This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
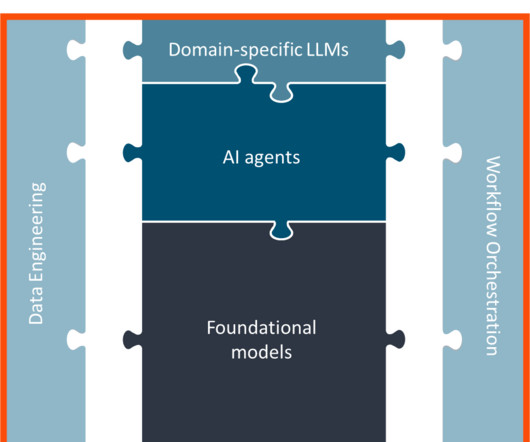
Large language models (LLMs) just keep getting better. In just about two years since OpenAI jolted the news cycle with the introduction of ChatGPT, weve already seen the launch and subsequent upgrades of dozens of competing models. From Llama3.1 to Gemini to Claude3.5 From Llama3.1 to Gemini to Claude3.5
AI PMs should enter feature development and experimentation phases only after deciding what problem they want to solve as precisely as possible, and placing the problem into one of these categories. Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model.
Recent research shows that 67% of enterprises are using generative AI to create new content and data based on learned patterns; 50% are using predictive AI, which employs machine learning (ML) algorithms to forecast future events; and 45% are using deep learning, a subset of ML that powers both generative and predictive models.
Let’s start by considering the job of a non-ML software engineer: writing traditional software deals with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly model in the code. Not only is data larger, but models—deep learning models in particular—are much larger than before.
than multi-channel attribution modeling. By the time you are done with this post you'll have complete knowledge of what's ugly and bad when it comes to attribution modeling. You'll know how to use the good model, even if it is far from perfect. Multi-Channel Attribution Models. Linear Attribution Model.
This post is a primer on the delightful world of testing and experimentation (A/B, Multivariate, and a new term from me: Experience Testing). Experimentation and testing help us figure out we are wrong, quickly and repeatedly and if you think about it that is a great thing for our customers, and for our employers.
Throughout this article, well explore real-world examples of LLM application development and then consolidate what weve learned into a set of first principlescovering areas like nondeterminism, evaluation approaches, and iteration cyclesthat can guide your work regardless of which models or frameworks you choose. Which multiagent frameworks?
By 2026, hyperscalers will have spent more on AI-optimized servers than they will have spent on any other server until then, Lovelock predicts. In some cases, the AI add-ons will be subscription models, like Microsoft Copilot, and sometimes, they will be free, like Salesforce Einstein, he says. growth in device spending.
Instead of writing code with hard-coded algorithms and rules that always behave in a predictable manner, ML engineers collect a large number of examples of input and output pairs and use them as training data for their models. The model is produced by code, but it isn’t code; it’s an artifact of the code and the training data.
With traditional OCR and AI models, you might get 60% straight-through processing, 70% if youre lucky, but now generative AI solves all of the edge cases, and your processing rates go up to 99%, Beckley says. Even simple use cases had exceptions requiring business process outsourcing (BPO) or internal data processing teams to manage.
In my book, I introduce the Technical Maturity Model: I define technical maturity as a combination of three factors at a given point of time. Outputs from trained AI models include numbers (continuous or discrete), categories or classes (e.g., spam or not-spam), probabilities, groups/segments, or a sequence (e.g.,
As they look to operationalize lessons learned through experimentation, they will deliver short-term wins and successfully play the gen AI — and other emerging tech — long game,” Leaver said. Determining the optimal level of autonomy to balance risk and efficiency will challenge business leaders,” Le Clair said.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. This post is co-written by Dr. Leonard Heilig and Meliena Zlotos from EUROGATE. This approach fosters knowledge sharing across the ML lifecycle.
Amazon Redshift , optimized for complex queries, provides high-performance columnar storage and massively parallel processing (MPP) architecture, supporting large-scale data processing and advanced SQL capabilities. In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. Observe, optimize, and scale enterprise data pipelines. . ModelOp — Governs, monitors, and orchestrates models across the enterprise. Meta-Orchestration .
