This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is a primer on the delightful world of testing and experimentation (A/B, Multivariate, and a new term from me: Experience Testing). Experimentation and testing help us figure out we are wrong, quickly and repeatedly and if you think about it that is a great thing for our customers, and for our employers.
AI PMs should enter feature development and experimentation phases only after deciding what problem they want to solve as precisely as possible, and placing the problem into one of these categories. Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model.
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. What breaks your app in production isnt always what you tested for in dev! The way out?
Let’s start by considering the job of a non-ML software engineer: writing traditional software deals with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly model in the code. Not only is data larger, but models—deep learning models in particular—are much larger than before.
Speaker: Teresa Torres, Internationally Acclaimed Author, Speaker, and Coach at ProductTalk.org
Industry-wide, product teams have adopted discovery practices like customer interviews and experimentation merely for end-user satisfaction. As a result, many of us are still stuck in a project-world rut: research, usability testing, engineering, and a/b testing, ad nauseam.
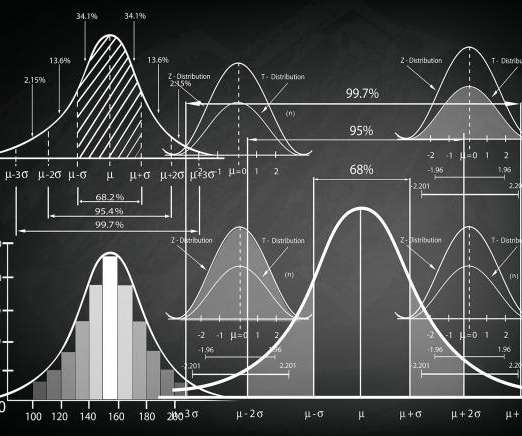
This article was published as a part of the Data Science Blogathon Introduction to Statistics Statistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimental data or real-world studies. Data processing is […].
Despite critics, most, if not all, vendors offering coding assistants are now moving toward autonomous agents, although full AI coding independence is still experimental, Walsh says. With existing, human-written tests you just loop through generated code, feeding the errors back in, until you get to a success state.”
Transformational CIOs continuously invest in their operating model by developing product management, design thinking, agile, DevOps, change management, and data-driven practices. Focusing on classifying data and improving data quality is the offense strategy, as it can lead to improving AI model accuracy and delivering business results.
Testing and Data Observability. DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. Testing and Data Observability.
While generative AI has been around for several years , the arrival of ChatGPT (a conversational AI tool for all business occasions, built and trained from large language models) has been like a brilliant torch brought into a dark room, illuminating many previously unseen opportunities. So, if you have 1 trillion data points (g.,
While genAI has been a hot topic for the past couple of years, organizations have largely focused on experimentation. Like any new technology, organizations typically need to upskill existing talent or work with trusted technology partners to continuously tune and integrate their AI foundation models. In 2025, thats going to change.
than multi-channel attribution modeling. By the time you are done with this post you'll have complete knowledge of what's ugly and bad when it comes to attribution modeling. You'll know how to use the good model, even if it is far from perfect. Multi-Channel Attribution Models. Linear Attribution Model.
Proof that even the most rigid of organizations are willing to explore generative AI arrived this week when the US Department of the Air Force (DAF) launched an experimental initiative aimed at Guardians, Airmen, civilian employees, and contractors. It is not training the model, nor are responses refined based on any user inputs.
Instead of writing code with hard-coded algorithms and rules that always behave in a predictable manner, ML engineers collect a large number of examples of input and output pairs and use them as training data for their models. This has serious implications for software testing, versioning, deployment, and other core development processes.
Similarly, in “ Building Machine Learning Powered Applications: Going from Idea to Product ,” Emmanuel Ameisen states: “Indeed, exposing a model to users in production comes with a set of challenges that mirrors the ones that come with debugging a model.”. Debugging AI Products.
These patterns could then be used as the basis for additional experimentation by scientists or engineers. Generative design is a new approach to product development that uses artificial intelligence to generate and test many possible designs. Automated Testing of Features. Generative Design. Quality Assurance.
It covers essential topics like artificial intelligence, our use of data models, our approach to technical debt, and the modernization of legacy systems. This initiative offers a safe environment for learning and experimentation. We are also testing it with engineering. We’ve structured our approach into phases.
By articulating fitness functions automated tests tied to specific quality attributes like reliability, security or performance teams can visualize and measure system qualities that align with business goals. Experimentation: The innovation zone Progressive cities designate innovation districts where new ideas can be tested safely.
As they look to operationalize lessons learned through experimentation, they will deliver short-term wins and successfully play the gen AI — and other emerging tech — long game,” Leaver said. The rest of their time is spent creating designs, writing tests, fixing bugs, and meeting with stakeholders. “So
Develop/execute regression testing . Test data management and other functions provided ‘as a service’ . The center of excellence (COE) model leverages the DataOps team to solve real-world challenges. Examples of technologies that can be delivered ‘as a service’ include: Source code control repository. Deploy to production.
It’s important to understand that ChatGPT is not actually a language model. It’s a convenient user interface built around one specific language model, GPT-3.5, is one of a class of language models that are sometimes called “large language models” (LLMs)—though that term isn’t very helpful. with specialized training.
Two years of experimentation may have given rise to several valuable use cases for gen AI , but during the same period, IT leaders have also learned that the new, fast-evolving technology isnt something to jump into blindly. The next thing is to make sure they have an objective way of testing the outcome and measuring success.
