This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata layer Contains metadata files that track table history, schema evolution, and snapshot information. In many operations (like OVERWRITE, MERGE, and DELETE), the query engine needs to know which files or rows are relevant, so it reads the current table snapshot. This is optional for operations like INSERT.
Visualizing the data and interacting on a single screen is no longer a luxury but a business necessity. That’s why we welcome you to the world of interactive dashboards. But before we delve into the bits and pieces of our topic, let’s answer the basic questions: What is an interactive dashboard, and why you need one?
In this post, we use the term vanilla Parquet to refer to Parquet files stored directly in Amazon S3 and accessed through standard query engines like Apache Spark, without the additional features provided by table formats such as Iceberg. When a user requests a time travel query, the typical workflow involves querying a specific snapshot.
For more examples and references to other posts, refer to the following GitHub repository. Querying all snapshots, we can see that we created three snapshots with overwrites after the initial one. For more examples and references to other posts on using XTable on AWS, refer to the following GitHub repository.
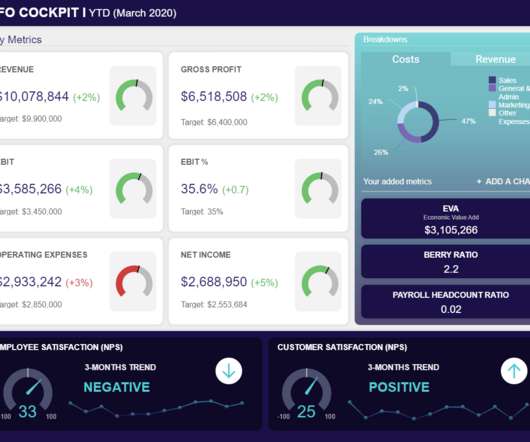
Serving as a central, interactive hub for a host of essential fiscal information, CFO dashboards host dynamic financial KPIs and intuitive analytical tools, as well as consolidate data in a way that is digestible and improves the decision-making process. Your Chance: Want to build your own CFO dashboard completely free? 2) Financial KPIs.
Communication: KPI reports and trackers are visual and interactive, which means that they are incredibly inclusive. To track KPIs and set actionable benchmarks, today’s most forward-thinking businesses use what is often referred to as a KPI tracking system or a key performance indicator report. We offer a 14 day free trial.
For additional information about roles, refer to Requirements for roles used to register locations. Refer to Registering an encrypted Amazon S3 location for guidance. The Iceberg table keeps track of the snapshots. consumer_iceberg$snapshots" limit 10; We can observe that we have generated multiple snapshots.
A static report offers a snapshot of trends, data, and information over a predetermined period to provide insight and serve as a decision-making guide. As humans, we respond far more effectively to visual stimulation than text-based information, which means that interactive reporting makes data and dashboard storytelling more effective.
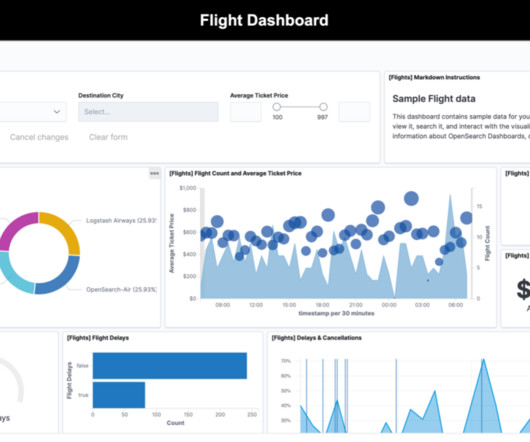
Customers across diverse industries rely on Amazon OpenSearch Service for interactive log analytics, real-time application monitoring, website search, vector database, deriving meaningful insights from data, and visualizing these insights using OpenSearch Dashboards. Under Generate the link as , select Snapshot and choose Copy iFrame code.
Athena is an interactive query service that simplifies data analysis in Amazon Simple Storage Service (Amazon S3) using standard SQL. To gather EIP usage reporting, this solution compares snapshots of the current EIPs, focusing on their most recent attachment within a customizable 3-month period.
A procurement report allows an organization to demonstrate how its procurement activities deliver value for money, contribute to the realization of its broader goals and objectives, and provide a panoramic snapshot of the effectiveness of its procurement strategy. c) Increase the efficiency of crucial KPIs.
To put our definition into a real-world perspective, here’s a hypothetical incremental sales example we’ve created for reference: A green clothing retailer typically sells $14,000 worth of ethical sweaters per month without investing in advertising.
We introduce you to Amazon Managed Service for Apache Flink Studio and get started querying streaming data interactively using Amazon Kinesis Data Streams. Frequent materialized view refreshes on top of constantly changing base tables due to streamed data can lead to snapshot isolation errors. We use two datasets in this post.
