This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
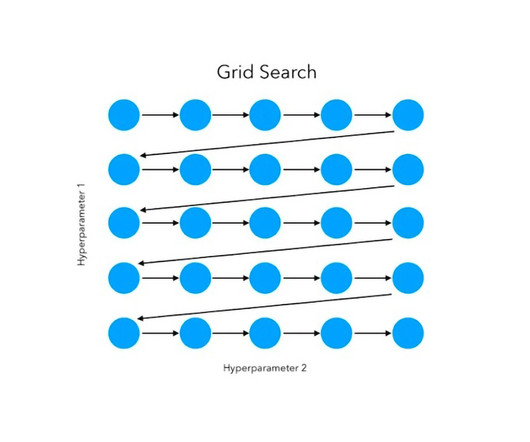
Introduction One of the toughest things about making powerful models in machine learning is fiddling with many levels. Hyperparameter optimization—adjusting those settings to end up with something that’s not horrible—might be the most important part of it all.
The post ML Hyperparameter Optimization App using Streamlit appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon About Streamlit Streamlit is an open-source Python library that assists developers in creating interactive graphical user interfaces for their systems. Frontend […].
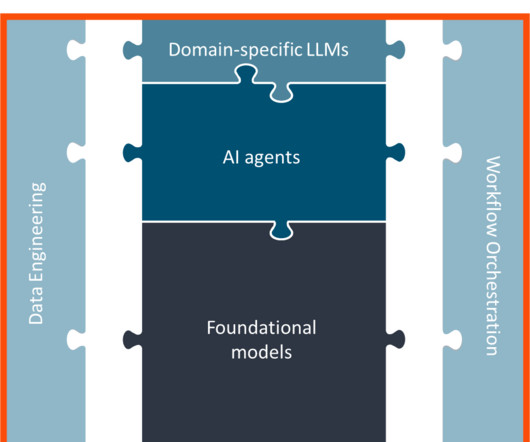
Introduction Fine-tuning enables large language models to better align with specific tasks, teach new facts, and incorporate new information. Fine-tuning significantly improves performance compared to prompting, typically surpassing larger models due to its speed and cost-effectiveness.
It will be engineered to optimize decision-making and enhance performance in real-world complex systems. Introduction Reinforcement Learning from Human Factors/feedback (RLHF) is an emerging field that combines the principles of RL plus human feedback.
If the last few years have illustrated one thing, it’s that modeling techniques, forecasting strategies, and data optimization are imperative for solving complex business problems and weathering uncertainty. Experience how efficient you can be when you fit your model with actionable data.
Large language models (LLMs) just keep getting better. In just about two years since OpenAI jolted the news cycle with the introduction of ChatGPT, weve already seen the launch and subsequent upgrades of dozens of competing models. From Llama3.1 to Gemini to Claude3.5 From Llama3.1 to Gemini to Claude3.5
The most challenging part of integrating AI into an application is […] The post Mastering AI Optimization and Deployment with Intel’s OpenVINO Toolkit appeared first on Analytics Vidhya. Introduction We talk about AI almost daily due to its growing impact in replacing humans’ manual work.
In the ever-evolving landscape of large language models, DeepSeek V3 vs LLaMA 4 has become one of the hottest matchups for developers, researchers, and AI enthusiasts alike.
They had bugs, particularly if they were optimizing your code (were optimizing compilers a forerunner of AI?). Specifically, could ChatGPT N (for large N) quit the game of generating code in a high-level language like Python, and produce executable machine code directly, like compilers do today? It’s not really an academic question.
For decades, operations research professionals have been applying mathematical optimization to address challenges in the field of supply chain planning, manufacturing, energy modeling, and logistics. This guide is ideal if you: Want to understand the concept of mathematical optimization.
In the dynamic realm of language model development, a recent groundbreaking paper titled “Direct Preference Optimization (DPO)” by Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Chris Manning, and Chelsea Finn, has captured the attention of AI luminaries like Andrew Ng.
