This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This data is fed back to the product owners, who can then use it to […] The post Data Mining: The KnowledgeDiscovery of Data appeared first on Analytics Vidhya. Introduction We are living in an era of massive data production.
This is where PubMiner AI comes to help such interdisciplinary teams of biomedical researchers and data scientists in their journey to knowledge extraction. Finally, it enables building a subgraph representing the extracted knowledge, normalized to reference data sets. What is PubMiner AI?
Techniques that both enable (contribute to) and benefit from smart content are content discovery, machine learning, knowledge graphs, semantic linked data, semantic data integration, knowledgediscovery, and knowledge management. Decide and act on the delivered insights and knowledge. Can you find them all?
Pharma has deep roots in human history with centuries of folk pharmaceutical knowledge offering a hit-and-miss range of natural remedies. From this processed data a knowledge graph (KG) is created. As a result, Pharma company analysts save a lot of time and effort and can easily reuse company knowledge.
This weeks guest post comes from KDD (KnowledgeDiscovery and Data Mining). KDD 2020 welcomes submissions on all aspects of knowledgediscovery and data mining, from theoretical research on emerging topics to papers describing the design and implementation of systems for practical tasks. 1989 to be exact.
One of the most imperative features of social BI is its ability to create self-served and user-generated analysis, coupled with the application of business user knowledge. This can be done with the help of socializing ideas within an Enterprise Business Intelligence tool, be it with or without an Enterprise Social Network (ESN).
Phase 4: KnowledgeDiscovery. My aim with any notebook is to enable someone to pick it up without any prior knowledge of the project and fully understand the analysis, decisions made and what the final output means,” Osborne explains. “My 5 Tips for Better Data Science Workflows. Use the Proper Mix of Hardware and Software.
From knowledge graph building to value To enhance the discoverability of information about Ontotext, we aimed at unlocking the value embedded within our content and rendering it readily accessible. Then we build a knowledge graph consisting of custom ontologies (in our case, an extension of schema.org), and custom taxonomies.
These are the so-called supercomputers, led by a smart legion of researchers and practitioners in the fields of data-driven knowledgediscovery. ExaMode, an acronym for Extreme-scale Analytics via Multimodal Ontology Discovery & Enhancement, is a project funded by the European Union, H2020 programme.
Buildings That Almost Think For Themselves About Their Occupants The first paper we are very excited to talk about is KnowledgeDiscovery Approach to Understand Occupant Experience in Cross-Domain Semantic Digital Twins by Alex Donkers, Bauke de Vries and Dujuan Yang.
Various initiatives to create a knowledge graph of these systems have been only partially successful due to the depth of legacy knowledge, incomplete documentation and technical debt incurred over decades. Summarization Summarization remains the top use case for generative AI (gen AI) technology.
One of the most imperative features of social BI is its ability to create self-served and user-generated analysis, coupled with the application of business user knowledge. This can be done with the help of socializing ideas within an Enterprise Business Intelligence tool, be it with or without an Enterprise Social Network (ESN).
Data analysis is a type of knowledgediscovery that gains insights from data and drives business decisions. Professional data analysts must have a wealth of business knowledge in order to know from the data what has happened and what is about to happen. For super rookies, the first task is to understand what data analysis is.
Although there is still no single, universally accepted definition, there have been various attempts at it – such as in Towards a Definition of Knowledge Graphs. Yet, the concept of knowledge graphs still lives without an agreed-upon description or shared understanding. There is diversity in terms of its implementation as well.
In this post you will discover the aspects of the Semantic Web that are key to enterprise data, knowledge and content management. What can it do and how are enterprise knowledge graphs related to it? While Semantic Web is often condemned for being too academic, two of its incarnations already enjoy massive adoption. What is it?
It is a process of using knowledgediscovery tools to mine previously unknown and potentially useful knowledge. It is an active method of automatic discovery. With the advancement of information construction, enterprises have accumulated massive data base. Hoewever, it can be a double-edged sword for enterprises.
