This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. What breaks your app in production isnt always what you tested for in dev! The way out?
Those F’s are: Fragility, Friction, and FUD (Fear, Uncertainty, Doubt). encouraging and rewarding) a culture of experimentation across the organization. Keep it agile, with short design, develop, test, release, and feedback cycles: keep it lean, and build on incremental changes. Test early and often. Launch the chatbot.
Machine learning adds uncertainty. This has serious implications for software testing, versioning, deployment, and other core development processes. Underneath this uncertainty lies further uncertainty in the development process itself. Models within AI products change the same world they try to predict.
Technical competence results in reduced risk and uncertainty. Results are typically achieved through a scientific process of discovery, exploration, and experimentation, and these processes are not always predictable. There’s a lot of overlap between these factors.
In Bringing an AI Product to Market , we distinguished the debugging phase of product development from pre-deployment evaluation and testing. During testing and evaluation, application performance is important, but not critical to success. require not only disclosure, but also monitored testing. Debugging AI Products.
Pete indicates, in both his November 2018 and Strata London talks, that ML requires a more experimental approach than traditional software engineering. It is more experimental because it is “an approach that involves learning from data instead of programmatically following a set of human rules.”
Crucially, it takes into account the uncertainty inherent in our experiments. To find optimal values of two parameters experimentally, the obvious strategy would be to experiment with and update them in separate, sequential stages. In this section we’ll discuss how we approach these two kinds of uncertainty with QCQP.
by AMIR NAJMI & MUKUND SUNDARARAJAN Data science is about decision making under uncertainty. Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature.
Because of this trifecta of errors, we need dynamic models that quantify the uncertainty inherent in our financial estimates and predictions. Practitioners in all social sciences, especially financial economics, use confidence intervals to quantify the uncertainty in their estimates and predictions.
Another reason to use ramp-up is to test if a website's infrastructure can handle deploying a new arm to all of its users. The website wants to make sure they have the infrastructure to handle the feature while testing if engagement increases enough to justify the infrastructure. We offer two examples where this may be the case.
How can enterprises attain these in the face of uncertainty? Rogers: This is one of two fundamental challenges of corporate innovation — managing innovation under high uncertainty and managing innovation far from the core — that I have studied in my work advising companies and try to tackle in my new book The Digital Transformation Roadmap.
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Testing out a new feature. Identify, hypothesize, test, react. But at the same time, they had to have a real test of an actual feature. You don’t need a beautiful beast to go out and test.
Intuitively, for some extremely short user inputs, the vectors generated by dense vector models might have significant semantic uncertainty, where overlaying with a sparse vector model could be beneficial. Experimental data selection For retrieval evaluation, we used to use the datasets from BeIR. How to combine dense and sparse?
The use of AI-generated code is still in an experimental phase for many organizations due to numerous uncertainties such as its impact on security, data privacy, copyright, and more. Best practices and education Currently, there are no established best practices for leveraging AI in software development.
He was talking about something we call the ‘compound uncertainty’ that must be navigated when we want to test and introduce a real breakthrough digital business idea. You can connect social groups, economic groups and communities, which would be extraordinarily cumbersome and time-consuming in bigger societies”.
These circumstances have induced uncertainty across our entire business value chain,” says Venkat Gopalan, chief digital, data and technology officer, Belcorp. “As That, in turn, led to a slew of manual processes to make descriptive analysis of the test results. This allowed us to derive insights more easily.”
Skomoroch proposes that managing ML projects are challenging for organizations because shipping ML projects requires an experimental culture that fundamentally changes how many companies approach building and shipping software. Yet, this challenge is not insurmountable. for what is and isn’t possible) to address these challenges. Transcript.
If anything, 2023 has proved to be a year of reckoning for businesses, and IT leaders in particular, as they attempt to come to grips with the disruptive potential of this technology — just as debates over the best path forward for AI have accelerated and regulatory uncertainty has cast a longer shadow over its outlook in the wake of these events.
by MICHAEL FORTE Large-scale live experimentation is a big part of online product development. This means a small and growing product has to use experimentation differently and very carefully. This blog post is about experimentation in this regime. Such decisions involve an actual hypothesis test on specific metrics (e.g.
Unlike experimentation in some other areas, LSOS experiments present a surprising challenge to statisticians — even though we operate in the realm of “big data”, the statistical uncertainty in our experiments can be substantial. We must therefore maintain statistical rigor in quantifying experimentaluncertainty.
As vendors add generative AI to their enterprise software offerings, and as employees test out the tech, CIOs must advise their colleagues on the pros and cons of gen AI’s use as well as the potential consequences of banning or limiting it. There’s a lot of uncertainty. People are thinking, ‘How is this going to affect my career?
In the last few years, businesses have experienced disruptions and uncertainty on an unprecedented scale. However, hand-coding, testing, evaluating and deploying highly accurate models is a tedious and time-consuming process. Managing Through Socio-Economic Disruption.
While leaders have some reservations about the benefits of current AI, organizations are actively investing in gen AI deployment, significantly increasing budgets, expanding use cases, and transitioning projects from experimentation to production. The AGI would need to handle uncertainty and make decisions with incomplete information.
The beliefs of this community are always evolving, and the process of thoughtfully generating, testing, refuting and accepting ideas looks a lot like Science. It is important to make clear distinctions among each of these, and to advance the state of knowledge through concerted observation, modeling and experimentation.
Similarly, we could test the effectiveness of a search ad compared to showing only organic search results. A geo experiment is an experiment where the experimental units are defined by geographic regions. Structure of a geo experiment A typical geo experiment consists of two distinct time periods: pretest and test.
And while its beyond the scope of this article, the applicable knowledge gained through our hands-on experimentation with genAI was head and shoulders above simple web searches (e.g., He specializes in removing fear, uncertainty, and doubt from strategic decision-making through empirical data and market sensing.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








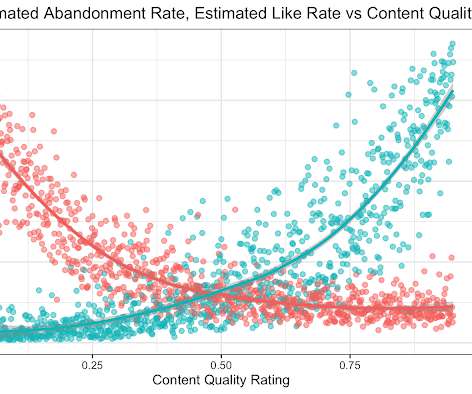









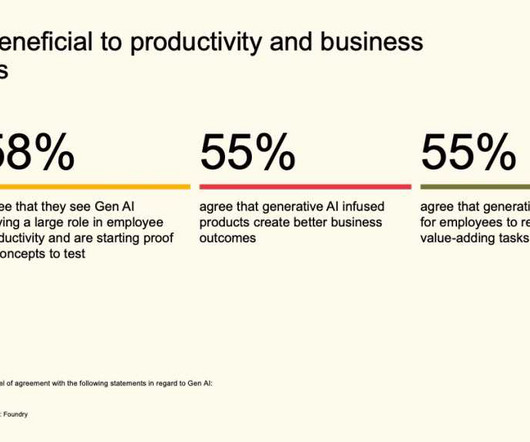















Let's personalize your content