This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. What breaks your app in production isnt always what you tested for in dev! The way out?
Product Managers are responsible for the successful development, testing, release, and adoption of a product, and for leading the team that implements those milestones. Without clarity in metrics, it’s impossible to do meaningful experimentation. Ongoing monitoring of critical metrics is yet another form of experimentation.
ML apps need to be developed through cycles of experimentation: due to the constant exposure to data, we don’t learn the behavior of ML apps through logical reasoning but through empirical observation. but to reference concrete tooling used today in order to ground what could otherwise be a somewhat abstract exercise.
Customers maintain multiple MWAA environments to separate development stages, optimize resources, manage versions, enhance security, ensure redundancy, customize settings, improve scalability, and facilitate experimentation. Refer to Amazon Managed Workflows for Apache Airflow Pricing for rates and more details.
This initiative offers a safe environment for learning and experimentation. Phase two focused on developing use cases, creating a backlog, exploring domains for resource allocation, and identifying the right subject matter experts for testing and experimentation. We are also testing it with engineering.
This has serious implications for software testing, versioning, deployment, and other core development processes. There may even be someone on your team who built a personalized video recommender before and can help scope and estimate the project requirements using that past experience as a point of reference.
There’s a very important difference between these two almost identical sentences: in the first, “it” refers to the cup. In the second, “it” refers to the pitcher. It’s by far the most convincing example of a conversation with a machine; it has certainly passed the Turing test. Ethan Mollick says that it is “only OK at search.
We present data from Google Cloud Platform (GCP) as an example of how we use A/B testing when users are connected. Experimentation on networks A/B testing is a standard method of measuring the effect of changes by randomizing samples into different treatment groups. This simulation is based on the actual user network of GCP.
Sandeep Davé knows the value of experimentation as well as anyone. As chief digital and technology officer at CBRE, Davé recognized early that the commercial real estate industry was ripe for AI and machine learning enhancements, and he and his team have tested countless use cases across the enterprise ever since.
While tech debt refers to shortcuts taken in implementation that need to be addressed later, digital addiction results in the accumulation of poorly vetted, misused, or unnecessary technologies that generate costs and risks. Implement robust testing: As the CrowdStrike incident demonstrated, thorough testing is crucial.
To find optimal values of two parameters experimentally, the obvious strategy would be to experiment with and update them in separate, sequential stages. Our experimentation platform supports this kind of grouped-experiments analysis, which allows us to see rough summaries of our designed experiments without much work.
ML model builders spend a ton of time running multiple experiments in a data science notebook environment before moving the well-tested and robust models from those experiments to a secure, production-grade environment for general consumption. Capabilities Beyond Classic Jupyter for End-to-end Experimentation. Auto-scale compute.
This post considers a common design for an OCE where a user may be randomly assigned an arm on their first visit during the experiment, with assignment weights referring to the proportion that are randomly assigned to each arm. There are two common reasons assignment weights may change during an OCE.
Pilots can offer value beyond just experimentation, of course. McKinsey reports that industrial design teams using LLM-powered summaries of user research and AI-generated images for ideation and experimentation sometimes see a reduction upward of 70% in product development cycle times.
Test the feature To test this feature, run the producer DAG. Removal of experimental Smart Sensors. How dynamic task mapping works Let’s see an example using the reference code available in the Airflow documentation. Test the feature Upload the four sample text files from the local data folder to an S3 bucket data folder.
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Testing out a new feature. Identify, hypothesize, test, react. But at the same time, they had to have a real test of an actual feature. You don’t need a beautiful beast to go out and test.
Deploy a dense vector model To get more valuable test results, we selected Cohere-embed-multilingual-v3.0 , which is one of several popular models used in production for dense vectors. Experimental data selection For retrieval evaluation, we used to use the datasets from BeIR. How to combine dense and sparse?
