This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon EMR provides a big data environment for data processing, interactive analysis, and machine learning using open source frameworks such as Apache Spark, Apache Hive, and Presto.
This improvement streamlines the ability to access and manage your Airflow environments and their integration with external systems, and allows you to interact with your workflows programmatically. Airflow REST API The Airflow REST API is a programmatic interface that allows you to interact with Airflow’s core functionalities.
However, commits can still fail if the latest metadata is updated after the base metadata version is established. Iceberg uses a layered architecture to manage table state and data: Catalog layer Maintains a pointer to the current table metadata file, serving as the single source of truth for table state.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Metadata management is key to wringing all the value possible from data assets. What Is Metadata? Analyst firm Gartner defines metadata as “information that describes various facets of an information asset to improve its usability throughout its life cycle. It is metadata that turns information into an asset.”.
Metadata has been defined as the who, what, where, when, why, and how of data. Without the context given by metadata, data is just a bunch of numbers and letters. But going on a rampage to define, categorize, and otherwise metadata-ize your data doesn’t necessarily give you the key to the value in your data. Hold on tight!
Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats. XTable isn’t a new table format but provides abstractions and tools to translate the metadata associated with existing formats.
In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer. This ensures that each change is tracked and reversible, enhancing data governance and auditability.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
First, what active metadata management isn’t : “Okay, you metadata! Now, what active metadata management is (well, kind of): “Okay, you metadata! Metadata are the details on those tools: what they are, what to use them for, what to use them with. . That takes active metadata management. Quit lounging around!
Each interaction amplifies the potential for errors, breaches, or misuse, underscoring the critical need for a strong governance framework to mitigate these risks. As AI adoption accelerates, it demands increasingly vast amounts of data, leading to more users accessing, transferring, and managing it across diverse environments.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. If you don’t already have an AWS account, you can create one.
The Eightfold Talent Intelligence Platform integrates with Amazon Redshift metadata security to implement visibility of data catalog listing of names of databases, schemas, tables, views, stored procedures, and functions in Amazon Redshift. This post discusses restricting listing of data catalog metadata as per the granted permissions.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
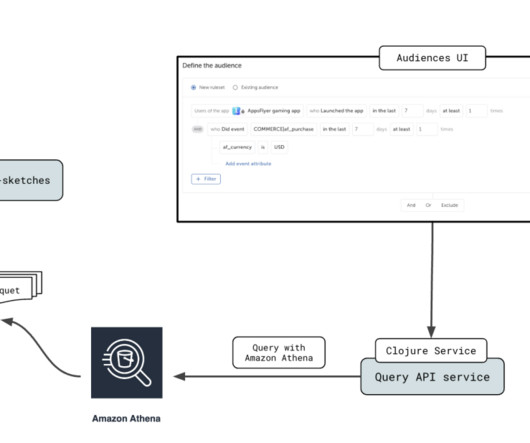
AppsFlyer empowers digital marketers to precisely identify and allocate credit to the various consumer interactions that lead up to an app installation, utilizing in-depth analytics. Partition projection in Athena allows you to improve query efficiency by projecting the metadata of your partitions.
Any interaction between the two ( e.g., a financial transaction in a financial database) would be flagged by the authorities, and the interactions would come under great scrutiny. Any node and its relationship to a particular node becomes a type of contextual metadata for that particular note.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight. The architecture is shown in the following figure.
It offers a wealth of books, on-demand courses, live events, short-form posts, interactive labs, expert playlists, and more—formed from the proprietary content of thousands of independent authors, industry experts, and several of the largest education publishers in the world.
It reads metadata from your structured data store to generate SQL queries. Under Default storage metadata , select Amazon Redshift databases and for Database , choose dev. There are different supported authentication methods to create the Amazon Bedrock knowledge base using Amazon Redshift. Choose your Redshift workgroup. Choose Next.
Install and configure the AWS CLI The AWS Command Line Interface (AWS CLI) is an open source tool that enables you to interact with AWS services using commands in your command line shell. When you’re logged in, you can start interacting with the application. Make sure the function is already deployed and working in your account.
The updated version includes more emerging drivers of supply chain success, covering topics such as omnichannel, metadata, and blockchain , according to the ASCM. SCORs six primary processes As a framework, SCOR focuses on all customer interactions from the moment an order is placed until the invoice is paid.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. We enhanced support for querying Apache Iceberg data and improved the performance of querying Iceberg up to threefold year-over-year.
GenAI as ubiquitous technology In the coming years, AI will evolve from an explicit, opaque tool with direct user interaction to a seamlessly integrated component in the feature set. Content management systems: Content editors can search for assets or content using descriptive language without relying on extensive tagging or metadata.
We introduce you to Amazon Managed Service for Apache Flink Studio and get started querying streaming data interactively using Amazon Kinesis Data Streams. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day.
To interact with and analyze data stored in Amazon Redshift, AWS provides the Amazon Redshift Query Editor V2 , a web-based tool that allows you to explore, analyze, and share data using SQL. Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. Choose Add provider.
In this post, we show you how you can convert existing data in an Amazon S3 data lake in Apache Parquet format to Apache Iceberg format to support transactions on the data using Jupyter Notebook based interactive sessions over AWS Glue 4.0. AWS Command Line Interface (AWS CLI) configured to interact with AWS Services.
Since its inception, Apache Kafka has depended on Apache Zookeeper for storing and replicating the metadata of Kafka brokers and topics. the Kafka community has adopted KRaft (Apache Kafka on Raft), a consensus protocol, to replace Kafka’s dependency on ZooKeeper for metadata management. For Metadata mode , select KRaft.
