This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon EMR provides a big data environment for data processing, interactive analysis, and machine learning using open source frameworks such as Apache Spark, Apache Hive, and Presto.
However, commits can still fail if the latest metadata is updated after the base metadata version is established. Iceberg uses a layered architecture to manage table state and data: Catalog layer Maintains a pointer to the current table metadata file, serving as the single source of truth for table state.
Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats. For more examples and references to other posts, refer to the following GitHub repository. This post is one of multiple posts about XTable on AWS.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
It offers a wealth of books, on-demand courses, live events, short-form posts, interactive labs, expert playlists, and more—formed from the proprietary content of thousands of independent authors, industry experts, and several of the largest education publishers in the world.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. Refer to Service Quotas for more details.
System metadata is reviewed and updated regularly. The cluster architecture can be split across a number of zones as illustrated in the following diagram: Outside the perimeter are source data and applications, the gateway zones are where administrators and applications will interact with the core cluster zones where the work is performed.
The book is awesome, an absolute must-have reference volume, and it is free (for now, downloadable from Neo4j ). Any interaction between the two ( e.g., a financial transaction in a financial database) would be flagged by the authorities, and the interactions would come under great scrutiny. Graph Algorithms book.
The Eightfold Talent Intelligence Platform integrates with Amazon Redshift metadata security to implement visibility of data catalog listing of names of databases, schemas, tables, views, stored procedures, and functions in Amazon Redshift. This post discusses restricting listing of data catalog metadata as per the granted permissions.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Launch summary Following is the launch summary which provides the announcement links and reference blogs for the key announcements.
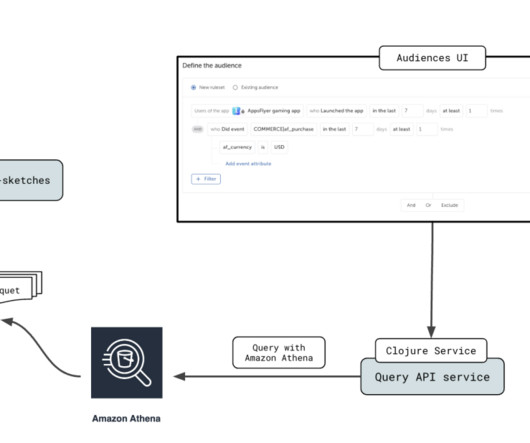
AppsFlyer empowers digital marketers to precisely identify and allocate credit to the various consumer interactions that lead up to an app installation, utilizing in-depth analytics. This includes a feature that provides real-time estimation of audience sizes within specific user segments, referred to as the Estimation feature.
Install and configure the AWS CLI The AWS Command Line Interface (AWS CLI) is an open source tool that enables you to interact with AWS services using commands in your command line shell. When you’re logged in, you can start interacting with the application. Make sure the function is already deployed and working in your account.
We introduce you to Amazon Managed Service for Apache Flink Studio and get started querying streaming data interactively using Amazon Kinesis Data Streams. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day.
Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose. While the digital age has been successful in prompting innovation far and wide, it has also facilitated what is referred to as the “data crisis” – low-quality data. 2 – Data profiling.
Since its inception, Apache Kafka has depended on Apache Zookeeper for storing and replicating the metadata of Kafka brokers and topics. the Kafka community has adopted KRaft (Apache Kafka on Raft), a consensus protocol, to replace Kafka’s dependency on ZooKeeper for metadata management. For Metadata mode , select KRaft.
Based on the study of the evaluation criteria of Gartner Magic Quadrant for analytics and Business Intelligence Platforms, I have summarized top 10 key features of BI tools for your reference. They prefer self-service development, interactive dashboards, and self-service data exploration. Metadata management. of BI pages.
These include internet-scale web and mobile applications, low-latency metadata stores, high-traffic retail websites, Internet of Things (IoT) and time series data, online gaming, and more. Athena is a serverless, interactive service that allows you to query data from a variety of sources in heterogeneous formats, with no provisioning effort.