Customers maintain multiple MWAA environments to separate development stages, optimize resources, manage versions, enhance security, ensure redundancy, customize settings, improve scalability, and facilitate experimentation. micro, remember to monitor its performance using the recommended metrics to maintain optimal operation.
They achieve this through models, patterns, and peer review taking complex challenges and breaking them down into understandable components that stakeholders can grasp and discuss. Experimentation: The innovation zone Progressive cities designate innovation districts where new ideas can be tested safely.
If the relationship of $X$ to $Y$ can be approximated as quadratic (or any polynomial), the objective and constraints as linear in $Y$, then there is a way to express the optimization as a quadratically constrained quadratic program (QCQP). Figure 2: Spreading measurements out makes estimates of model (slope of line) more accurate.
Many of these go slightly (but not very far) beyond your initial expectations: you can ask it to generate a list of terms for search engine optimization, you can ask it to generate a reading list on topics that you’re interested in. It’s important to understand that ChatGPT is not actually a language model. with specialized training.
Many companies whose AI model training infrastructure is not proximal to their data lake incur steeper costs as the data sets grow larger and AI models become more complex. The cloud is great for experimentation when data sets are smaller and model complexity is light. Potential headaches of DIY on-prem infrastructure.
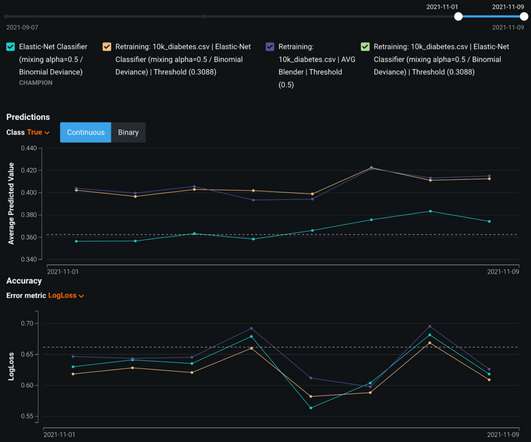
Other organizations are just discovering how to apply AI to accelerate experimentation time frames and find the best models to produce results. Taking a Multi-Tiered Approach to Model Risk Management. Learn how to leverage Google BigQuery large datasets for large scale Time Series forecasting models in the DataRobot AI platform.
More and more enterprises are leveraging pre-trained models for various applications, from natural language processing to computer vision. For data providers, InDaiX enhances distribution by reaching Cloudera’s established customer base and provides valuable feedback on data usage and integration with AI models.
Yehoshua I've covered this topic in detail in this blog post: Multi-Channel Attribution: Definitions, Models and a Reality Check. I explain three different models (Online to Store, Across Multiple Devices, Across Digital Channels) and for each I've highlighted: 1. What's possible to measure.
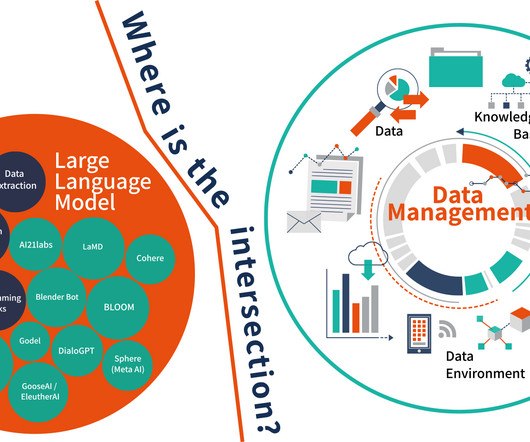
I did some research because I wanted to create a basic framework on the intersection between large language models (LLM) and data management. LLM is by its very design a language model. The meaning of the data is the most important component – as the data models are on their way to becoming a commodity.
The early bills for generative AI experimentation are coming in, and many CIOs are finding them more hefty than they’d like — some with only themselves to blame. According to IDC’s “ Generative AI Pricing Models: A Strategic Buying Guide ,” the pricing landscape for generative AI is complicated by “interdependencies across the tech stack.”
Cloud maturity models are a useful tool for addressing these concerns, grounding organizational cloud strategy and proceeding confidently in cloud adoption with a plan. Cloud maturity models (or CMMs) are frameworks for evaluating an organization’s cloud adoption readiness on both a macro and individual service level.
