This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
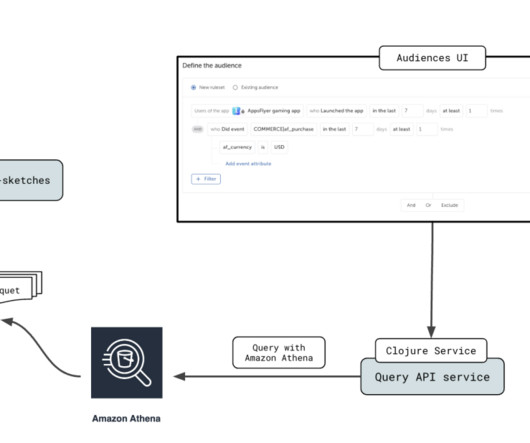
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon EMR provides a big data environment for data processing, interactive analysis, and machine learning using open source frameworks such as Apache Spark, Apache Hive, and Presto.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
We will also cover the pattern with automatic compaction through AWS Glue Data Catalog table optimization. Consider a streaming pipeline ingesting real-time event data while a scheduled compaction job runs to optimize file sizes. Load the tables latest metadata, and determine which metadata version is used as the base for the update.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
Despite their advantages, traditional data lake architectures often grapple with challenges such as understanding deviations from the most optimal state of the table over time, identifying issues in data pipelines, and monitoring a large number of tables. It is essential for optimizing read and write performance.
Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. Query optimization in databases is a long standing area of research, with much emphasis on finding near optimal query plans.
Amazon OpenSearch Service recently introduced the OpenSearch Optimized Instance family (OR1), which delivers up to 30% price-performance improvement over existing memory optimized instances in internal benchmarks, and uses Amazon Simple Storage Service (Amazon S3) to provide 11 9s of durability.
First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead. We have enhanced autonomics algorithms to generate and implement smarter and quicker optimal data layout recommendations for distribution and sort keys, further optimizing performance.
First, what active metadata management isn’t : “Okay, you metadata! Now, what active metadata management is (well, kind of): “Okay, you metadata! I will, of course, end up with a very amateurish finished product, because I used sub-optimal tools to do the job. That takes active metadata management.
AppsFlyer empowers digital marketers to precisely identify and allocate credit to the various consumer interactions that lead up to an app installation, utilizing in-depth analytics. Partition projection in Athena allows you to improve query efficiency by projecting the metadata of your partitions.
Amazon Athena is a serverless, interactive analytics service built on open source frameworks, supporting open table file formats. Starting today, the Athena SQL engine uses a cost-based optimizer (CBO), a new feature that uses table and column statistics stored in the AWS Glue Data Catalog as part of the table’s metadata.
Amazon Bedrock Knowledge Bases automatically translates these natural language queries into optimized SQL statements, thereby accelerating time to insight, enabling faster discoveries and efficient decision-making. It reads metadata from your structured data store to generate SQL queries. Choose your Redshift workgroup. Choose Next.
Install and configure the AWS CLI The AWS Command Line Interface (AWS CLI) is an open source tool that enables you to interact with AWS services using commands in your command line shell. When you’re logged in, you can start interacting with the application. Make sure the function is already deployed and working in your account.
The updated version includes more emerging drivers of supply chain success, covering topics such as omnichannel, metadata, and blockchain , according to the ASCM. SCORs six primary processes As a framework, SCOR focuses on all customer interactions from the moment an order is placed until the invoice is paid.
S3 Tables are specifically optimized for analytics workloads, resulting in up to 3 times faster query throughput and up to 10 times higher transactions per second compared to self-managed tables. These metadata tables are stored in S3 Tables, the new S3 storage offering optimized for tabular data.
As the use of Hydro grows within REA, it’s crucial to perform capacity planning to meet user demands while maintaining optimal performance and cost-efficiency. Capacity monitoring dashboards As part of our platform management process, we conduct monthly operational reviews to maintain optimal performance.