The challenge with this approach is that companies end up in what we refer to as the ‘digital trap. Our internal QA team now focuses 100% on automated testing and managing the queue from the crowdsourced operation. IT’s approach is to launch betas, test and learn from them, then improve and offer more features and capabilities.
Though some regulators will collect some incident reports, we find that this is not likely to capture the novel harms posed by frontier AI,” it said, referring to the high-powered generative AI models at the cutting edge of the industry.
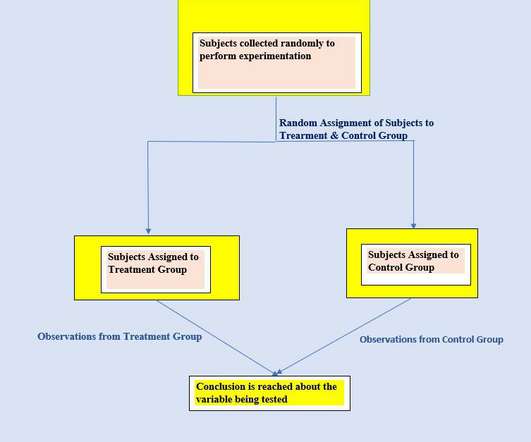
Researchers/ scientists perform experiments to validate their hypothesis/ statements or to test a new product. Suppose we want to test the effectiveness of a new drug against a particular disease. Bias can cause a huge error in experimentation results so we need to avoid them. REFERENCES. McCabe & B.
Just so we have a visual guide through this learning process, let's use the above image as a reference. So, the campaign could be Social, Organic Search, Email, Display, Affiliate, Referring Site … anything really. Look up, memorize the steps to conversion. Last Interaction/Last Click Attribution model. Or we could not.)
Major market indexes, such as S&P 500, are subject to periodic inclusions and exclusions for reasons beyond the scope of this post (for an example, refer to CoStar Group, Invitation Homes Set to Join S&P 500; Others to Join S&P 100, S&P MidCap 400, and S&P SmallCap 600 ). Load the dataset into Amazon S3.
A/B testing is used widely in information technology companies to guide product development and improvements. For questions as disparate as website design and UI, prediction algorithms, or user flows within apps, live traffic tests help developers understand what works well for users and the business, and what doesn’t.
And I refer to internal stakeholders rather than internal customers just to change that dynamic and relationship to one of partnering rather than order taking. I want to make sure we carve off some capacity for experimentation, too, and the approach I think we’ll take is starting small. So test, learn, and scale from there.
A new drug promising to reduce the risk of heart attack was tested with two groups. Continuing the previous example, let’s assume that blood pressure is known to be a cause for heart attack and the goal of the test drug is to reduce blood pressure. It really depends on the circumstances. Combined 13/60 = 21.67% 11/60 = 18.3%.
Manufacturing production errors refer to mistakes or defects that occur during the manufacturing process. DataOps Observability refers to real-time monitoring, detecting, and diagnosing of data status, data pipelines, data tools, and other systems. BI tools like Tableau, PowerBI, etc.). It’s not because they trust the newbies.
Additionally, BPG has not been tested with the Volcano scheduler , and the solution is not applicable in environments using native Amazon EMR on EKS APIs. For comprehensive instructions, refer to Running Spark jobs with the Spark operator. For official guidance, refer to Create a VPC. Refer to create-db-cluster for more details.
This led to the problem we, Marketers, SEOs, Analysts, fondly refer to as not provided. That of course will mean more referring keyword data will disappear. We are headed towards having zero referring keywords from Google and, perhaps, other search engines. Implications of Secure Search Decision. I would humbly suggest not.
so you have some reference as to where each item fits (and this will also make it easier for you to pick tools for the priority order referenced in Context #3 above). If you have evolved to a stage that you need behavior targeting then get Omniture Test and Target or Sitespect. Experimentation and Testing Tools [The "Why" – Part 1].
