This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
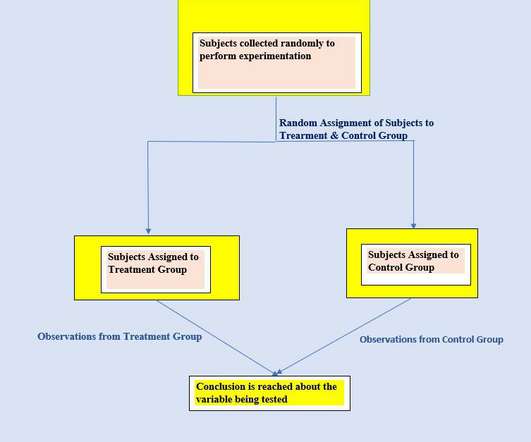
This article was published as a part of the Data Science Blogathon Introduction to StatisticsStatistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimental data or real-world studies. Data processing is […].
To counter such statistics, CIOs say they and their C-suite colleagues are devising more thoughtful strategies. The time for experimentation and seeing what it can do was in 2023 and early 2024. At Vanguard, we are focused on ethical and responsible AI adoption through experimentation, training, and ideation, she says.
This post is a primer on the delightful world of testing and experimentation (A/B, Multivariate, and a new term from me: Experience Testing). Experimentation and testing help us figure out we are wrong, quickly and repeatedly and if you think about it that is a great thing for our customers, and for our employers. Counter claims?
— Thank you to Ann Emery, Depict Data Studio, and her Simple Spreadsheets class for inviting us to talk to them about the use of statistics in nonprofit program evaluation! But then we realized that much of the time, statistics just don’t have much of a role in nonprofit work. Why Nonprofits Shouldn’t Use Statistics.
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. The need for an experimental culture implies that machine learning is currently better suited to the consumer space than it is to enterprise companies.
It can even be used for controlled experimentation, assuming you can make it accurate enough. Accurate amplification Created properly, synthetic data mimics statistical properties and patterns of real-world data without containing actual records from the original dataset, says Jarrod Vawdrey, field chief data scientist at Domino Data Lab.
Other organizations are just discovering how to apply AI to accelerate experimentation time frames and find the best models to produce results. Bureau of Labor Statistics predicts that the employment of data scientists will grow 36 percent by 2031, 1 much faster than the average for all occupations. Bureau of Labor Statistics.
The tools include sophisticated pipelines for gathering data from across the enterprise, add layers of statistical analysis and machine learning to make projections about the future, and distill these insights into useful summaries so that business users can act on them. A free plan allows experimentation. On premises or in SAP cloud.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. And we can keep repeating this approach, relying on intuition and luck. Why experiment with several parameters concurrently?
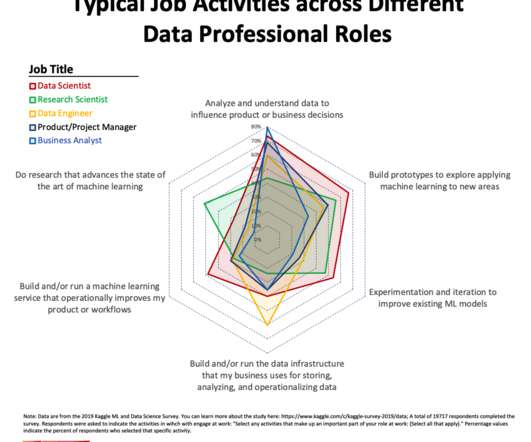
Experimentation and iteration to improve existing ML models (39%). In prior research, I found that data professionals who self-identified as Researchers have a strong math/statistics/research skill set. The entire list of activities (shown in Figure 1) were: Analyze and understand data to influence product or business decisions (63%).
Right now most organizations tend to be in the experimental phases of using the technology to supplement employee tasks, but that is likely to change, and quickly, experts say.
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown. One reason to do ramp-up is to mitigate the risk of never before seen arms.
It seems as if the experimental AI projects of 2019 have borne fruit. data cleansing services that profile data and generate statistics, perform deduplication and fuzzy matching, etc.—or This year, about 15% of respondent organizations are not doing anything with AI, down ~20% from our 2019 survey. But what kind?
Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature. Among these, only statistical uncertainty has formal recognition.
The US Bureau of Labor Statistics (BLS) forecasts employment of data scientists will grow 35% from 2022 to 2032, with about 17,000 openings projected on average each year. You should also have experience with pattern detection, experimentation in business optimization techniques, and time-series forecasting.
Computer Vision: Data Mining: Data Science: Application of scientific method to discovery from data (including Statistics, Machine Learning, data visualization, exploratory data analysis, experimentation, and more). They cannot process language inputs generally. Examples: (1) Automated manufacturing assembly line. (2) 4) Prosthetics.
Some pitfalls of this type of experimentation include: Suppose an experiment is performed to observe the relationship between the snack habit of a person while watching TV. Bias can cause a huge error in experimentation results so we need to avoid them. Statistics Essential for Dummies by D. REFERENCES. McCabe & B.
Candidates are required to complete a minimum of 12 credits, including four required courses: Algorithms for Data Science, Probability and Statistics for Data Science, Machine Learning for Data Science, and Exploratory Data Analysis and Visualization.
For teams that want to boil down their own data into predictive tools, Model Builder will turn all those records of past purchases sitting in the data lake into a big statistical hair ball of tendencies that passes for an AI these days. Salesforce is pushing the idea that Einstein 1 is a vehicle for experimentation and iteration.
