This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
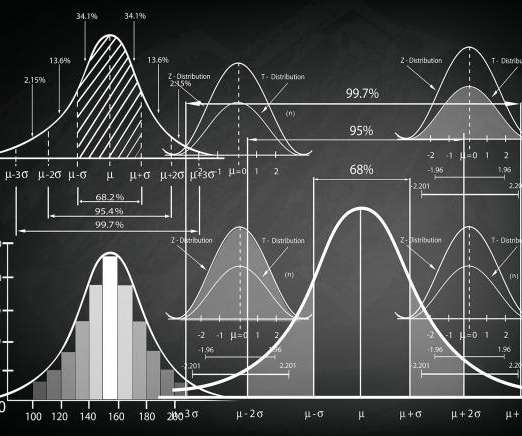
This article was published as a part of the Data Science Blogathon Introduction to StatisticsStatistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimental data or real-world studies. Data processing is […].
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. For any given input, the same program won’t necessarily produce the same output; the output depends entirely on how the model was trained.
This post is a primer on the delightful world of testing and experimentation (A/B, Multivariate, and a new term from me: Experience Testing). Experimentation and testing help us figure out we are wrong, quickly and repeatedly and if you think about it that is a great thing for our customers, and for our employers. Counter claims?
Whether it’s controlling for common risk factors—bias in model development, missing or poorly conditioned data, the tendency of models to degrade in production—or instantiating formal processes to promote data governance, adopters will have their work cut out for them as they work to establish reliable AI production lines.
Other organizations are just discovering how to apply AI to accelerate experimentation time frames and find the best models to produce results. Bureau of Labor Statistics predicts that the employment of data scientists will grow 36 percent by 2031, 1 much faster than the average for all occupations. Read the blog.
It’s important to understand that ChatGPT is not actually a language model. It’s a convenient user interface built around one specific language model, GPT-3.5, is one of a class of language models that are sometimes called “large language models” (LLMs)—though that term isn’t very helpful. with specialized training.
The tools include sophisticated pipelines for gathering data from across the enterprise, add layers of statistical analysis and machine learning to make projections about the future, and distill these insights into useful summaries so that business users can act on them. Drag-and-drop Modeler for creating pipelines, IBM integrations.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. Figure 2: Spreading measurements out makes estimates of model (slope of line) more accurate. And sometimes even if it is not[1].)
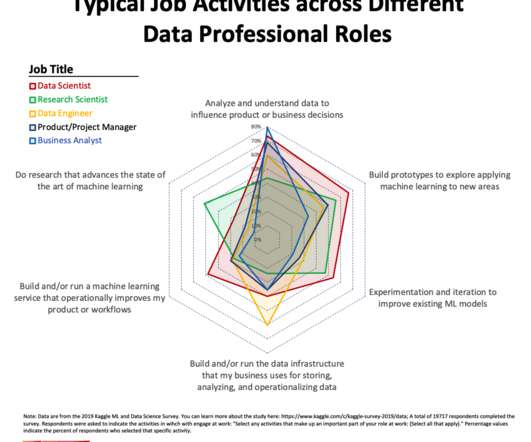
Experimentation and iteration to improve existing ML models (39%). These top work activities included influencing business decisions, building prototypes to expand machine learning to new areas and improving ML models. Build prototypes to explore applying machine learning to new areas (52%).
Autonomous Vehicles: Self-driving (guided without a human), informed by data streaming from many sensors (cameras, radar, LIDAR), and makes decisions and actions based on computer vision algorithms (ML and AI models for people, things, traffic signs,…). Examples: Cars, Trucks, Taxis. They cannot process language inputs generally. See [link].
” Given the statistics—82% of surveyed respondents in a 2023 Statista study cited managing cloud spend as a significant challenge—it’s a legitimate concern. Cloud maturity models (or CMMs) are frameworks for evaluating an organization’s cloud adoption readiness on both a macro and individual service level.
The US Bureau of Labor Statistics (BLS) forecasts employment of data scientists will grow 35% from 2022 to 2032, with about 17,000 openings projected on average each year. You need experience in machine learning and predictive modeling techniques, including their use with big, distributed, and in-memory data sets.
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown. One reason to do ramp-up is to mitigate the risk of never before seen arms.
