This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Document information extraction involves using computer algorithms to extract structured data (like employee name, address, designation, phone number, etc.) from unstructured or semi-structured documents, such as reports, emails, and web pages.
Entity resolution merges the entities which appear consistently across two or more structured data sources, while preserving evidence decisions. Then connect the graph nodes and relations extracted from unstructureddata sources, reusing the results of entity resolution to disambiguate terms within the domain context.
Overview Learn about Information Retrieval (IR), Vector Space Models (VSM), and Mean Average Precision (MAP) Create a project on Information Retrieval using word2vec based. The post Information Retrieval using word2vec based Vector Space Model appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview This blog covers GREP(Global-Regular-Expression-Print) and its drawbacks Then we move. The post Indexing in Natural Language Processing for Information Retrieval appeared first on Analytics Vidhya.
Speaker: Speakers Michelle Kirk of Georgia Pacific, Darla White of Sanofi, & Scott McVeigh of Onna
Watch this webinar on-demand to learn about: Data lifecycle management. Information governance for unstructureddata. Data dividends: how to extract business value from clean data. Making “cleaning” a regular part of your routine.
Unstructureddata represents one of today’s most significant business challenges. Unlike defined data – the sort of information you’d find in spreadsheets or clearly broken down survey responses – unstructureddata may be textual, video, or audio, and its production is on the rise. Centralizing Information.
This article was published as a part of the Data Science Blogathon. Introduction Unstructureddata contains a plethora of information. It is like energy. The post Words that matter! A Simple Guide to Keyword Extraction in Python appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction Let’s look at a practical application of the supervised NLP fastText model for detecting sarcasm in news headlines. About 80% of all information is unstructured, and text is one of the most common types of unstructureddata.
With organizations seeking to become more data-driven with business decisions, IT leaders must devise data strategies gear toward creating value from data no matter where — or in what form — it resides. Unstructureddata resources can be extremely valuable for gaining business insights and solving problems.
Introduction In the era of big data, organizations are inundated with vast amounts of unstructured textual data. The sheer volume and diversity of information present a significant challenge in extracting insights.
Overview Knowledge graphs are one of the most fascinating concepts in data science Learn how to build a knowledge graph using text from Wikipedia. The post Knowledge Graph – A Powerful Data Science Technique to Mine Information from Text (with Python code) appeared first on Analytics Vidhya.
Introduction Textual data from social media posts, customer feedback, and reviews are valuable resources for any business. There is a host of useful information in such unstructureddata that we can discover. Making sense of this unstructureddata can help companies better understand […].
Unstructureddata is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructuredinformation may have a little or a lot of structure but in ways that are unexpected or inconsistent.
Now that AI can unravel the secrets inside a charred, brittle, ancient scroll buried under lava over 2,000 years ago, imagine what it can reveal in your unstructureddata–and how that can reshape your work, thoughts, and actions. Unstructureddata has been integral to human society for over 50,000 years.
Although Amazon DataZone automates subscription fulfillment for structured data assetssuch as data stored in Amazon Simple Storage Service (Amazon S3), cataloged with the AWS Glue Data Catalog , or stored in Amazon Redshift many organizations also rely heavily on unstructureddata. Enter a name for the asset.
They promise to revolutionize how we interact with data, generating human-quality text, understanding natural language and transforming data in ways we never thought possible. From automating tedious tasks to unlocking insights from unstructureddata, the potential seems limitless.
When I think about unstructureddata, I see my colleague Rob Gerbrandt (an information governance genius) walking into a customer’s conference room where tubes of core samples line three walls. While most of us would see dirt and rock, Rob sees unstructureddata. have encouraged the creation of unstructureddata.
I was recently asked to identify key modern data architecture trends. Data architectures have changed significantly to accommodate larger volumes of data as well as new types of data such as streaming and unstructureddata. Here are some of the trends I see continuing to impact data architectures.
At current growth rates, it is estimated that the number of bits produced would exceed the number of atoms on Earth in about 350 years – a physics-based constraint described as an information catastrophe. The rate of data growth is reflected in the proliferation of storage centres. of that data is analysed.
“Our big challenge, honestly, is the unstructureddata,” Seetharam said, noting that Corning must now “figure out how to categorize [unstructureddata] and bring it in a form that can be useful.” Bhavesh Dayalji, CAIO at S&P Global, added that integrating all kinds of data structures into gen AI models is a challenge.
Chief among these is United ChatGPT for secure employee experimental use and an external-facing LLM that better informs customers about flight delays, known as Every Flight Has a Story, that has already boosted customer satisfaction by 6%, Birnbaum notes. Historically United storytellers had to manually edit templates, which took time.
According to a recent Salesforce study, 62% of large enterprises are not well-positioned to achieve this harmony, with 80% grappling with data silos and 72% facing the complexities of overly interdependent systems. Incorporating custom knowledge graphs, enriched with domain expertise, further optimizes data consolidation.
Improving data quality and integrating new data sources to enrich customer and prospect data are vital for applying AI in marketing and sales. For example, many organizations have been centralizing customer data for some time, but gen AI can greatly enhance the ability to find patterns and signals in unstructureddata sources.
To integrate AI into enterprise workflows, we must first do the foundation work to get our clients data estate optimized, structured, and migrated to the cloud. It requires the ability to break down silos between disparate data sets and keep data flowing in real-time.
Unstructureddata has been a significant factor in data lakes and analytics for some time. Twelve years ago, nearly a third of enterprises were working with large amounts of unstructureddata. As I’ve pointed out previously , unstructureddata is really a misnomer.
Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machine learning and data science. The insights are used to produce informative content for stakeholders (decision-makers, business users, and clients).
Elastic supports this through a rich set of connectors that bring structured and unstructureddata files, records, logs into Elasticsearch. For more information, click here. Once indexed, AI models can generate context-aware alerts, enrich investigations, and power automation with precision. Credit: Elastic
Some challenges include data infrastructure that allows scaling and optimizing for AI; data management to inform AI workflows where data lives and how it can be used; and associated data services that help data scientists protect AI workflows and keep their models clean. Through relentless innovation.
Stone called outdated apps a multi-trillion-dollar problem, even after organizations have spent the past decade focused on modernizing their infrastructure to deal with big data. This allows for the extraction and integration of data into AI models without overhauling entire platforms, Erolin says. We are in mid-transition, Stone says.
It promises a unified platform for storing and analyzing structured and unstructureddata, particularly for. The post The Lakehouse Isn’t The End Game Here’s What Comes Next appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information.
Similar to disaster recovery, business continuity, and information security, data strategy needs to be well thought out and defined to inform the rest, while providing a foundation from which to build a strong business.” Overlooking these data resources is a big mistake. It will not be something they can ignore.
Chatbots are used to build response systems that give employees quick access to extensive internal knowledge bases, breaking down information silos. In many cases, this eliminates the need for specialized teams, extensive data labeling, and complex machine-learning pipelines. and immediately receive relevant answers and visualizations.
A recent Forrester study shows a growing number of companies feel their workers spend too much time looking for information they need – 40% today vs. 19% just five years ago. A number of issues contribute to the problem, including a highly distributed workforce, siloed technology systems, the massive growth in data, and more.
This infrastructure must be suited to handle extreme data growth, especially with unstructureddata. An estimated 90% of the global datasphere is comprised of unstructureddata 1. And it’s growing rapidly, estimated at 55-65% 2 year-over-year and three times faster than structured data.
As was explained in ISGs State of Generative AI Market Report , AI requires data that is clean, well-organized and compliant with regulatory standards. In addition to managing structured and unstructureddata assets, MarkLogic also offers data harmonization, mastering and enrichment via MarkLogic Data Hub.
Salesforce is updating its Data Cloud with vector database and Einstein Copilot Search capabilities in an effort to help enterprises use unstructureddata for analysis. The Einstein Trust Layer is based on a large language model (LLM) built into the platform to ensure data security and privacy.
What is a data scientist? Data scientists are analytical data experts who use data science to discover insights from massive amounts of structured and unstructureddata to help shape or meet specific business needs and goals. Semi-structured data falls between the two.
Two big things: They bring the messiness of the real world into your system through unstructureddata. Recently, we helped an EdTech startup build an information-retrieval app. Any scenario in which a student is looking for information that the corpus of documents can answer. What makes LLM applications so different?
They’re still struggling with the basics: tagging and labeling data, creating (and managing) metadata, managing unstructureddata, etc. Nearly one-quarter of respondents work as data scientists or analysts (see Figure 1). An additional 7% are data engineers. Some other common data quality issues (Figure 4)—e.g.,
Raw data that has not been cleared is known as unstructureddata; this includes chat logs, pictures, and PDF files. Unstructureddata that has been cleared to suit a plan, sort out into tables, and defined by relationships and types, is known as structured data.
The main reason is that it is difficult and time-consuming to consolidate, process, label, clean, and protect the information at scale to train AI models. The examples above demonstrate how expanding AI applications and unstructureddata help create transformational outcomes.
This article was published as a part of the Data Science Blogathon “You can have data without information but you cannot have information without data” – Daniel Keys Moran Introduction If you are here then you might be already interested in Machine Learning or Deep Learning so I need not explain what it is?
That’s an unfathomable amount of information. Data has changed our lives in many ways, helping to improve the processes, initiatives, and innovations of organizations across sectors through the power of insight. In doing so, your business will be data-driven, and as a direct result – more successful.
This means feeding the machine with vast amounts of data, from structured to unstructureddata, which will help the device learn how to think, process information, and act like humans. As unstructureddata comes from different sources and is stored in various locations.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