But it has enriched us in terms of identifying key needs for those looking to build a simple prototype in order to demonstrate the power of semantic technology, linked data and knowledge graphs. There, they can turn the acquired knowledge into a practical solution to their specific business case and strategize about its implementation.
Insufficient training data in the minority class — In domains where data collection is expensive, a dataset containing 10,000 examples is typically considered to be fairly large. If, however, the dataset is imbalanced with a class ratio of 100:1, this means that it contains only 100 examples of the minority class. Generation of artificial examples.
Well, it’s all thanks to knowledge graphs. Knowledge graphs are changing the game A knowledge graph is a data model that uses semantics to represent real-world entities and the relationships between them. How do they know all this? This can lead to operational cost cutting and improve competitiveness.
Solution overview The AWS Serverless Data Analytics Pipeline reference architecture provides a comprehensive, serverless solution for ingesting, processing, and analyzing data. At its core, this architecture features a centralized data lake hosted on Amazon Simple Storage Service (Amazon S3), organized into raw, cleaned, and curated zones.
For example in ads, experiments using cookies (users) as experimental units are not suited to capture the impact of a treatment on advertisers or publishers nor their reaction to it. Recently, we presented some basic insights from our effort to measure and predict long-term effects at KDD 2015 [1].
Data mining is the process of discovering these patterns among the data and is therefore also known as KnowledgeDiscovery from Data (KDD). Domain Knowledge. The foremost step of this process is to possess relevant domain knowledge regarding the problem at hand. Data Mining Models.
The richness of data, if it can be discovered, enables the discovery of novel therapies, causal relationships or, just as important, retrieving existing negative results so that the company doesn’t spend millions of dollars to discover what is already known not to work. It is from those connections that new discoveries are made.
This post continues the series of posts we started with At Center Stage: 2 Ontotext Webinars About Reasoning with Big Knowledge Graphs and Power of Graph Analytics. The first Ontotext webinar that takes center stage in this post is Reasoning with Big Knowledge Graphs: Choices, Pitfalls and Proven Recipes. Why is that?
Knowledge Graphs are the Warp and Weft of a Data Fabric. Knowledge graphs can be used to foster text analysis and make this easier, as in the Ontotext Platform. In other words, knowledge graphs solve the data silo problem by making it irrelevant. What Makes a Data Fabric? It is a buzzword.
To ensure the metadata extracted is of high-quality, Ontotext uses knowledge graphs to increase the performance of its text analysis services. The knowledge graph holds the ontology, the description of the concepts and their relationships, and the existing instances of those concepts and relationships. Semantics Makes It Powerful.
As 2019 comes to an end, we at Ontotext are taking stock of the most fascinating things we have done to empower knowledge management and knowledgediscovery this year. In 2019, Ontotext open-sourced the front-end and engine plugins of GraphDB to make the development and operation of knowledge graphs easier and richer.
Seen through the three days of Ontotext’s Knowledge Graph Forum (KGF) this year, complexity was not only empowering but key to the growth of knowledge and innovation. “Complexity is empowering”, argues Howard G. Cunningham. The question is not how to avoid complexity but how to embrace it and take advantage of it.”
However, for this to happen, there needs to be context for the data to become knowledge. Worse, and according to Gartner, upward of 80% of enterprise data today is unstructured which further exacerbates the loss of knowledge, insights, and the wisdom needed to make effective business choices.
However, if one changes assignment weights when there are time-based confounders, then ignoring this complexity can lead to biased inference in an OCE. In the case of MABs, ignoring this complexity can also lead to poor total reward, making it counterproductive towards its intended purpose.
When analysing pharmacokinetic data to determine the degree of exposure of a drug and associated pharmacokinetic parameters (e.g., clearance, elimination half-life, maximum observed concentration ( ), time where the maximum concentration was observed ( ), Non-Compartmental Analysis (NCA) is usually the preferred approach [1]. Mean residence time.