The certification focuses on the seven domains of the analytics process: business problem framing, analytics problem framing, data, methodology selection, model building, deployment, and lifecycle management. They can also transform the data, create data models, visualize data, and share assets by using Power BI.
This year, however, Salesforce has accelerated its agenda, integrating much of its recent work with large language models (LLMs) and machine learning into a low-code tool called Einstein 1 Studio. Einstein 1 Studio is a set of low-code tools to create, customize, and embed AI models in Salesforce workflows. What is Einstein 1 Studio?
Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature. Among these, only statistical uncertainty has formal recognition.
The excerpt covers how to create word vectors and utilize them as an input into a deep learning model. While the field of computational linguistics, or Natural Language Processing (NLP), has been around for decades, the increased interest in and use of deep learning models has also propelled applications of NLP forward within industry.
AI ‘bake-offs’ under way Mathematica’s PaaS has not yet implemented AI models in production, but Bell grasps the power of machine learning (ML) and generative AI to uncover new insights that will help Mathematica’s clients.
The more high-quality data available to data scientists, the more parameters they can include in a given model, and the more data they will have on hand for training their models. It doesn’t conform to a data model but does have associated metadata that can be used to group it. Semi-structured data falls between the two.
. – Head First Data Analysis: A learner’s guide to big numbers, statistics, and good decisions. The big news is that we no longer need to be proficient in math or statistics, or even rely on expensive modeling software to analyze customers. By Michael Milton. – Data Divination: Big Data Strategies.
A 1958 Harvard Business Review article coined the term information technology, focusing their definition on rapidly processing large amounts of information, using statistical and mathematical methods in decision-making, and simulating higher order thinking through applications. What comes first: A new brand or operating model?
Let's listen in as Alistair discusses the lean analytics model… The Lean Analytics Cycle is a simple, four-step process that shows you how to improve a part of your business. Another way to find the metric you want to change is to look at your business model. The business model also tells you what the metric should be.
How do you get over the frustration of having done attribution modeling and realizing that it is not even remotely the solution to your challenge of using multiple media channels? You need people with deep skills in Scientific Method , Design of Experiments , and Statistical Analysis. ask for a raise. It is that simple.
According to Gartner, an agent doesn’t have to be an AI model. Starting in 2018, the agency used agents, in the form of Raspberry PI computers running biologically-inspired neural networks and time series models, as the foundation of a cooperative network of sensors. “It And, yes, enterprises are already deploying them.
He plans to scale his company’s experimental generative AI initiatives “and evolve into an AI-native enterprise” in 2024. It involves reimagining our strategies, business models, processes and culture centered around AI’s capabilities, to reshape how we work and drive unparalleled productivity and innovation,” he says. “AI
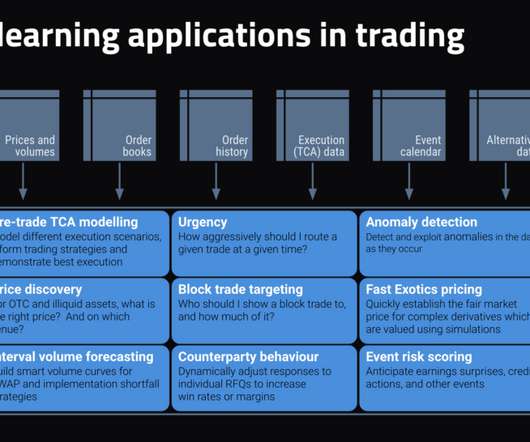
Recently, a prospective customer asked me how I reconcile the fact that DataRobot has multiple very successful investment banks using DataRobot to enhance the P&L of their trading businesses with my comments that machine learning models aren’t always great at predicting financial asset prices. For price discovery (e.g.,
Two years later, I published a post on my then-favourite definition of data science , as the intersection between software engineering and statistics. I was very comfortable with that definition, having spent my PhD years on several predictive modelling tasks, and having worked as a software engineer prior to that.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Yet, this challenge is not insurmountable. for what is and isn’t possible) to address these challenges.
Belcorp operates under a direct sales model in 14 countries. As Belcorp considered the difficulties it faced, the R&D division noted it could significantly expedite time-to-market and increase productivity in its product development process if it could shorten the timeframes of the experimental and testing phases in the R&D labs.