In my book, I introduce the Technical Maturity Model: I define technical maturity as a combination of three factors at a given point of time. Outputs from trained AI models include numbers (continuous or discrete), categories or classes (e.g., spam or not-spam), probabilities, groups/segments, or a sequence (e.g.,
Customers maintain multiple MWAA environments to separate development stages, optimize resources, manage versions, enhance security, ensure redundancy, customize settings, improve scalability, and facilitate experimentation. This approach offers greater flexibility and control over workflow management. The introduction of mw1.micro
Fractal’s recommendation is to take an incremental, test and learn approach to analytics to fully demonstrate the program value before making larger capital investments. It is also important to have a strong test and learn culture to encourage rapid experimentation. What is the most common mistake people make around data?
In recent years, we have witnessed a tidal wave of progress and excitement around large language models (LLMs) such as ChatGPT and GPT-4. The No Test Gaps Principle Under the No Test Gaps Principle, it is unacceptable that LLMs are not tested holistically with a reproducible test suite before deployment.
Yehoshua I've covered this topic in detail in this blog post: Multi-Channel Attribution: Definitions, Models and a Reality Check. I explain three different models (Online to Store, Across Multiple Devices, Across Digital Channels) and for each I've highlighted: 1. What's possible to measure.
From budget allocations to model preferences and testing methodologies, the survey unearths the areas that matter most to large, medium, and small companies, respectively. Medium companies Medium-sized companies—501 to 5,000 employees—were characterized by agility and a strong focus on GenAI experimentation.
They’ve also been using low-code and gen AI to quickly conceive, build, test, and deploy new customer-facing apps and experiences. In a fiercely competitive industry, where CX is critical to differentiation, this approach has enabled them to build and test new innovations about 10 times faster than traditional development.
But continuous deployment isn’t always appropriate for your business , stakeholders don’t always understand the costs of implementing robust continuous testing , and end-users don’t always tolerate frequent app deployments during peak usage. CrowdStrike recently made the news about a failed deployment impacting 8.5
Unfortunately, a common challenge that many industry people face includes battling “ the model myth ,” or the perception that because their work includes code and data, their work “should” be treated like software engineering. These steps also reflect the experimental nature of ML product management.
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Let's listen in as Alistair discusses the lean analytics model… The Lean Analytics Cycle is a simple, four-step process that shows you how to improve a part of your business. Testing out a new feature.
by HENNING HOHNHOLD, DEIRDRE O'BRIEN, and DIANE TANG In this post we discuss the challenges in measuring and modeling the long-term effect of ads on user behavior. We describe experiment designs which have proven effective for us and discuss the subtleties of trying to generalize the results via modeling.
Our mental models of what constitutes a high-performance team have evolved considerably over the past five years. Post-pandemic, high-performance teams excelled at remote and hybrid working models, were more empathetic to individual needs, and leveraged automation to reduce manual work.
Another reason to use ramp-up is to test if a website's infrastructure can handle deploying a new arm to all of its users. The website wants to make sure they have the infrastructure to handle the feature while testing if engagement increases enough to justify the infrastructure. We offer two examples where this may be the case.
Sandeep Davé knows the value of experimentation as well as anyone. As chief digital and technology officer at CBRE, Davé recognized early that the commercial real estate industry was ripe for AI and machine learning enhancements, and he and his team have tested countless use cases across the enterprise ever since.
In the context of Retrieval-Augmented Generation (RAG), knowledge retrieval plays a crucial role, because the effectiveness of retrieval directly impacts the maximum potential of large language model (LLM) generation. document-only) ~ 20%(bi-encoder) higher NDCG@10, comparable to the TAS-B dense vector model.
We present data from Google Cloud Platform (GCP) as an example of how we use A/B testing when users are connected. Experimentation on networks A/B testing is a standard method of measuring the effect of changes by randomizing samples into different treatment groups. This simulation is based on the actual user network of GCP.
We build models to test our understanding, but these models are not “one and done.” In ML, the learning cycle is sometimes called backpropagation, where the errors (inaccurate predictions) of our models are fed back into adjusting the model’s input parameters in a way that aims to improve the output accuracy. (3)
The exam tests general knowledge of the platform and applies to multiple roles, including administrator, developer, data analyst, data engineer, data scientist, and system architect. Candidates for the exam are tested on ML, AI solutions, NLP, computer vision, and predictive analytics.
Data scientists at Bayer have developed several proofs of concept of generative AI models on the new platform that remain in discovery and evaluation phase for “efficacy,” McQueen says, adding that the models won’t be in production until 2025. The R&D pipeline is pretty highly confidential at this point,” he says. It’s additive.”
The company’s multicloud infrastructure has since expanded to include Microsoft Azure for business applications and Google Cloud Platform to provide its scientists with a greater array of options for experimentation. For McCowan, the key is to give scientists any and all tools that allow them to explore their hypotheses and test theories.
Our mission at Domino is to enable organizations to put models at the heart of their business. Today we’re announcing two major new capabilities in Domino that make model development easier and faster for data scientists. This pain point is magnified in organizations with teams of data scientists working on numerous experiments.
In this example, the Machine Learning (ML) model struggles to differentiate between a chihuahua and a muffin. Will the model correctly determine it is a muffin or get confused and think it is a chihuahua? The extent to which we can predict how the model will classify an image given a change input (e.g. Model Visibility.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content