program in your company you are going to die. Part of it fueled by some Consultants. Likely not.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Yet, this challenge is not insurmountable. for what is and isn’t possible) to address these challenges.
Hypothesis development and design of experimentation. Ok, maybe statistical modeling smells like an analytical skill. . + Pattern recognition and understanding trends. Argumentation and logical thinking. Ability to create insightful data visualizations. Strategic thinking skills. And, that is just a random list! You lose twice.
Experimentation on networks A/B testing is a standard method of measuring the effect of changes by randomizing samples into different treatment groups. However, this assumption no longer holds when samples interact with each other, such as in a network. This simulation is based on the actual user network of GCP.
From observing behavior closely, and from my own experimentation and failure, I've noticed consistent patterns in what great employees do and great bosses do. They find the external author of the statistical algorithm I want them to use, and ask them for guidance. Caring touches all sorts of interactions you’ll have.
LLMs like ChatGPT are trained on massive amounts of text data, allowing them to recognize patterns and statistical relationships within language. Also, its emotional intelligence allows it to adapt communication to be empathetic and supportive, creating a more positive interaction for the customer.
But what if users don't immediately uptake the new experimental version? Background At Google, experimentation is an invaluable tool for making decisions and inference about new products and features. by DANIEL PERCIVAL Randomized experiments are invaluable in making product decisions, including on mobile apps.
Any code or connection interacts with the interface of the gateway only. We expect statistically equal distribution of jobs between the two clusters. Solution overview Martin Fowler describes a gateway as an object that encapsulates access to an external system or resource. A gateway acts as a single point to confront this resource.
Scale to provide 1,000s of researchers frictionless interaction with data. How can he make it easy to see statistics, and do calculations, on discovered commonalities, across structured and unstructured data? How can users drill down, in non-technical ways, to quickly interact with data that explains what correlations seem to matter?
They also require advanced skills in statistics, experimental design, causal inference, and so on – more than most data science teams will have. Use of influence functions goes back to the 1970s in robust statistics. Jupyter Book: Interactive books running in the cloud ” by Chris Holdgraf (2019-03-27).
Bonus: Interactive CD: Contains six podcasts, one video, two web analytics metrics definitions documents and five insightful powerpoint presentations. Experimentation & Testing (A/B, Multivariate, you name it). Bonus: Interactive CD. Immediately actionable web analytics (your biggest worries covered). Clicks and outcomes.
To figure this out, let's consider an appropriate experimental design. In other words, the teacher is our second kind of unit, the unit of experimentation. This type of experimental design is known as a group-randomized or cluster-randomized trial. The second source of dependence comes from student interactions.
How will they interact with product, engineering, sales, or marketing? you’re looking for a collaborator who can work and communicate well with you and your team, as well as anyone else that interacts with your team. What to evaluate: How will this person contribute to your culture? Will they be a strategic thought partner?
Domino Lab supports both interactive and batch experimentation with all popular IDEs and notebooks (Jupyter, RStudio, SAS, Zeppelin, etc.). We can group by study arm and calculate various statistics as mean and standard deviation. The analyses shown below are accessible in the NCA project on Domino’s trial site.
According to Gartner, companies need to adopt these practices: build culture of collaboration and experimentation; start with a 3-way partnership among executives leading digital initiative, line of business and IT. Also, loyalty leaders infuse analytics into CX programs, including machine learning, data science and data integration.
It is important to make clear distinctions among each of these, and to advance the state of knowledge through concerted observation, modeling and experimentation. These quasi-explanations usually involve large, real effects and interactions so complex that arguments based on them are often non-falsifiable.
Daily Interactions. Technical environments and IDEs must be disposable so that experimental costs can be kept to a minimum. Quality must be monitored continuously to catch unexpected variation cases and produce statistics on its operation. It’s a Team Sport. Stakeholders must work collaboratively daily for the project.
To support the iterative and experimental nature of industry work, Domino reached out to Addison-Wesley Professional (AWP) for appropriate permissions to excerpt the “Tuning Hyperparameters and Pipelines” from the book, Machine Learning with Python for Everyone by Mark E. Choice and Assessment of Statistical Predictions by Stone.
Nimit Mehta: I think that 2024 is going to be a buckle-down year, but, at the same time, we’ll see a rapid explosion of experimentation. These are not statistical inferences. So, I think natural language interactions and the capabilities to have AI assistants that will help you do your business or personal work will stay.
Although it’s not perfect, [Note: These are statistical approximations, of course!] Instead, we recommend using the bokeh library to create a highly interactive—and actionable—plot, as with the code provided in Example 11.11. Interactive bokeh plot of two-dimensional word-vector data. Example 11.6 Example 11.11 y=subset_df.y,
Microsoft called the poll an error and promised to investigate, but it already seems to clearly breach several of the company’s own principles of responsible AI usage , such as inform people that they’re interacting with an AI system, and guidelines for human-AI interaction.
The most powerful approach for the first task is to use a ‘language model’ (LM), i.e. a statistical model of natural language. After some experimentation, I landed on a strategy I’ll call ‘warm encoding’: if greater than 1% of tags were in a particular class, I encoded the book as belonging to that class, non-exclusively.
After completing MTech from Indian Statistical Institute, I started my career at Cognizant. What do you do to foster a culture of innovation and experimentation in your employees? Only experimentation can help to improve this index. Every such interaction requires a different approach.
Presto is an open source distributed SQL query engine for data analytics and the data lakehouse, designed for running interactive analytic queries against datasets of all sizes, from gigabytes to petabytes. Data Exploration and Innovation: The flexibility of Presto has encouraged data exploration and experimentation at Uber.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content