This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
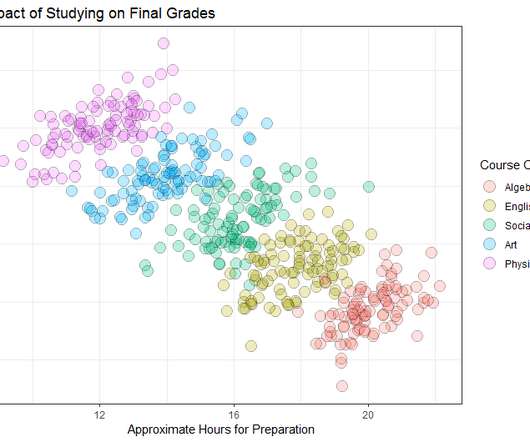
This article was published as a part of the Data Science Blogathon Introduction to StatisticsStatistics is a type of mathematical analysis that employs quantified models and representations to analyse a set of experimental data or real-world studies. Data processing is […].
Since you're reading a blog on advanced analytics, I'm going to assume that you have been exposed to the magical and amazing awesomeness of experimentation and testing. And yet, chances are you really don’t know anyone directly who uses experimentation as a part of their regular business practice. Wah wah wah waaah.
This post is a primer on the delightful world of testing and experimentation (A/B, Multivariate, and a new term from me: Experience Testing). Experimentation and testing help us figure out we are wrong, quickly and repeatedly and if you think about it that is a great thing for our customers, and for our employers.
Product Managers are responsible for the successful development, testing, release, and adoption of a product, and for leading the team that implements those milestones. Without clarity in metrics, it’s impossible to do meaningful experimentation. Ongoing monitoring of critical metrics is yet another form of experimentation.
There is a tendency to think experimentation and testing is optional. Just don't fall for their bashing of all other vendors or their silly claims, false, of "superiority" in terms of running 19 billion combinations of tests or the bonus feature of helping you into your underwear each morning. And I meant every word of it.
— Thank you to Ann Emery, Depict Data Studio, and her Simple Spreadsheets class for inviting us to talk to them about the use of statistics in nonprofit program evaluation! But then we realized that much of the time, statistics just don’t have much of a role in nonprofit work. Why Nonprofits Shouldn’t Use Statistics.
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. This has serious implications for software testing, versioning, deployment, and other core development processes. Machine learning adds uncertainty.
Large banking firms are quietly testing AI tools under code names such as as Socrates that could one day make the need to hire thousands of college graduates at these firms obsolete, according to the report.
We develop an ordinary least squares (OLS) linear regression model of equity returns using Statsmodels, a Python statistical package, to illustrate these three error types. We use the diagnostic test results of our regression model to support the reasons why CIs should not be used in financial data analyses. and an error term ??
The US Bureau of Labor Statistics (BLS) forecasts employment of data scientists will grow 35% from 2022 to 2032, with about 17,000 openings projected on average each year. Candidates for the exam are tested on ML, AI solutions, NLP, computer vision, and predictive analytics.
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. And we can keep repeating this approach, relying on intuition and luck. Why experiment with several parameters concurrently?
Researchers/ scientists perform experiments to validate their hypothesis/ statements or to test a new product. Suppose we want to test the effectiveness of a new drug against a particular disease. Bias can cause a huge error in experimentation results so we need to avoid them. Statistics Essential for Dummies by D.
You need people with deep skills in Scientific Method , Design of Experiments , and Statistical Analysis. Then they isolated regions of the country (by city, zip, state, dma pick your fave) into test and control regions. People in the test regions will participate in our hypothesis testing. ask for a raise.
It’s by far the most convincing example of a conversation with a machine; it has certainly passed the Turing test. And it can look up an author and make statistical observations about their interests. Search and research Microsoft is currently beta testing Bing/Sydney, which is based on GPT-4.
Five Reasons And Awesome Testing Ideas. Lab Usability Testing: What, Why, How Much. Build A Great Web Experimentation & Testing Program. Experimentation and Testing: A Primer. Tip #9: Leverage Statistical Control Limits. Tip#1: Statistical Significance. Got Surveys? Got Surveys?
We present data from Google Cloud Platform (GCP) as an example of how we use A/B testing when users are connected. Experimentation on networks A/B testing is a standard method of measuring the effect of changes by randomizing samples into different treatment groups. This simulation is based on the actual user network of GCP.
Organization: AWS Price: US$300 How to prepare: Amazon offers free exam guides, sample questions, practice tests, and digital training. The exam tests general knowledge of the platform and applies to multiple roles, including administrator, developer, data analyst, data engineer, data scientist, and system architect.
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Testing out a new feature. Identify, hypothesize, test, react. But at the same time, they had to have a real test of an actual feature. You don’t need a beautiful beast to go out and test.
Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature. Among these, only statistical uncertainty has formal recognition. Should we use a t-test or a sign test?
This is an example of Simpon’s paradox , a statistical phenomenon in which a trend that is present when data is put into groups reverses or disappears when the data is combined. It’s time to introduce a new statistical term. A new drug promising to reduce the risk of heart attack was tested with two groups.
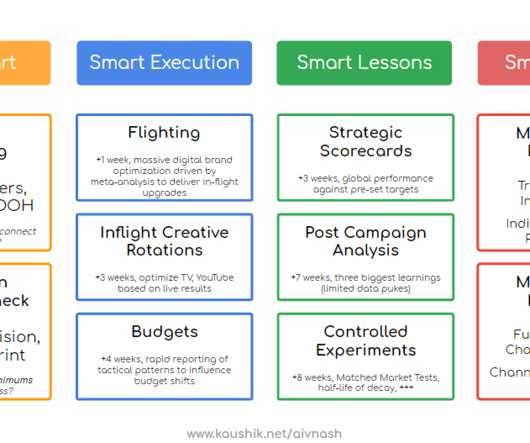
This is very hard to do, we now have a proven seven-step experimentation process, with one of the coolest algorithms to pick matched-markets (normally the kiss of death of any large-scale geo experiment). The first component is a gloriously scaled global creative pre-testing program. Matched market tests. The slow music.