The third cost component is durable application backups, or snapshots. This is entirely optional and its impact on the overall cost is small, unless you retain a very large number of snapshots. The cost of durable application backup (snapshots) is $0.023 per GB per month. per hour, and attached application storage costs $0.10
These reports are more digestible when they are generated through online data visualization tools that have numerous interactive dashboard features, to ensure that your business has the right meaningful financial data. This metric is also referred to as “EBIT”, for “earnings before interest and tax”. click to enlarge**.
In our recent webcast , IBM, AWS, customers and partners came together for an interactive session. Refer to the Amazon RDS for Db2 pricing page for instances supported. At what level are snapshot-based backups taken? Answer : We refer to snapshots as storage-level backups. Backup and restore 11.
They are typically built as a software suite that has been abstracted into several interacting components, each owned by a distinct subteam of infrastructure engineers. Most of these subteams interact with only a small subset of subteams upstream or downstream of their subsystem. user behaviors/interests, the internet, etc.).
Data Vault overview For a brief review of the core Data Vault premise and concepts, refer to the first post in this series. For more information, refer to Amazon Redshift database encryption. Automated snapshots retain all of the data required to restore a data warehouse from a snapshot.
To do this, we required the following: A reference cluster snapshot – This ensures that we can replay any tests starting from the same state. For more details about approach we used, including using the Amazon Redshift Simple Replay utility , refer to Compare different node types for your workload using Amazon Redshift.
These labor-intensive evaluations of data quality can only be performed periodically, so at best they provide a snapshot of quality at a particular time. When these assessments are performed manually, they can only be executed periodically, so at best, a data quality assessment provides a snapshot of data quality at a particular time.
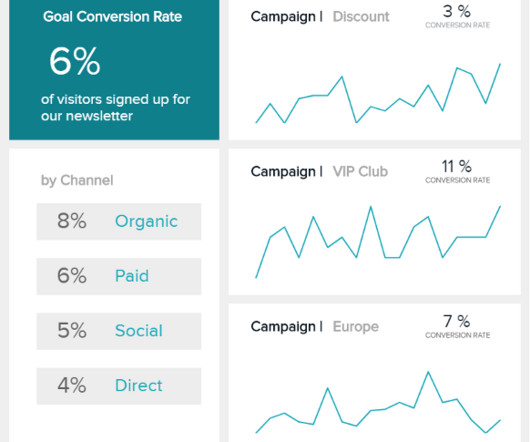
Dashboard reporting refers to putting the relevant business metrics and KPIs in one interface, presenting them visually, dynamic, and in real-time, in the dashboard formats. Highlights: Support 60+ data sources quick sharing links Support TV display Support schedule automatic snapshots of your dashboards to post to Slack. From Google.
To learn more, refer to Exploring new ETL and ELT capabilities for Amazon Redshift from the AWS Glue Studio visual editor. For instructions, refer to Set up IAM permissions for AWS Glue Studio. For more information, refer to Configuring Snowflake connections. Run the first cell to set up an AWS Glue interactive session.
To learn more, refer to About dbt models. To learn more, refer to Materializations and Incremental models. AWS Glue interactive sessions run the SQL statements to create intermediate tables or final tables, views, or materialized views. Data engineers define dbt models for their data representations. and Viewpoint.
Any code or connection interacts with the interface of the gateway only. For comprehensive instructions, refer to Running Spark jobs with the Spark operator. For official guidance, refer to Create a VPC. Refer to create-db-subnet-group for more details. Refer to create-db-subnet-group for more details.
The result is made available to the application by querying the latest snapshot. The snapshot constantly updates through stream processing; therefore, the up-to-date data is provided in the context of a user prompt to the model. For more information, refer to Notions of Time: Event Time and Processing Time.
For more details about OR1 instances, refer to Amazon OpenSearch Service Under the Hood: OpenSearch Optimized Instances (OR1). A Python client set up to deploy OpenSearch Benchmark and interact with the OpenSearch Service domain. For instructions on migration, refer to Migrating to Amazon OpenSearch Service.
AWS has invested in native service integration with Apache Hudi and published technical contents to enable you to use Apache Hudi with AWS Glue (for example, refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started ).