Let’s start by considering the job of a non-ML software engineer: writing traditional software deals with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly model in the code. However, the concept is quite abstract. Can’t we just fold it into existing DevOps best practices? Why: Data Makes It Different.
Microsoft’s Phi-4 model is available on Hugging Face, offering developers a powerful tool for advanced text generation and reasoning tasks. In this article, well walk you through the steps to access and use Phi-4, from creating a Hugging Face account to generating outputs with the model.
Many of these go slightly (but not very far) beyond your initial expectations: you can ask it to generate a list of terms for search engine optimization, you can ask it to generate a reading list on topics that you’re interested in. It’s important to understand that ChatGPT is not actually a language model. Or a text adventure game.
Speaker: Maher Hanafi, VP of Engineering at Betterworks & Tony Karrer, CTO at Aggregage
He'll delve into the complexities of data collection and management, model selection and optimization, and ensuring security, scalability, and responsible use. There's no question that it is challenging to figure out where to focus and how to advance when it’s a new field that is evolving everyday. Save your seat and register today!
The company has already rolled out a gen AI assistant and is also looking to use AI and LLMs to optimize every process. The company has already rolled out a gen AI assistant and is also looking to use AI and LLMs to optimize every process. Generally, there’s optimism and a positive mindset when heading into AI.”
Modivcare, which provides services to better connect people with care, is on a transformative journey to optimize its services by implementing a new product operating model. Whats the context for the new product operating model? What was the model you were using before? What was the model you were using before?
Alibabas latest model, QwQ-32B-Preview , has gained some impressive reviews for its reasoning abilities. I also tried a few competing models: GPT-4 o1 and Gemma-2-27B. GPT-4 o1 was the first model to claim that it had been trained specifically for reasoning. How do you test a reasoning model? So lets go! Hmm, interesting.
This new paradigm of the operating model is the hallmark of successful organizational transformation. Otherwise, companies will struggle to realize business value with AI/ML capabilities left to endure high cloud cost expenses, as it has been for many companies in 2024 for AI solutions.
This customer success playbook outlines best in class data-driven strategies to help your team successfully map and optimize the customer journey, including how to: Build a 360-degree view of your customer and drive more expansion opportunities. Satisfaction won’t cut it. But where do you start? Download the playbook today!
By 2026, hyperscalers will have spent more on AI-optimized servers than they will have spent on any other server until then, Lovelock predicts. In some cases, the AI add-ons will be subscription models, like Microsoft Copilot, and sometimes, they will be free, like Salesforce Einstein, he says. The key message was, ‘Pace yourself.’”
In this article, we will explore how PEFT methods optimize the adaptation of Large Language Models (LLMs) to specific tasks. We will unravel the advantages and disadvantages of PEFT, […] The post Parameter-Efficient Fine-Tuning of Large Language Models with LoRA and QLoRA appeared first on Analytics Vidhya.
This is Dell Technologies’ approach to helping businesses of all sizes enhance their AI adoption, achieved through the combined capabilities with NVIDIA—the building blocks for seamlessly integrating AI models and frameworks into their operations. This is done through its broad portfolio of AI-optimized infrastructure, products, and services.
It’s a full-fledged platform … pre-engineered with the governance we needed, and cost-optimized. One of the world’s largest risk advisors and insurance brokers launched a digital transformation five years ago to better enable its clients to navigate the political, social, and economic waves rising in the digital information age.
It’s a full-fledged platform … pre-engineered with the governance we needed, and cost-optimized. One of the world’s largest risk advisors and insurance brokers launched a digital transformation five years ago to better enable its clients to navigate the political, social, and economic waves rising in the digital information age.
It can support AI/ML processes with data preparation, model validation, results visualization and modeloptimization. Rapidminer Studio is its visual workflow designer for the creation of predictive models.
Reitz has set up a global service model with hubs in three time zones that operate according to the follow-the-sun approach. Reitz has set up a global service model with hubs in three time zones that operate according to the follow-the-sun approach. It all starts with a sense of presence, both remote and local.