. – Head First Data Analysis: A learner’s guide to big numbers, statistics, and good decisions. The big news is that we no longer need to be proficient in math or statistics, or even rely on expensive modeling software to analyze customers. By Michael Milton. – Data Divination: Big Data Strategies.
As Belcorp considered the difficulties it faced, the R&D division noted it could significantly expedite time-to-market and increase productivity in its product development process if it could shorten the timeframes of the experimental and testing phases in the R&D labs. This allowed us to derive insights more easily.”
Part of it is fueled by a vocal minority genuinely upset that 10 years on we are still not a statistically powered bunch doing complicated analysis that is shifting paradigms. Usually at least a test. Meanwhile see if you can convince your HiPPO to run a small test while you look for a case study (and a job). ]. Likely not.
Common elements of DataOps strategies include: Collaboration between data managers, developers and consumers A development environment conducive to experimentation Rapid deployment and iteration Automated testing Very low error rates. Issue detected? This means that more focused development can happen faster. .
A 1958 Harvard Business Review article coined the term information technology, focusing their definition on rapidly processing large amounts of information, using statistical and mathematical methods in decision-making, and simulating higher order thinking through applications.
Although modern medicine is founded on rigorous experimental design and statistical analysis, and many research studies have shown the superiority of objective analysis over human intuition, medical AI adoption will depend on consumer receptivity and trust in this new technology.
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Yet, this challenge is not insurmountable. for what is and isn’t possible) to address these challenges. Transcript.
Look – ahead bias – This is a common challenge in backtesting, which occurs when future information is inadvertently included in historical data used to test a trading strategy, leading to overly optimistic results. Solution overview To set up and test this experiment, we complete the following high-level steps: Create an S3 bucket.
The flashpoint moment is that rather than being based on rules, statistics, and thresholds, now these systems are being imbued with the power of deep learning and deep reinforcement learning brought about by neural networks,” Mattmann says. But multiagent AI systems are still in the experimental stages, or used in very limited ways.
Unlike experimentation in some other areas, LSOS experiments present a surprising challenge to statisticians — even though we operate in the realm of “big data”, the statistical uncertainty in our experiments can be substantial. We must therefore maintain statistical rigor in quantifying experimental uncertainty.
by MICHAEL FORTE Large-scale live experimentation is a big part of online product development. This means a small and growing product has to use experimentation differently and very carefully. This blog post is about experimentation in this regime. Such decisions involve an actual hypothesis test on specific metrics (e.g.
As a statistical model, LLM inherently is random. With things like named graphs, layering the data, testing those what-if scenarios, and checking the state is fantastic. We find that as great as SHACL is at ensuring the data quality, testing the RDF pipelines is another matter. So, we’ve learned our lesson.
When DataOps principles are implemented within an organization, you see an increase in collaboration, experimentation, deployment speed and data quality. Continuous pipeline monitoring with SPC (statistical process control). SPC is the continuous testing of the results of automated manufacturing processes. Let’s take a look.
” Given the statistics—82% of surveyed respondents in a 2023 Statista study cited managing cloud spend as a significant challenge—it’s a legitimate concern. With this organizational change, new teams are being defined, agile project groups created and feedback and testing loops established.
Machine learning projects are inherently different from traditional IT projects in that they are significantly more heuristic and experimental, requiring skills spanning multiple domains, including statistical analysis, data analysis and application development. The challenge has been figuring out what to do once the model is built.
Additionally, BPG has not been tested with the Volcano scheduler , and the solution is not applicable in environments using native Amazon EMR on EKS APIs. We expect statistically equal distribution of jobs between the two clusters. contains(GroupName, 'eks-cluster-sg-bpg-cluster-')].GroupId" contexts[] | select(.name
I mean developing and inserting a subtle collection of gentle nudges that can help increase the conversion rate by a statistically significant amount. Such is the case with A/B testing. I don’t mean: BUY IT NOW OR ELSE! Sizing the Opportunity. I still do it less than I should. The tools are free and abundant. Yet, you don’t use them.
They also require advanced skills in statistics, experimental design, causal inference, and so on – more than most data science teams will have. Agile was originally about iterating fast on a code base and its unit tests, then getting results in front of stakeholders. evaluate the effects of models on human subjects.
Hypothesis development and design of experimentation. Ok, maybe statistical modeling smells like an analytical skill. If these 50 pass the sniff test, send the survey. Don't repeat things for years without constantly stress-testing for reality. . + Pattern recognition and understanding trends. Take 10 mins each.
AND you can have analysis of your risk in almost real time to get an early read and in a few days with statistical significance! Allocate some of your aforementioned 15% budget to experimentation and testing. You can literally control for risk should everything blow up in your face. Consider rewarding people with new ideas.
At the end of the semester, you administer a proficiency test to the students and compare test performance across the groups. For example, you might compare the average test score among students exposed to the new curriculum to the average score among the controls. Sounds straightforward, right?
This control prevents overfitting and reduction in predictive accuracy on new test data. If we don’t like the result of testing after training, we can also select an entirely different learning machine with different internals. We can take this model to other, novel data and perform a final hold-out test assessment.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content