And, the added value of SIM cards and knowledge graphs would be much smaller without the internet, particularly WWW – the global information space that facilitates communication. For example, by using unique identifiers for each data item, knowledge graphs make it easy to identify resources across different datasets and systems.
Specifically, the increasing amount of data being generated and collected, and the need to make sense of it, and its use in artificial intelligence and machine learning, which can benefit from the structured data and context provided by knowledge graphs. We get this question regularly. Linked Data, subscriptions, purchased datasets, etc.).
The growth of large language models drives a need for trusted information and capturing machine-interpretable knowledge, requiring businesses to recognize the difference between a semantic knowledge graph and one that isn’t—if they want to leverage emerging AI technologies and maintain a competitive edge. What is a knowledge graph?
But it has enriched us in terms of identifying key needs for those looking to build a simple prototype in order to demonstrate the power of semantic technology, linked data and knowledge graphs. There, they can turn the acquired knowledge into a practical solution to their specific business case and strategize about its implementation.
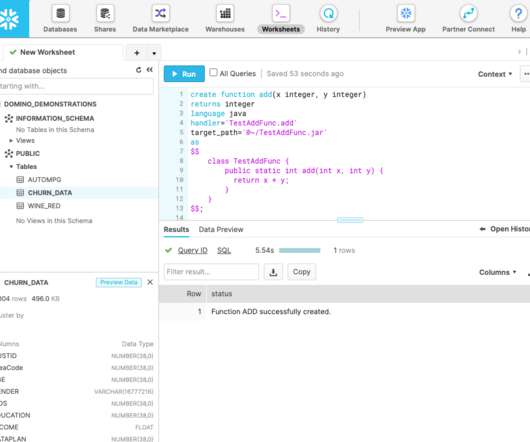
Generally speaking, a User Defined Function (UDF), in the context of relational databases, is a mechanism for extending the functionality of the underlying database. Moreover, such a function can be evaluated within standard SQL queries, but it can be written in a language different to SQL. Most importantly, UDFs are executed directly in Snowflake.
We apply Artificial Intelligence techniques to understand the value locked in this data so we can extract knowledge that can benefit people. Some of this knowledge is locked and the company cannot access it. into structured knowledge that can be processed by machines. On March 19, 2019, Economy.bg Machines Against Fake News.
In our previous post, we covered the basics of how the Ontotext and metaphacts joint solution based on GraphDB and metaphactory helps customers accelerate their knowledge graph journey and generate value from it in a matter of days. Today, users from the general public, journalists, etc. Semantic Data Integration With GraphDB.
In the examples above, we might use our estimates to choose ads, decide whether to show a user images, or figure out which videos to recommend. These decisions are often business-critical, so it is essential for data scientists to understand and improve the regressions that inform them. The size and importance of these systems makes this hard.
This can be attributed to the popularity that machine learning algorithms, and more specifically deep learning, has been gaining in various domains. It is not possible to fully understand the inferential process of a deep neural network and to prove that it would generalise as expected. According to Fox et al.,
This is repeated until ChatGPT has all the necessary knowledge to answer the question or the limit of iterations is reached. The prompt instructs ChatGPT to only generate queries if it doesn’t have the necessary knowledge for the question. This dramatically simplifies the interaction with complex databases and analytics systems.
Indeed, understanding and facilitating user choices through improvements in the service offering is much of what LSOS data science teams do. As with any enterprise, the goal of the service provider is to better satisfy its users and further its business objectives. It is certainly true that for any given effect, statistical significance is an SMOD.
The result is that experimenters can’t afford to be sloppy about quantifying uncertainty. Estimating confidence intervals with precision and at scale was one of the early wins for statisticians at Google. It has remained an important area of investment for us over the years. Both estimators are unbiased. But the latter estimator has less variance.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content