. – Head First Data Analysis: A learner’s guide to big numbers, statistics, and good decisions. The big news is that we no longer need to be proficient in math or statistics, or even rely on expensive modeling software to analyze customers. By Michael Milton. – Data Divination: Big Data Strategies.
Once we get more data from across a couple of areas into Mquiry, I would love to see the insights it might show us and do some training against that data.
According to William Chen, Data Science Manager at Quora , the top five skills for data scientists include a mix of hard and soft skills: Programming: The “most fundamental of a data scientist’s skill set,” programming improves your statistics skills, helps you “analyze large datasets,” and gives you the ability to create your own tools, Chen says.
He plans to scale his company’s experimental generative AI initiatives “and evolve into an AI-native enterprise” in 2024. But at the end of the day, it boils down to statistics. Statistics can be very misleading. That’s the case for Yi Zhou, CTO and CIO with Adaptive Biotechnologies.
You need people with deep skills in Scientific Method , Design of Experiments , and Statistical Analysis. The team did the normal modeling to ensure that the results were statistically significant (large enough sample set, sufficient number of conversions in each variation). * ask for a raise. It is that simple. Okay, it is not simple.
Advanced Data Discovery ensures data democratization and can drastically reduce the time and cost of analysis and experimentation. A business user with average skills can do all of this without specialized skills, knowledge of statistical analysis or support from IT or professional data scientists.
This is an example of Simpon’s paradox , a statistical phenomenon in which a trend that is present when data is put into groups reverses or disappears when the data is combined. It’s time to introduce a new statistical term. So how do we get totally different results when breaking the data down by gender? See Kievit, Rogier, et al. ).
A 1958 Harvard Business Review article coined the term information technology, focusing their definition on rapidly processing large amounts of information, using statistical and mathematical methods in decision-making, and simulating higher order thinking through applications.
After completing MTech from Indian Statistical Institute, I started my career at Cognizant. What do you do to foster a culture of innovation and experimentation in your employees? Only experimentation can help to improve this index. Overall, my career has spanned 20 years. This is what makes the job most interesting.
Two years later, I published a post on my then-favourite definition of data science , as the intersection between software engineering and statistics. Like other authors, they argue that causal inference has been neglected by traditional statistics and some scientific disciplines. In a recent article , Hernán et al.
Remember that the raw number is not the only important part, we would also measure statistical significance. Advanced Analytics Big Data Digital Analytics Web Analytics Web Insights Web Metrics actionable analytics business optimization experimentation and testing key performance indicators' The result? The graph is impressive, right?
Not actually being a machine learning problem: Value-at-Risk modeling is the classic example here—VaR isn’t a prediction of anything, it’s a statistical summation of simulation results. As discussed, we massively accelerate that process of experimentation.
Common elements of DataOps strategies include: Collaboration between data managers, developers and consumers A development environment conducive to experimentation Rapid deployment and iteration Automated testing Very low error rates. Issue detected?
In addition, Jupyter Notebook is also an excellent interactive tool for data analysis and provides a convenient experimental platform for beginners. Pandas incorporates a large number of analysis function methods, as well as common statistical models and visualization processing. From Google. Data Analysis Libraries.
As Belcorp considered the difficulties it faced, the R&D division noted it could significantly expedite time-to-market and increase productivity in its product development process if it could shorten the timeframes of the experimental and testing phases in the R&D labs.
And it can look up an author and make statistical observations about their interests. ChatGPT offers users a paid account that costs $20/month, which is good enough for experimenters, though there is a limit on the number of requests you can make. Again, ChatGPT is predicting a response to your question.
The flashpoint moment is that rather than being based on rules, statistics, and thresholds, now these systems are being imbued with the power of deep learning and deep reinforcement learning brought about by neural networks,” Mattmann says. But multiagent AI systems are still in the experimental stages, or used in very limited ways.
As such, data science requires three broad skill sets , including subject matter expertise, statistics/math and technology/programming. Experimentation and iteration to improve existing ML models (25%). The practice of data science is about extracting value from data to help inform decision making and improve algorithms.
In every Apache Flink release, there are exciting new experimental features. You can find valuable statistics you can’t normally find elsewhere, including the Apache Flink Dashboard. However, in this post, we are going to focus on the features most accessible to the user with this release.
This group of solutions targets code-first data scientists who use statistical programming languages and spend their days in computational notebooks (e.g., While these solutions offer great breadth of functionality, users must leverage the proprietary user interfaces or programming languages to express their logic. Jupyter) or IDEs (e.g.,
As a statistical model, LLM inherently is random. Experimentation is important, but be explicit when you do. So, we’ve learned our lesson. AI will solve it We’ve seen a massive increase in interest in LLMs and ‘AI’ But LLM without guide rails could lead to unbridled hallucinations. Start with “why?”
Machine learning projects are inherently different from traditional IT projects in that they are significantly more heuristic and experimental, requiring skills spanning multiple domains, including statistical analysis, data analysis and application development.
Initially, the customer tried modeling using statistical methods to create typical features, such as moving averages, but the model metrics (R-square) was only 0.5 The first baseline model we created used spectrograms of speech waveform data, statistical features, and spectrogram images. This approach got us to an R-squared of 0.7,
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Yet, this challenge is not insurmountable. for what is and isn’t possible) to address these challenges.
Advanced Data Discovery ensures data democratization by enabling users to drastically reduce the time and cost of analysis and experimentation. Plug n’ Play Predictive Analysis enables business users to explore power of predictive analytics without indepth understanding of statistics and data science.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content