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., at Facebook—both from 2020.
Instead of seeing digital as a new paradigm for our business, we over-indexed on digitizing legacy models and processes and modernizing our existing organization. This only fortified traditional models instead of breaking down the walls that separate people and work inside our organizations. We optimized. We automated.
PyTorch has unveiled torchtune, a new PyTorch-native library aimed at streamlining the process of fine-tuning large language models (LLMs). It offers a range of features and tools to empower developers in customizing and optimizing LLMs for various use cases.
Introduction Training a Deep Learning model from scratch can be a tedious task. You have to find the right training weights, get the optimal learning rates, find the best hyperparameters and the architecture that will best suit your data and model.
IT leader and former CIO Stanley Mwangi Chege has heard executives complain for years about cloud deployments, citing rapidly escalating costs and data privacy challenges as top reasons for their frustrations. They, too, were motivated by data privacy issues, cost considerations, compliance concerns, and latency issues.
Its an offshoot of enterprise architecture that comprises the models, policies, rules, and standards that govern the collection, storage, arrangement, integration, and use of data in organizations. Optimize data flows for agility. AI and machine learning models. Ensure security and access controls. Curate the data.
According to Google, Gemini, optimized for different sizes: Ultra, Pro and Nano, is their most capable and general model yet, with state-of-the-art performance across many leading benchmarks. In the ever-evolving world of artificial intelligence, Google has now made a groundbreaking leap with its latest creation, Gemini AI.
Everyone may answer and say, informed decision making, generate profit, improve customer relations optimization. For a smaller airport in Canada, data has grown to be its North Star in an industry full of surprises. Ryan: First, I wanted to build a culture. Data needs to be an asset and not a commodity. That obviously stunned me.
Recent research shows that 67% of enterprises are using generative AI to create new content and data based on learned patterns; 50% are using predictive AI, which employs machine learning (ML) algorithms to forecast future events; and 45% are using deep learning, a subset of ML that powers both generative and predictive models.
Using the companys data in LLMs, AI agents, or other generative AI models creates more risk. Build up: Databases that have grown in size, complexity, and usage build up the need to rearchitect the model and architecture to support that growth over time.
DeepMind’s new model, Gato, has sparked a debate on whether artificial general intelligence (AGI) is nearer–almost at hand–just a matter of scale. Gato is a model that can solve multiple unrelated problems: it can play a large number of different games, label images, chat, operate a robot, and more. I don’t think so.
You either move the data to the [AI] model that typically runs in cloud today, or you move the models to the machine where the data runs,” she adds. “I I see it in terms of helping to optimize the code, modernize the code, renovate the code, and assist developers in maintaining that code.” I believe you’re going to see both.”
Throughout this article, well explore real-world examples of LLM application development and then consolidate what weve learned into a set of first principlescovering areas like nondeterminism, evaluation approaches, and iteration cyclesthat can guide your work regardless of which models or frameworks you choose. Which multiagent frameworks?
Opkey, a startup with roots in ERP test automation, today unveiled its agentic AI-powered ERP Lifecycle Optimization Platform, saying it will simplify ERP management, reduce costs by up to 50%, and reduce testing time by as much as 85%. The problem is how you are implementing it, how you are testing it, how you are supporting it.
Additionally, 90% of respondents intend to purchase or leverage existing AI models, including open-source options, when building AI applications, while only 10% plan to develop their own. Companies are seeking ways to enhance reporting, meet regulatory requirements, and optimize IT operations. Nutanix commissioned U.K.
Take for instance large language models (LLMs) for GenAI. Businesses will need to invest in hardware and infrastructure that are optimized for AI and this may incur significant costs. Contextualizing patterns and identifying potential threats can minimize alert fatigue and optimize the use of resources.
We can collect many examples of what we want the program to do and what not to do (examples of correct and incorrect behavior), label them appropriately, and train a model to perform correctly on new inputs. Those tools are starting to appear, particularly for building deep learning models. Instead, we can program by example.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content