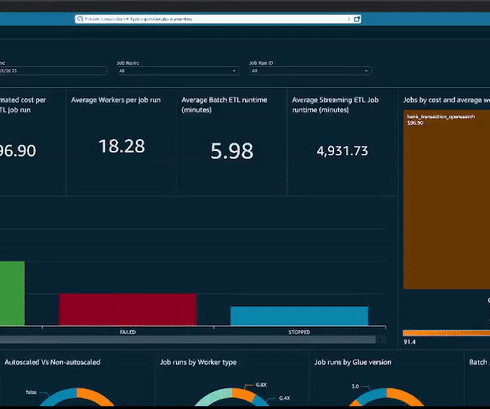
You have metrics available per job run within the AWS Glue console, but they don’t cover all available AWS Glue job metrics, and the visuals aren’t as interactive compared to the QuickSight dashboard. Refer to Managing user access inside Amazon QuickSight to find your existing QuickSight users. There is a choice state for each branch.
Second, generative AI applications introduce a higher number of data interactions than conventional applications, which requires that the data security, privacy, and access control policies be implemented as part of the generative AI user workflows. Data enrichment In addition, additional metadata may need to be extracted from the objects.
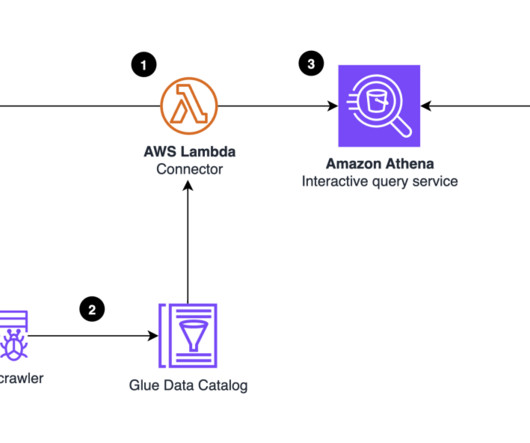
Trino is an open source distributed SQL query engine designed for interactive analytic workloads. Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. With Amazon EMR 6.10.0
To interact with and analyze data stored in Amazon Redshift, AWS provides the Amazon Redshift Query Editor V2 , a web-based tool that allows you to explore, analyze, and share data using SQL. To learn more about this process, refer to Enabling SAML 2.0 From there, the user can access the Redshift Query Editor V2. Choose Add provider.
A data mesh can be defined as a collection of “nodes”, typically referred to as Data Products, each of which can be uniquely identified using four key descriptive properties: . Data and Metadata: Data inputs and data outputs produced based on the application logic.
Apache Airflow is an open source tool used to programmatically author, schedule, and monitor sequences of processes and tasks, referred to as workflows. VPC endpoints are created for Amazon S3 and Secrets Manager to interact with other resources. A VPC gateway endpointto Amazon S3. An Amazon MWAA environment. Add the constraints-3.11-updated.txt
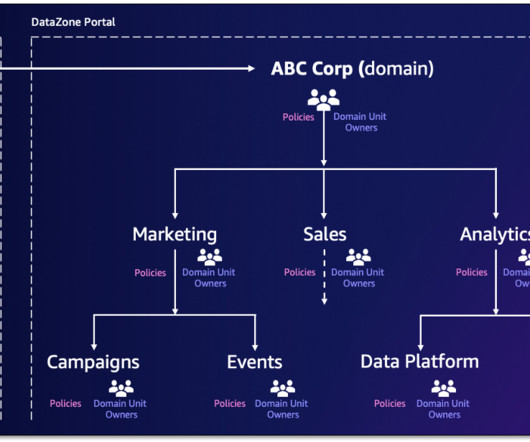
Additionally, authorization policies can be configured for a domain unit permitting actions such as who can create projects, metadata forms, and glossaries within their domain units. Several other child domain units with policies can be built within customer domain units, such as customer interactions and profiles.
For a more in-depth description of these phases please refer to Impala: A Modern, Open-Source SQL Engine for Hadoop. Metadata Caching. If you have ever interacted with Impala in the past you would have encountered the Catalog Cache Service. This includes the time to fetch the metadata and schema for our tables.