Trino is an open source distributed SQL query engine designed for interactive analytic workloads. When you use Trino on Amazon EMR or Athena, you get the latest open source community innovations along with proprietary, AWS developed optimizations. and later, S3 file metadata-based join optimizations are turned on by default.
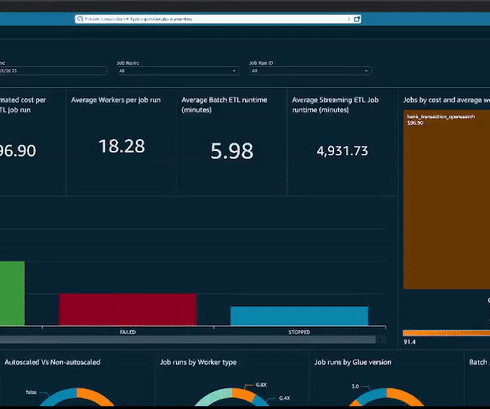
You have metrics available per job run within the AWS Glue console, but they don’t cover all available AWS Glue job metrics, and the visuals aren’t as interactive compared to the QuickSight dashboard. The solution was developed with cost-optimization as a priority, but some resources in the stack will incur costs once deployed.
Well, we got jetpacks, too, but we rarely interact with them during the workday. With lots of data comes yet more calls for automation, optimization, and productivity initiatives to put that data to good use. Analysis, however, requires enterprises to find and collect metadata. What Is Active Metadata Management?
Metadata and artifacts needed for audits. Machine learning often interacts and impacts users, so companies not only need to put in place processes that will let them deploy ML responsibly, they need to build foundational technologies that will allow them to retain oversight, particularly when things go wrong.
They prefer self-service development, interactive dashboards, and self-service data exploration. Good BI tools can achieve platform security, manage platform users, monitor access and usage, optimize performance, support operation in different operating systems, and ensure system’s high availability and disaster recovery.
In other words, using metadata about data science work to generate code. SQL optimization provides helpful analogies, given how SQL queries get translated into query graphs internally , then the real smarts of a SQL engine work over that graph. On deck this time ’round the Moon: program synthesis. Software writes Software?
By optimizing the various CDP Data Services, including CDW, CDE, and Cloudera Machine Learning (CML) with Iceberg, Cloudera customers can define and manipulate datasets with SQL commands, build complex data pipelines using features like Time Travel operations, and deploy machine learning models built from Iceberg tables.
BMW Group uses 4,500 AWS Cloud accounts across the entire organization but is faced with the challenge of reducing unnecessary costs, optimizing spend, and having a central place to monitor costs. The ultimate goal is to raise awareness of cloud efficiency and optimize cloud utilization in a cost-effective and sustainable manner.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
This benefit goes directly in hand with the fact that analytics provide businesses with technologies to spot trends and patterns that will lead to the optimization of resources and processes. As mentioned above, one of the great benefits of business intelligence and analytics is the ability to make informed data-based decisions.
AI apps can gather data by analyzing user behavior and interaction. App analytics provide valuable insights that help identify bottlenecks, improve user experience, and optimize marketing campaigns. By optimizing your mobile app for voice search, you can provide a more convenient shopping experience for your customers.
Data governance and EA also provide many of the same benefits of enterprise architecture or business process modeling projects: reducing risk, optimizing operations, and increasing the use of trusted data. We have to document how our systems interact, including the logical and physical data assets that flow into, out of and between them.
Advanced predictive analytics and modeling are now optimizing safety stocks and supply chains to include the element in risk so that optimized inventory levels and redundant capital deployment in high risk manufacturing processes are optimized. Digital Transformation is not without Risk. Open source solutions reduce risk.