Ivory tower modeling We’ve seen too many models developed by isolated ontologists that don’t survive the first battle with the data. There’s a famous saying by a statistician, George Box, “All models are wrong, but some are useful.” ” So, how do you know whether your model is useful?
When it comes to data analysis, from database operations, data cleaning, data visualization , to machine learning, batch processing, script writing, model optimization, and deep learning, all these functions can be implemented with Python, and different libraries are provided for you to choose. From Google. Data Analysis Libraries.
These solutions help data analysts build models by automating tasks in data science, including training models, selecting algorithms, and creating features. These tools support a breadth of use cases including data science, data engineering, and model operations. Proprietary (often GUI-driven) data science platforms.
Companies are emphasizing the accuracy of machine learning models while at the same time focusing on cost reduction, both of which are important. In addition to the accuracy of the models we built, we had to consider business metrics, cost, interpretability, and suitability for ongoing operations. Sensor Data Analysis Examples.
Experimentation on networks A/B testing is a standard method of measuring the effect of changes by randomizing samples into different treatment groups. However, the downside of using a larger unit of randomization is that we lose experimental power. We now describe a generative model for how effects might propagate through the network.
Machine learning projects are inherently different from traditional IT projects in that they are significantly more heuristic and experimental, requiring skills spanning multiple domains, including statistical analysis, data analysis and application development. The challenge has been figuring out what to do once the model is built.
As such, data science requires three broad skill sets , including subject matter expertise, statistics/math and technology/programming. Experimentation and iteration to improve existing ML models (25%). The practice of data science is about extracting value from data to help inform decision making and improve algorithms.
But what if users don't immediately uptake the new experimental version? Background At Google, experimentation is an invaluable tool for making decisions and inference about new products and features. by DANIEL PERCIVAL Randomized experiments are invaluable in making product decisions, including on mobile apps.
So in addition to becoming good at Omniture, Google Analytics, Baidu Analytics , pick one other tool from the Experimentation, Voice of Customer, Competitive Intelligence buckets of Web Analytics 2.0. Get an overall web analytics strategy book, one that covers the ecosystem, the mental models to apply, key analytics techniques.
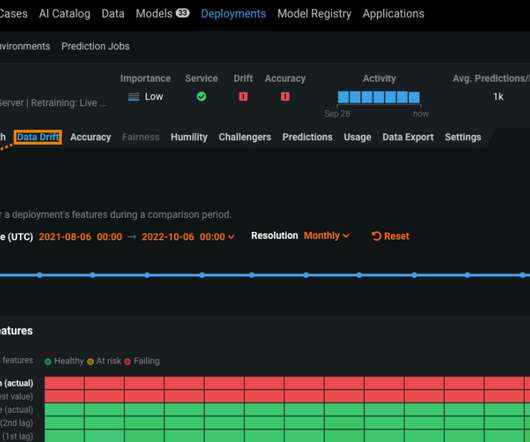
While changes in new data can threaten the performance of production models, data drift can be a strategic opportunity for your AI solution to quickly adapt to new patterns and maintain competitive advantage over not-so-quick competitors. Drill Down into Drift for Rapid Model Diagnostics. Change is inevitable. Growth is optional.
While these large language model (LLM) technologies might seem like it sometimes, it’s important to understand that they are not the thinking machines promised by science fiction. LLMs like ChatGPT are trained on massive amounts of text data, allowing them to recognize patterns and statistical relationships within language.
Data scientists typically come equipped with skills in three key areas: mathematics and statistics, data science methods, and domain expertise. It’s easy to deploy, monitor, and manage models in production and react to changing conditions. And any predictive model can become an AI app in minutes—no coding required.
As data science work is experimental and probabilistic in nature, data scientists are often faced with making inferences. You can use a regression model. model = OLS(X['Y'], X[['D', 'intercept']]) result = model.fit() result.summary(). A complementary Domino project is available. . Introduction. Why did this work?
When DataOps principles are implemented within an organization, you see an increase in collaboration, experimentation, deployment speed and data quality. Continuous pipeline monitoring with SPC (statistical process control). What DataOps best practices put you on track to achieving this ideal? Let’s take a look. Results (i.e.
In an ideal world, experimentation through randomization of the treatment assignment allows the identification and consistent estimation of causal effects. Identification We now discuss formally the statistical problem of causal inference. We start by describing the problem using standard statistical notation.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content