If my explanation above is the correct interpretation of the high percentage, and if the statement refers to successfully deployed applications (i.e., A similarly high percentage of tabular data usage among data scientists was mentioned here. These may not be high risk. They might actually be high-reward discoveries.
For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard. Additionally, it incorporates BMW Group’s internal system to integrate essential metadata, offering a comprehensive view of the data across various dimensions, such as group, department, product, and applications.
In today’s world, we increasingly interact with the environment around us through data. These 30 layers can be split into two kinds: a location-reference layer and a topic layer. The catalog stores the asset’s metadata in RDF. Researchers used GraphDB to store semantic metadata.
Analytics reference architecture for gaming organizations In this section, we discuss how gaming organizations can use a data hub architecture to address the analytical needs of an enterprise, which requires the same data at multiple levels of granularity and different formats, and is standardized for faster consumption.
Athena provides the connectivity and query interface and can easily be plugged into other AWS services for downstream use cases such as interactive analysis and visualizations. We use the following AWS services in this solution: Amazon Athena – A serverless interactive analytics service. To create the bucket, refer to Create buckets.
We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The first component (metadata setup) consumes existing Hive job configurations and generates metadata such as number of parameters, number of actions (steps), and file formats. X Python 3.8 Amazon EMR 6.1
The Common Crawl corpus contains petabytes of data, regularly collected since 2008, and contains raw webpage data, metadata extracts, and text extracts. For instructions, refer to Create your first S3 bucket. Set up Athena to run interactive SQL. For instructions, refer to Get started.
For more information, refer to Guidance for Distributed Computing with Cross Regional Dask on AWS and the GitHub repo for open-source code. After deployment, the user will have access to a Jupyter notebook, where they can interact with two datasets from ASDI on AWS: Coupled Model Intercomparison Project 6 (CMIP6) and ECMWF ERA5 Reanalysis.
AWS has invested in native service integration with Apache Hudi and published technical contents to enable you to use Apache Hudi with AWS Glue (for example, refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started ).
In this solution (as shown in the preceding figure), the AWS account that contains the data assets is referred to as the producer account. The AWS account that needs to access or use the data from the producer account is referred to as the consumer account. Select the mkt_sls_table table and review the metadata that was generated.
To enable multimodal search across text, images, and combinations of the two, you generate embeddings for both text-based image metadata and the image itself. When you use the neural plugin’s connectors, you don’t need to build additional pipelines external to OpenSearch Service to interact with these models during indexing and searching.
Its in-memory computing makes it great for iterative algorithms and interactive queries. For using it with other Apache Spark platforms, the connector is available as a public JAR file that can be directly referred to while submitting a Spark Structured Streaming job. Starting with Amazon EMR 7.1,
In other words, using metadata about data science work to generate code. One of the longer-term trends that we’re seeing with Airflow , and so on, is to externalize graph-based metadata and leverage it beyond the lifecycle of a single SQL query, making our workflows smarter and more robust. BTW, videos for Rev2 are up: [link].
That’s where Tableau sees Pulse and Einstein Copilot for Tableau — a generative AI assistant that gives users the ability to interact with Tableau using natural language — coming in. “But to us, it’s more than just having a data strategy; it’s also about building a great foundation of a data culture.”
In this post, we demonstrate the following: Extracting non-transactional metadata from the top rows of a file and merging it with transactional data Combining multi-line rows into single-line rows Extracting unique identifiers from within strings or text Solution overview For this use case, imagine you’re a data analyst working at your organization.
billion data records in real-time every day, based on player interactions with its games. KAWAII KAWAII stands for Knowledge Assistant for Wiki with Artificial Intelligence and Interaction. The text, the vectors and the metadata of the chunks are stored in a database that can process vectors and calculate distances.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. ” For example, these tools may offer metadata-based notifications. What is Data in Place?
You will learn more about statement level metadata , the pros and cons of RDF-star, how SPARQ-star works and how different RDF engines implement RDF-star. Interesting attendee question : Should I model my data, such as start and end date, as metadata with embedded triples or as N-ary concepts?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content