This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Because Amazon DataZone integrates the data quality results, by subscribing to the data from Amazon DataZone, the teams can make sure that the data product meets consistent quality standards. This agility accelerates EUROGATEs insight generation, keeping decision-making aligned with current data.
The data that data scientists analyze draws from many sources, including structured, unstructured, or semi-structureddata. The more high-quality data available to data scientists, the more parameters they can include in a given model, and the more data they will have on hand for training their models.
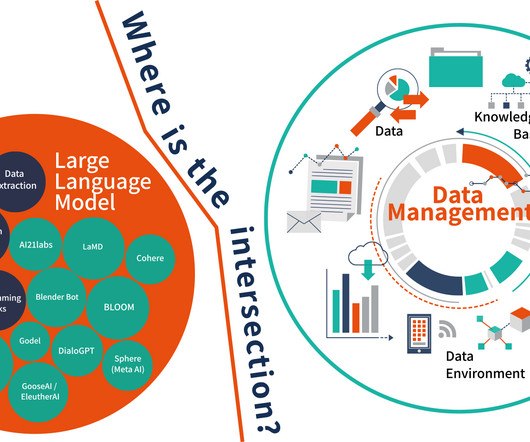
Along with code-generating copilots and text-to-image generators, which leverage a combination of LLMs and diffusion processing, LLMs are at the core of most generative AI experimentation in business today. Instead, MakeShift is embracing what is being dubbed a new patent-pending large graphical model (LGM) from MIT startup Ikigai Labs.
Computer Vision: Data Mining: Data Science: Application of scientific method to discovery from data (including Statistics, Machine Learning, data visualization, exploratory data analysis, experimentation, and more). NLG is a software process that transforms structureddata into human-language content.
Start with StructuredData The ideal way to experiment with LLM functionality is to focus on structureddata at the start. Cleaning, refining, and aligning your data to shared meaning is the right strategic approach. I am personally excited about the intersection of LLM and semantic standards ( knowledge graph ).
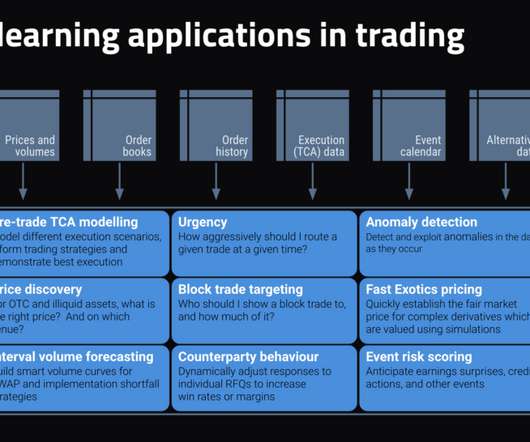
establishing an appropriate price illiquid securities, predicting where liquidity will be located, and determining appropriate hedge ratios) as well as more generally: the existence of good historical trade data on the assets to be priced (e.g., As discussed, we massively accelerate that process of experimentation.
We use Snowflake very heavily as our primary data querying engine to cross all of our distributed boundaries because we pull in from structured and non-structureddata stores and flat objects that have no structure,” Frazer says. “We think we found a good balance there.
Create a Sandbox Environment If you are in the business of technology, you probably have a robust sandbox environment in which you can use new tools and leverage opportunities with test data to understand the value of tools like Azure OpenAI, GPT 3.x Creating Summary Data for Unstructured Documents (PDFs, HTML, Websites, etc.)
If you ask it to generate a response, and maybe it hallucinates, you can then constrain the response it gives you, from the well-curated data in your graph. Data quality Knowledge graphs thrive on clean, well-structureddata, and they rely on accurate relationships and meaningful connections. Start with “why?”
Ever since Hippocrates founded his school of medicine in ancient Greece some 2,500 years ago, writes Hannah Fry in her book Hello World: Being Human in the Age of Algorithms , what has been fundamental to healthcare (as she calls it “the fight to keep us healthy”) was observation, experimentation and the analysis of data.
This shift of both a technical and an outcome mindset allows them to establish a centralized metadata hub for their data assets and effortlessly access information from diverse systems that previously had limited interaction. There are four groups of data that are naturally siloed: Structureddata (e.g.,
A discovery data warehouse is a modern data warehouse that easily allows for augmentation of existing reports and structureddata with new unstructured data types, and that can flexibly scale with volume and compute needs.
This shift from relational to graph approach has been well-documented by Gartner who advise that “using graph techniques at scale will form the foundation of modern data and analytics” and “graph technologies will be used in 80% of data and analytics innovations by 2025.”
Emotional Appeal : Infusing narratives with emotional elements helps in establishing connections with the audience, eliciting empathy, and driving home the significance of the data being presented. Experimenting with new tools broadens your skill set and enables you to stay at the forefront of data visualization trends.
This makes sense, given that we don’t see heavy usage of tools for model and data versioning. We’ll look at this later, but being able to reproduce experimental results is critical to any science, and it’s a well-known problem in AI. We also asked what kinds of data our “mature” respondents are using. form data).
It definitely depends on the type of data, no one method is always better than the other. For a large volume of structureddata, for example, a customer master or data warehouse, where there are many stakeholders in your organization who need to see different subsets, tokenization is generally better.
But for more complex business decisions, including those that use less structureddata, we have artificial intelligence systems. Data scientists train the algorithms using datasets that contain curated learning examples. For well-defined business processes, we have conventional computer systems.
A large oil and gas company was suffering over not being able to offer users an easy and fast way to access the data needed to fuel their experimentation. To address this, they focused on creating an experimentation-oriented culture, enabled thanks to a cloud-native platform supporting the full data lifecycle.
Building a RAG prototype is relatively easy, but making it production-ready is hard with organizations routinely getting stuck in experimentation mode. Out of the box RAG struggles to connect dots, for questions that require traversing disparate chunks of data. GraphDB allows experimentation and optimization of the different tasks.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content