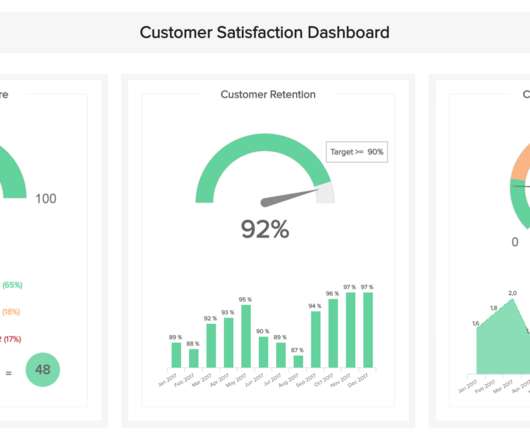
To provide the best possible standards of CS on a consistent basis, understanding how your consumers interact with your business is vital. To ensure that you get optimum value from certain KPIs and metrics, you should set measurement time parameters that will give you a comprehensive snapshot of averages and trends.
This is particularly valuable for Type 2 slowly changing dimension (SCD) and timespan accumulating snapshot facts. For additional details and code samples, refer to New – Amazon Redshift Integration with Apache Spark.
Redshift Test Drive also provides additional features such as a self-hosted analysis UI and the ability to replicate external objects that a Redshift workload may interact with. Take a snapshot of the source Redshift data warehouse. For more details on the individual parameters, refer to the GitHub repo.
To learn more about how to implement your AWS Glue job scripts locally, refer to Develop and test AWS Glue version 3.0 To learn more about how to achieve unit testing locally, refer to Develop and test AWS Glue version 3.0 jobs locally using a Docker container. Test In the testing phase, you check the implementation for bugs.
Centered on leveraging consumer insights to improve your strategies and communications by using a highly data-driven process can also be referred to as Customer Intelligence (CI). If you wish to attract and retain your customers, it’s critical to gain a clear understanding of your customer. Adopting a CI-driven mindset is essential.
Refer appendix section for more information on this feature. The table can be queried using Amazon Athena , a serverless, interactive query service that enables running SQL-like queries on data stored in Amazon S3. Refer to the first stack’s output. Refer to the first stack’s output. Refer to the first stack’s output.
Incremental query refers to a query strategy that focuses on processing and analyzing only the new or updated data within a data lake since the last query. Next, we create an AWS Cloud9 interactive development environment (IDE). Refer to Providing certificates for encrypting data in transit with Amazon EMR encryption for details.
By analyzing the historical report snapshot, you can identify areas for improvement, implement changes, and measure the effectiveness of those changes. For instructions, refer to Amazon DataZone quickstart with AWS Glue data. To learn more about Amazon DataZone, refer to the Amazon DataZone User Guide. option("header", "true").option("inferSchema",
With Amazon Redshift, you can build lake house architectures and perform any kind of analytics, such as interactive analytics , operational analytics , big data processing , visual data preparation , predictive analytics, machine learning , and more. Amazon Redshift is simple to interact with. Deselect Create final snapshot.
This is often referred to as the staging layer , which is the raw copy of the source data. For more about type 2, refer to Simplify data loading into Type 2 slowly changing dimensions in Amazon Redshift. To get started and set up QuickSight, refer to Creating a dataset using a database that’s not autodiscovered.
Architecturally, we chose a serverless model, and the data lake architecture action line refers to all the architectural gaps and challenging features we determined were part of the improvements. For more details, refer to Connection Types and Options for ETL in AWS Glue. AWS Glue supports a wide variety of connection types.
In this series, we talk about Swisscom’s journey of automating Amazon Redshift provisioning as part of the Swisscom One Data Platform (ODP) solution using the AWS Cloud Development Kit (AWS CDK), and we provide code snippets and the other useful references. Given this, Swisscom needed a mechanism for AWS Glue to connect to Amazon Redshift.
In DevOps , the concept of observability has evolved to refer to the end-to-end visibility of a system state as dictated by telemetry data. With so many shifting, interacting and layered components comes as many potential issues and failure points, therefore lots of areas where real-time monitoring becomes a necessity.
In the first stage Knowledge Graph Interaction , the Eligibility Design Assistant provides a variety of filters to subset the data, including: Overall status of the study : Currently limited to “Completed”. LLDI also provides key data points normalized to reference datasets such as UMLS, ChEMBL, and DrugCentral.
KPIs such as subscription renewals to date or leads generated provide a real-time snapshot of business progress toward the annual sales growth goal. Resolution time refers to how long it takes for the issue to be resolved. The success of customer services interactions can be difficult to gauge.
In this blog, we will walk through how we can apply existing enterprise data to better understand and estimate Scope 1 carbon footprint using Amazon Simple Storage Service (S3) and Amazon Athena , a serverless interactive analytics service that makes it easy to analyze data using standard SQL.
Apache Flink connector and catalog architecture Apache Flink uses a connector and catalog to interact with data and metadata. You can refer to Table & SQL Connectors for more information. Refer to Catalogs for more information. For more information, refer to Creating catalogs and using catalogs and Catalogs.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content