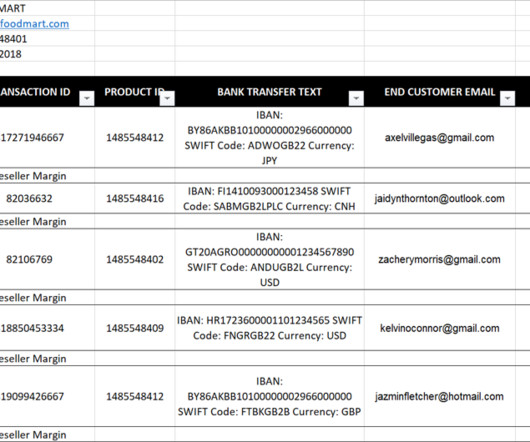
In this post, we demonstrate the following: Extracting non-transactional metadata from the top rows of a file and merging it with transactional data Combining multi-line rows into single-line rows Extracting unique identifiers from within strings or text Solution overview For this use case, imagine you’re a data analyst working at your organization.
Companies working on AI technology can use it to improve scalability and optimize the decision-making process. It allows data scientists to log, store, share, compare and search important metadata that is used to build models for data science applications. It is highly popular among companies developing artificial intelligence tools.
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. from the business interactions), but if not available, then through confirmation techniques of an independent nature. 2 – Data profiling.
Customers now want to migrate their Apache Hive workloads to Apache Spark in the cloud to get the benefits of optimized runtime, cost reduction through transient clusters, better scalability by decoupling the storage and compute, and flexibility. Generate Spark SQL metadata Our batch job consists of Hive steps scheduled to run sequentially.
To further optimize and improve the developer velocity for our data consumers, we added Amazon DynamoDB as a metadata store for different data sources landing in the data lake. S3 bucket as landing zone We used an S3 bucket as the immediate landing zone of the extracted data, which is further processed and optimized.
QuickSight makes it straightforward for business users to visualize data in interactive dashboards and reports. Analyzing historical patterns allows you to optimize performance, identify issues proactively, and improve planning. An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog.
This benchmark is run on the Interactive Query HDInsight cluster using the latest version. Running on highly optimized Kubernetes engines, CDW can quickly and automatically scale up and down based on actual query workload, providing optimum utilization of cloud (public as well as private) resources and budget.
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. You're choosing only one metric because you want to optimize it. But it is not routine. So, how do we fix this problem? This is the one metric that matters to your business right now.
billion data records in real-time every day, based on player interactions with its games. KAWAII KAWAII stands for Knowledge Assistant for Wiki with Artificial Intelligence and Interaction. The text, the vectors and the metadata of the chunks are stored in a database that can process vectors and calculate distances.
Amazon Redshift already provides the capability of automatic table optimization (ATO), which automatically optimizes the design of tables by applying sort and distribution keys without the need for administrator intervention. Refer to Working with automatic table optimization for more details on ATO.
When a mix of batch, interactive, and data serving workloads are added to the mix, the problem becomes nearly intractable. While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ data lake. 2) By workload type.
Any data you obtain when someone interacts with your profile or content on LinkedIn, Facebook, Instagram, Twitter, or any other social media channel counts as social data. Click metadata can tell you what kinds of things they would like to see more. Specific metrics can vary from platform to platform. Lead Segmentation.
Impala has a longstanding reputation for high performance and concurrency, low latency for interactive queries, and the CPU efficiency of it’s C++ backend with dynamic code generation based on LLVM. Some examples of recent optimizations in Impala include: New multithreading model (see dedicated blog post ). Benchmark Description.
The FinAuto team built AWS Cloud Development Kit (AWS CDK), AWS CloudFormation , and API tools to maintain a metadata store that ingests from domain owner catalogs into the global catalog. The global catalog is also periodically fully refreshed to resolve issues during metadata sync processes to maintain resiliency.
The new approach would need to offer the flexibility to integrate new technologies such as machine learning (ML), scalability to handle long-term retention at forecasted growth levels, and provide options for cost optimization. Previously, P2 logs were ingested into the SIEM.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content