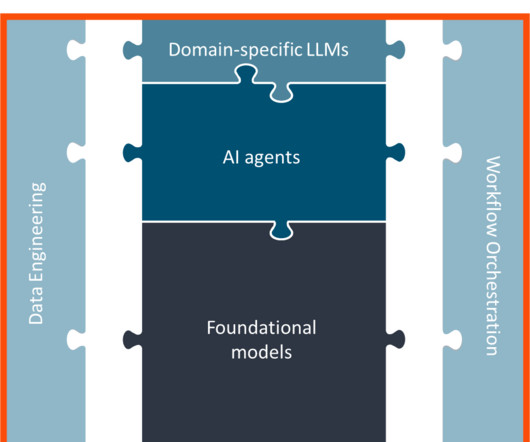

















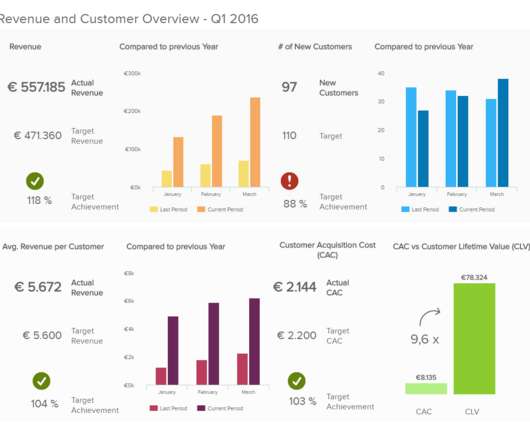









Let's personalize your content