Discoverable – users have access to a catalog or metadata management tool which renders the domain discoverable and accessible. Clear accountability – users interact with a responsive, dedicated team that is accountable to them. Also, the domain must support the attributes that are part of every modern data architecture.
Well, we got jetpacks, too, but we rarely interact with them during the workday. Analysis, however, requires enterprises to find and collect metadata. Active metadata management enhances typical metadata management , which is becoming “increasingly incapable” of fulfilling enterprise metadata requirements, according to Gartner.
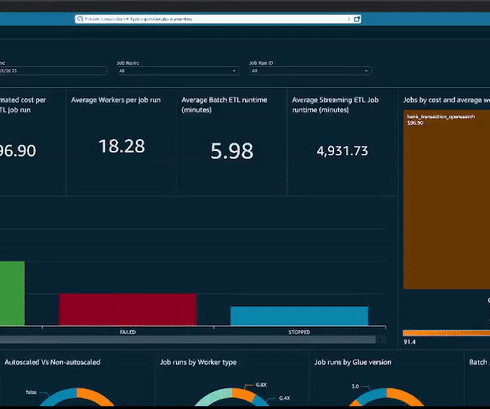
You have metrics available per job run within the AWS Glue console, but they don’t cover all available AWS Glue job metrics, and the visuals aren’t as interactive compared to the QuickSight dashboard. This can provide you with a more comprehensive view of your usage and tools to help you dive deep into your AWS Glue job run environment.
These include internet-scale web and mobile applications, low-latency metadata stores, high-traffic retail websites, Internet of Things (IoT) and time series data, online gaming, and more. Athena is a serverless, interactive service that allows you to query data from a variety of sources in heterogeneous formats, with no provisioning effort.
While prompt templates are pre-written and reusable prompts that ensure consistent agent interactions to gather more information from users to achieve specific goals, agent templates are grouped topics complete with metadata and instructions to accelerate the agent building process.
Applications are increasingly using AI and search to reinvent and improve user interactions, content discovery, and automation to uplift business outcomes. We will use generative multimodal AI to modernize image search, eliminating the need for labor to maintain image tags and other metadata. that can operate on text and images.
Today, customers widely use OpenSearch Service for operational analytics because of its ability to ingest high volumes of data while also providing rich and interactive analytics. In such an event, the new instance family guarantees recovery of both the cluster metadata and the index data up to the latest acknowledged operation.
Whether driving digital experiences, mapping customer journeys, enhancing digital operations, developing digital innovations, finding new ways to interact with customers, or building digital ecosystems or marketplaces – all of this digital transformation is powered by data. Data readiness is everything.
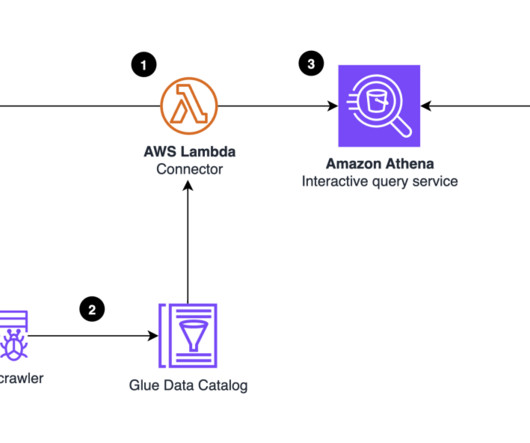
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. connection testing, metadata retrieval, and data preview.
Trino is an open source distributed SQL query engine designed for interactive analytic workloads. Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. With Amazon EMR 6.10.0
This is in stark contrast to the vast number of organizations that previously utilized on-premise discovery solutions and metadata management tools. More than any other BI metadata management tool out there, cloud automation offers the best way for teams to connect remotely and manage projects.
Metadata Caching. If you have ever interacted with Impala in the past you would have encountered the Catalog Cache Service. As Impala’s adoption grew the catalog service started to experience these growing pains, therefore recently we introduced two new features to alleviate the stress, On-demand Metadata and Zero Touch Metadata.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
Second, generative AI applications introduce a higher number of data interactions than conventional applications, which requires that the data security, privacy, and access control policies be implemented as part of the generative AI user workflows. Data enrichment In addition, additional metadata may need to be extracted from the objects.
“Salesforce has a major advantage over many of its rivals, simply because it captures so much interaction data from its user base, and as such, the models are able to be trained on a massive number of Salesforce-specific tasks and processes, and the related metadata,” said Keith Kirkpatrick, research director at The Futurum Group.
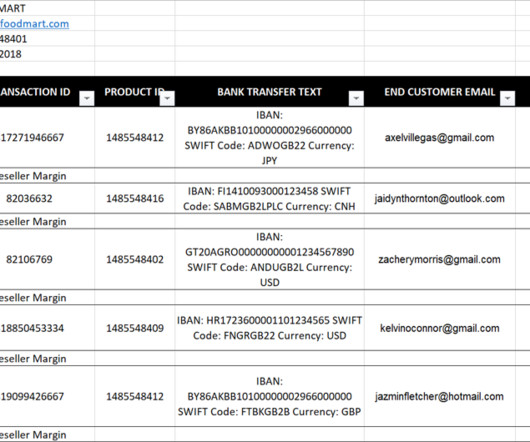
In this post, we demonstrate the following: Extracting non-transactional metadata from the top rows of a file and merging it with transactional data Combining multi-line rows into single-line rows Extracting unique identifiers from within strings or text Solution overview For this use case, imagine you’re a data analyst working at your organization.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content