This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Some important considerations: For implementing dbt modeling on Athena, refer to the dbt-on-aws / athena GitHub repository for experimentation For implementing dbt modeling on Amazon Redshift, refer to the dbt-on-aws / redshift GitHub repository for experimentation.
ML apps need to be developed through cycles of experimentation: due to the constant exposure to data, we don’t learn the behavior of ML apps through logical reasoning but through empirical observation. Besides infrastructure, effective A/B testing requires a control plane, a modern experimentation platform, such as StatSig. Versioning.
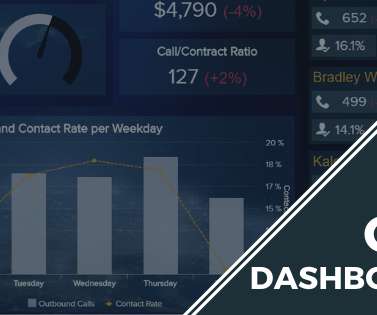
Additionally, CRM dashboard tools provide access to insights that offer a concise snapshot of your customer-driven performance and activities through a range of features and functionalities empowered by online data visualization tools. Your Chance: Want to build professional CRM reports & dashboards?
Iceberg tags – The Iceberg branching and tagging feature allows users to tag specific snapshots of their data tables with meaningful labels using SQL syntax or the Iceberg library, which correspond to specific events notable to internal investment teams. Tag this data to preserve a snapshot of it. Configure a Spark session.
E.g., use the snapshot-restore feature to quickly create a green experimental cluster from an existing blue serving cluster. By combining Redshift’s scalability, snapshots, workload management, and low-operational approach, Gupshup provides data-driven insights in less than 15 minutes analytics refresh rate.
The following examples are also available in the sample notebook in the aws-samples GitHub repo for quick experimentation. In that case, we have to query the table with the snapshot-id corresponding to the deleted row. We expire the old snapshots from the table and keep only the last two.
Additionally, partition evolution enables experimentation with various partitioning strategies to optimize cost and performance without requiring a rewrite of the table’s data every time. Furthermore, Apache Iceberg’s time travel feature provides the ability to review a table’s history and roll back to a previous snapshot.
The utility for cloning and experimentation is available in the open-sourced GitHub repository. The on-demand mode is a batch replication that takes a snapshot of the metadata at a specific point in time and uses it to synchronize the metadata. These mechanisms can be customized for your organization’s processes.
or later supports change data capture as an experimental feature, which is only available for Copy-on-Write (CoW) tables. csv has historical records for record ID='AE000041196' from 20220101 to 20221231 ; however, the query result shows only four records, one record per ELEMENT at the latest snapshot of the day 20221230 or 20221231.
It offers an extensive array of features making experimentation, reproducibility, and collaboration across the data science life cycle easy to manage, helping organizations to work faster, deploy results sooner and scale data science across the entire enterprise. Domino Data Lab is the system-of-record for enterprise data science teams.
They ingest data in snapshots from operational systems. Next, they build model data sets out of the snapshots, cleanse and deduplicate the data, and prepare it for analysis as Parquet files. Data Exploration and Innovation: The flexibility of Presto has encouraged data exploration and experimentation at Uber.
In every Apache Flink release, there are exciting new experimental features. Extending checkpoint intervals allows Apache Flink to prioritize processing throughput over frequent state snapshots, thereby improving efficiency and performance. Connectors With the release of version 1.19.1,
And up until recently, the lab tests were relatively simple, point-in-time snapshots of a single quantitative result. Around 2015, Next-Generation Sequencing (NGS) became an accepted diagnostic tool with data capture that was more complex than a simple point-in-time snapshot.
Spark Structured Streaming continuous processing is an experimental feature and provides at-least once guarantees. It handles core capabilities like provisioning compute resources, parallel computation, automatic scaling , and application backups (implemented as checkpoints and snapshots).
For example, a single source of truth like your customer master might have had some basic access controls in place, but one of its administrators agreed take a snapshot of that data and share with a marketing analyst team (for example), and it’s their BI tool that got breached.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content