This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This improvement streamlines the ability to access and manage your Airflow environments and their integration with external systems, and allows you to interact with your workflows programmatically. Airflow REST API The Airflow REST API is a programmatic interface that allows you to interact with Airflow’s core functionalities.
Amazon Athena provides interactive analytics service for analyzing the data in Amazon Simple Storage Service (Amazon S3). Amazon EMR provides a big data environment for data processing, interactive analysis, and machine learning using open source frameworks such as Apache Spark, Apache Hive, and Presto.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats. XTable isn’t a new table format but provides abstractions and tools to translate the metadata associated with existing formats.
Metadata management is key to wringing all the value possible from data assets. What Is Metadata? Analyst firm Gartner defines metadata as “information that describes various facets of an information asset to improve its usability throughout its life cycle. It is metadata that turns information into an asset.”.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. If you don’t already have an AWS account, you can create one.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
It reads metadata from your structured data store to generate SQL queries. Under Default storage metadata , select Amazon Redshift databases and for Database , choose dev. For this demo, we use a native testing interface on the Amazon Bedrock Knowledge Bases console. Choose Test. Choose your Redshift workgroup.
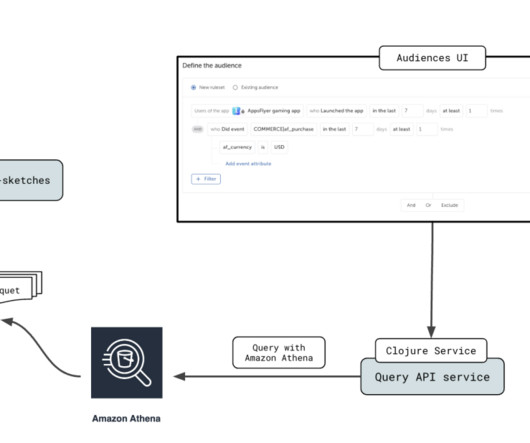
AppsFlyer empowers digital marketers to precisely identify and allocate credit to the various consumer interactions that lead up to an app installation, utilizing in-depth analytics. Additionally, we discuss the thorough testing, monitoring, and rollout process that resulted in a successful transition to the new Athena architecture.
The Eightfold Talent Intelligence Platform integrates with Amazon Redshift metadata security to implement visibility of data catalog listing of names of databases, schemas, tables, views, stored procedures, and functions in Amazon Redshift. This post discusses restricting listing of data catalog metadata as per the granted permissions.
It offers a wealth of books, on-demand courses, live events, short-form posts, interactive labs, expert playlists, and more—formed from the proprietary content of thousands of independent authors, industry experts, and several of the largest education publishers in the world.
Install and configure the AWS CLI The AWS Command Line Interface (AWS CLI) is an open source tool that enables you to interact with AWS services using commands in your command line shell. When you’re logged in, you can start interacting with the application. Make sure the function is already deployed and working in your account.
To address this, we used the AWS performance testing framework for Apache Kafka to evaluate the theoretical performance limits. We conducted performance and capacity tests on the test MSK clusters that had the same cluster configurations as our development and production clusters.
To interact with and analyze data stored in Amazon Redshift, AWS provides the Amazon Redshift Query Editor V2 , a web-based tool that allows you to explore, analyze, and share data using SQL. Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. Choose Add provider.
Applications are increasingly using AI and search to reinvent and improve user interactions, content discovery, and automation to uplift business outcomes. We will use generative multimodal AI to modernize image search, eliminating the need for labor to maintain image tags and other metadata. that can operate on text and images.
The updated version includes more emerging drivers of supply chain success, covering topics such as omnichannel, metadata, and blockchain , according to the ASCM. SCORs six primary processes As a framework, SCOR focuses on all customer interactions from the moment an order is placed until the invoice is paid.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads.
It allows organizations to secure data, perform searches, analyze logs, monitor applications in real time, and explore interactive log analytics. es.amazonaws.com' # e.g. my-test-domain.us-east-1.es.amazonaws.com, Amazon OpenSearch Service is a fully managed service for search and analytics. Leave the settings as default.
A five to nine-person team owns the dev, test, deployment, monitoring and maintenance of a domain. Discoverable – users have access to a catalog or metadata management tool which renders the domain discoverable and accessible. Clear accountability – users interact with a responsive, dedicated team that is accountable to them.
In the context of Data in Place, validating data quality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets. Running these automated tests as part of your DataOps and Data Observability strategy allows for early detection of discrepancies or errors.
A catalog or a database that lists models, including when they were tested, trained, and deployed. Metadata and artifacts needed for audits. In particular, auditing and testing machine learning systems will rely on many of the tools I’ve described above. There are real, not just theoretical, risks and considerations.
These include internet-scale web and mobile applications, low-latency metadata stores, high-traffic retail websites, Internet of Things (IoT) and time series data, online gaming, and more. Athena is a serverless, interactive service that allows you to query data from a variety of sources in heterogeneous formats, with no provisioning effort.
In this post, we show you how you can convert existing data in an Amazon S3 data lake in Apache Parquet format to Apache Iceberg format to support transactions on the data using Jupyter Notebook based interactive sessions over AWS Glue 4.0. AWS Command Line Interface (AWS CLI) configured to interact with AWS Services.