With the generative AI gold rush in full swing, some IT leaders are finding generative AI’s first-wave darlings — large language models (LLMs) — may not be up to snuff for their more promising use cases. With this model, patients get results almost 80% faster than before. It’s fabulous.”
Our mental models of what constitutes a high-performance team have evolved considerably over the past five years. Post-pandemic, high-performance teams excelled at remote and hybrid working models, were more empathetic to individual needs, and leveraged automation to reduce manual work.
Sandeep Davé knows the value of experimentation as well as anyone. CBRE has also used AI to optimize portfolios for several clients, and recently launched a self-service generative AI product that enables employees to interact with CBRE and external data in a conversational manner. Let’s start with the models.
Additionally, nuclear power companies and energy infrastructure firms are hiring to optimize and secure energy systems, while smart city developers need IoT and AI specialists to build sustainable and connected urban environments, Breckenridge explains.
Most, if not all, machine learning (ML) models in production today were born in notebooks before they were put into production. Data science teams of all sizes need a productive, collaborative method for rapid AI experimentation. Capabilities Beyond Classic Jupyter for End-to-end Experimentation. Auto-scale compute.
Generative AI (GenAI) models, such as GPT-4, offer a promising solution, potentially reducing the dependency on labor-intensive annotation. Through iterative experimentation, we incrementally added new modules refining the prompts. BioRED performance Prompt Model P R F1 Price Latency Generic prompt GPT-4o 72 35 47.8
Leveraging DataRobot’s JDBC connectors, enterprise teams can work together to train ML models on their data residing in SAP HANA Cloud and SAP Data Warehouse Cloud, as well as have an option to enrich it with data from external data sources.
We build models to test our understanding, but these models are not “one and done.” In ML, the learning cycle is sometimes called backpropagation, where the errors (inaccurate predictions) of our models are fed back into adjusting the model’s input parameters in a way that aims to improve the output accuracy.
You can read previous blog posts on Impala’s performance and querying techniques here – “ New Multithreading Model for Apache Impala ”, “ Keeping Small Queries Fast – Short query optimizations in Apache Impala ” and “ Faster Performance for Selective Queries ”. . Analytical SQL workloads use aggregates and joins heavily.
The exam covers everything from fundamental to advanced data science concepts such as big data best practices, business strategies for data, building cross-organizational support, machine learning, natural language processing, scholastic modeling, and more. and SAS Text Analytics, Time Series, Experimentation, and Optimization.
Experimentation drives momentum: How do we maximize the value of a given technology? Via experimentation. This can be as simple as a Google Sheet or sharing examples at weekly all-hands meetings Many enterprises do “blameless postmortems” to encourage experimentation without fear of making mistakes and reprisal.
A developing playbook of best practices for data science teams covers the development process and technologies for building and testing machine learning models. CIOs and CDOs should lead ModelOps and oversee the lifecycle Leaders can review and address issues if the data science teams struggle to develop models.
The excerpt covers how to create word vectors and utilize them as an input into a deep learning model. While the field of computational linguistics, or Natural Language Processing (NLP), has been around for decades, the increased interest in and use of deep learning models has also propelled applications of NLP forward within industry.
Most tools offer visual programming interfaces that enable users to drag and drop various icons optimized for data analysis. Drag-and-drop Modeler for creating pipelines, IBM integrations. A high level of automation encourages deploying these models into production to generate a constant stream of insights and predictions.
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Let's listen in as Alistair discusses the lean analytics model… The Lean Analytics Cycle is a simple, four-step process that shows you how to improve a part of your business. But it is not routine.
In this example, the Machine Learning (ML) model struggles to differentiate between a chihuahua and a muffin. Will the model correctly determine it is a muffin or get confused and think it is a chihuahua? The extent to which we can predict how the model will classify an image given a change input (e.g. Model Visibility.
They’re about having the mindset of an experimenter and being willing to let data guide a company’s decision-making process. This benefit goes directly in hand with the fact that analytics provide businesses with technologies to spot trends and patterns that will lead to the optimization of resources and processes.
Unfortunately, most organizations run into trouble when it comes to bridging the gap that exists between experimentation and full-scale ML production. Proper science takes experimentation and observation, as well as a willingness to accept the failures alongside the successes. Optimize later. Step 4: Iterate quickly.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content