Oliver Wittmaier, CIO and product owner at DB SYSTEL GmbH DB SYSTEL GmbH Content generation is also an area of particular interest to Michal Cenkl, director of innovation and experimentation at Mitre Corp. “I Michal Cenkl, director of innovation and experimentation, Mitre Corp. Mitre Corp. The technology also needs human oversight.
We collect all the clickstream data and the objective is to analyze it from a higher plane of reference. I am a huge believer of experimentation and testing (let’s have the customers tell us what they prefer). Doing Lab Usability testing is another great option. No more measuring HITS. There are surveys you can do.
For specific pricing details and current information, refer to Amazon EMR pricing. AWS benchmark The AWS team performed benchmark tests on Spark workloads with Graviton2 on EMR Serverless using the TPC-DS 3 TB scale performance benchmarks. Gather relevant metrics from the tests. In another instance, we achieved an impressive 43.7%
To learn more about semantic search and cross-modal search and experiment with a demo of the Compare Search Results tool, refer to Try semantic search with the Amazon OpenSearch Service vector engine. To learn more, refer to Byte-quantized vectors in OpenSearch. With the new byte vector feature in OpenSearch Service version 2.9,
Data scientists require on-demand access to data, powerful processing infrastructure, and multiple tools and libraries for development and experimentation. Run experiments with historical reference for hyperparameter tuning, feature engineering, grid searches, A/B testing and more. Sound familiar?
We use the diagnostic test results of our regression model to support the reasons why CIs should not be used in financial data analyses. As the number of experimental trials N approaches infinity, the probability of E equals M/N. Specifically, the Bera-Jarque and Omnibus normality tests show the probability that the residuals ??
This should drive aggressive experimentation of email content / offers / targeting / every facet by your team. This metric helps you find opportunities for immediate improvement – such as pages and calls to action you should test, and content that fails to deliver. Oh, and don’t forget to segment it like crazy.
In a two-part series, we talk about Swisscom’s journey of automating Amazon Redshift provisioning as part of the Swisscom ODP solution using the AWS Cloud Development Kit (AWS CDK), and we provide code snippets and the other useful references. See the following admin user code: admin_secret_kms_key_options = KmsKeyOptions(.
For example, AI-supported chat tools help our game designers to: Brainstorm ideas Test complex game mechanics Generate dialogs They act as digital sparring partners that open up new perspectives and accelerate the creative process. AI does not always deliver the final result, but it is a good starting point for brainstorming.
" Or " I proposed testing / surveys / competitive intelligence / Analysts but I was shot down." 1: Implement a Experimentation & Testing Program. # 1: Implement a Experimentation & Testing Program. Here is data from our latest test." And now you have no excuse to avoid testing.
Enterprises also need to think about how they’ll test these systems to ensure they’re performing as intended. But multiagent AI systems are still in the experimental stages, or used in very limited ways. That’s the most difficult thing,” he says. But agentic AI systems are designed to operate with a certain level of autonomy, he says.
Machine learning projects are inherently different from traditional IT projects in that they are significantly more heuristic and experimental, requiring skills spanning multiple domains, including statistical analysis, data analysis and application development. The challenge has been figuring out what to do once the model is built.
M-LLMs for Image Captioning Image captioning refers to the process of automatically generating textual descriptions or captions for images. One limitation observed while testing the LENS approach, particularly in VQA, is its heavy reliance on the output of the first modules, namely CLIP and BLIP captions.
For more information, refer to Retry Amazon S3 requests with EMRFS. To learn more about how to create an EMR cluster with Iceberg and use Amazon EMR Studio, refer to Use an Iceberg cluster with Spark and the Amazon EMR Studio Management Guide , respectively. AIMD is supported for Amazon EMR releases 6.4.0 Delete the EMR cluster.
Your current customers refer your products and services to their friends, family, and complete strangers—in exchange for a little benefit for themselves. Diana, of course, referred the product to you, and that insight is in the URL you used to get to the site. Such is the case with A/B testing. Why not use it?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content