We introduce you to Amazon Managed Service for Apache Flink Studio and get started querying streaming data interactively using Amazon Kinesis Data Streams. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day.
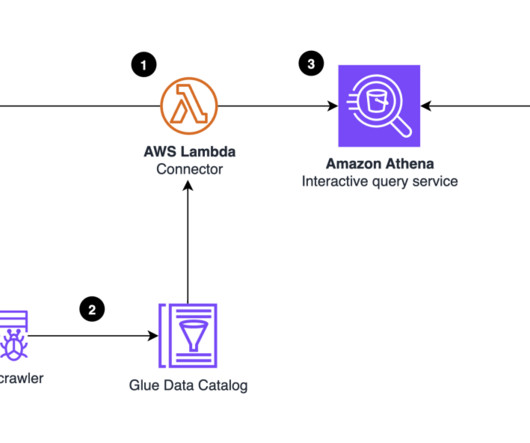
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. connection testing, metadata retrieval, and data preview.
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. from the business interactions), but if not available, then through confirmation techniques of an independent nature. Your Chance: Want to test a professional analytics software?
Trino is an open source distributed SQL query engine designed for interactive analytic workloads. Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. With Amazon EMR 6.10.0
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Testing out a new feature. Identify, hypothesize, test, react. But at the same time, they had to have a real test of an actual feature. You don’t need a beautiful beast to go out and test.
This populates the technical metadata in the business data catalog for each data asset. The business metadata, can be added by business users to provide business context, tags, and data classification for the datasets. Producers control what to share, for how long, and how consumers interact with it.
We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The first component (metadata setup) consumes existing Hive job configurations and generates metadata such as number of parameters, number of actions (steps), and file formats. X Python 3.8 Amazon EMR 6.1
They value NiFi’s visual, no-code, drag-and-drop UI, the 450+ out-of-the-box processors and connectors, as well as the ability to interactively explore data by starting individual processors in the flow and immediately seeing the impact as data streams through the flow. . Interactivity when needed while saving costs.
Efficient metadata management : Unlike Hive Metastore (HMS), which needs to track all Hive table partitions (partition key-value pairs, data location and other metadata), the Iceberg partitions store the data in the Iceberg metadata files on the file system. Multi-function analytics . What’s Next.
Under SAML Signing Certificates , select Actions , and then select View IdP Metadata. Under Configure external identity provider , do the following: Under Service provider metadata , choose Download metadata file to download the IAM Identity Center metadata file and save it on your system. Choose the Sign On tab.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
Everything is being tested, and then the campaigns that succeed get more money put into them, while the others aren’t repeated. This methodology of “test, look at the data, adjust” is at the heart and soul of business intelligence. Your Chance: Want to try a professional BI analytics software?
Metadata Caching. If you have ever interacted with Impala in the past you would have encountered the Catalog Cache Service. As Impala’s adoption grew the catalog service started to experience these growing pains, therefore recently we introduced two new features to alleviate the stress, On-demand Metadata and Zero Touch Metadata.
With the right data catalog tool, organizations can automate enterprise metadata management – including data cataloging, data mapping, data quality and code generation for faster time to value and greater accuracy for data movement and/or deployment projects. A data catalog benefits organizations in a myriad of ways.
With Lake Formation, you can centralize data security and governance using the AWS Glue Data Catalog , letting you manage metadata and data permissions in one place with familiar database-style features. glue:GetUnfilteredTableMetadata – Allows a third-party analytical engine to retrieve unfiltered table metadata from the Data Catalog.
VPC endpoints are created for Amazon S3 and Secrets Manager to interact with other resources. The policies attached to the Amazon MWAA role have full access and must only be used for testing purposes in a secure test environment. Otherwise, it will check the metadata database for the value and return that instead.
For example, AI-supported chat tools help our game designers to: Brainstorm ideas Test complex game mechanics Generate dialogs They act as digital sparring partners that open up new perspectives and accelerate the creative process. billion data records in real-time every day, based on player interactions with its games.
For testing, this post includes a sample AWS Cloud Development Kit (AWS CDK) application. The following sections take you through the steps to deploy, test, and observe the example application. or higher Appropriate AWS credentials for interacting with resources in your AWS account. or higher Apache Maven version 3.8.4
Amazon Athena is a serverless, interactive analytics service built on open source frameworks, supporting open table file formats. Starting today, the Athena SQL engine uses a cost-based optimizer (CBO), a new feature that uses table and column statistics stored in the AWS Glue Data Catalog as part of the table’s metadata.
In today’s world, we increasingly interact with the environment around us through data. The catalog stores the asset’s metadata in RDF. This allows keeping a well-defined representation of the metadata of each asset and enables using a SPARQL endpoint to query it. Researchers used GraphDB to store semantic metadata.
First, the Airflow REST API support enables programmatic interaction with Airflow resources like connections, Directed Acyclic Graphs (DAGs), DAGRuns, and Task instances. Furthermore, the user’s permissions for interacting with the REST API are determined by the Airflow role assigned to them within Amazon MWAA. small instance class.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content