This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For all the excitement about machinelearning (ML), there are serious impediments to its widespread adoption. In addition to newer innovations, the practice borrows from model risk management, traditional model diagnostics, and software testing. Not least is the broadening realization that ML models can fail. Residual analysis.
As companies use machinelearning (ML) and AI technologies across a broader suite of products and services, it’s clear that new tools, best practices, and new organizational structures will be needed. What cultural and organizational changes will be needed to accommodate the rise of machine and learning and AI?
Data is typically organized into project-specific schemas optimized for business intelligence (BI) applications, advanced analytics, and machinelearning. This involves setting up automated, column-by-column quality tests to quickly identify deviations from expected values and catch emerging issues before they impact downstream layers.
A look at the landscape of tools for building and deploying robust, production-ready machinelearning models. Our surveys over the past couple of years have shown growing interest in machinelearning (ML) among organizations from diverse industries. Model operations, testing, and monitoring.
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. People have been building data products and machinelearning products for the past couple of decades.
Testing and Data Observability. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machinelearning, AI, data governance, and data security operations. . Dagster / ElementL — A data orchestrator for machinelearning, analytics, and ETL. .
Hypothesis testing is used to look if there is any significant relationship, and we report it using a p-value. Measuring the strength of that relationship […]. Introduction One of the most important applications of Statistics is looking into how two or more variables relate.
As a result, many data teams were not as productive as they might be, with time and effort spent on manually troubleshooting data-quality issues and testing data pipelines. The ability to monitor and measure improvements in data quality relies on instrumentation.
Wetmur says Morgan Stanley has been using modern data science, AI, and machinelearning for years to analyze data and activity, pinpoint risks, and initiate mitigation, noting that teams at the firm have earned patents in this space. I am excited about the potential of generative AI, particularly in the security space, she says.
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machinelearning (ML). AI products are automated systems that collect and learn from data to make user-facing decisions. We won’t go into the mathematics or engineering of modern machinelearning here.
This role includes everything a traditional PM does, but also requires an operational understanding of machinelearning software development, along with a realistic view of its capabilities and limitations. In addition, the Research PM defines and measures the lifecycle of each research product that they support.
Much has been written about struggles of deploying machinelearning projects to production. This approach has worked well for software development, so it is reasonable to assume that it could address struggles related to deploying machinelearning in production too. An Overarching Concern: Correctness and Testing.
Most of these rules focus on the data, since data is ultimately the fuel, the input, the objective evidence, and the source of informative signals that are fed into all data science, analytics, machinelearning, and AI models. Test early and often. Test and refine the chatbot. Suggestion: take a look at MACH architecture.)
Download the MachineLearning Project Checklist. Planning MachineLearning Projects. Machinelearning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. More organizations are investing in machinelearning than ever before.
We are very excited to announce the release of five, yes FIVE new AMPs, now available in Cloudera MachineLearning (CML). In addition to the UI interface, Cloudera MachineLearning exposes a REST API that can be used to programmatically perform operations related to Projects, Jobs, Models, and Applications.
Similarly, in “ Building MachineLearning Powered Applications: Going from Idea to Product ,” Emmanuel Ameisen states: “Indeed, exposing a model to users in production comes with a set of challenges that mirrors the ones that come with debugging a model.”. require not only disclosure, but also monitored testing.
GSK had been pursuing DataOps capabilities such as automation, containerization, automated testing and monitoring, and reusability, for several years. Workiva also prioritized improving the data lifecycle of machinelearning models, which otherwise can be very time consuming for the team to monitor and deploy.
Fractal’s recommendation is to take an incremental, test and learn approach to analytics to fully demonstrate the program value before making larger capital investments. There is usually a steep learning curve in terms of “doing AI right”, which is invaluable. What is the most common mistake people make around data?
Technical sophistication: Sophistication measures a team’s ability to use advanced tools and techniques (e.g., PyTorch, TensorFlow, reinforcement learning, self-supervised learning). Technical competence: Competence measures a team’s ability to successfully deliver on initiatives and projects. Conclusion.
A DataOps Engineer can make test data available on demand. We have automated testing and a system for exception reporting, where tests identify issues that need to be addressed. It then autogenerates QC tests based on those rules. You can track, measure and create graphs and reporting in an automated way.
DataOps introduces agility by advocating for: Measuring data quality early : Data quality leaders should begin measuring and assessing data quality even before perfect standards are in place. Early measurements provide valuable insights that can guide future improvements. Measuring and Refining : DataOps is an iterative process.
Fortunately, new advances in machinelearning technology can help mitigate many of these risks. Therefore, you will want to make sure that your cryptocurrency wallet or service is protected by machinelearning technology. In 2018, researchers used data mining and machinelearning to detect Ponzi schemes in Ethereum.
Machinelearning is playing a very important role in improving the functionality of task management applications. However, recent advances in applying transfer learning to NLP allows us to train a custom language model in a matter of minutes on a modest GPU, using relatively small datasets,” writes author Euan Wielewski.
This kind of humility is likely to deliver more meaningful progress and a more measured understanding of such progress. Learning how to ace Space Invaders does not interfere with or displace the ability to carry out a chat conversation. For example, how many training examples does it take to learn something?
In this post, we outline planning a POC to measure media effectiveness in a paid advertising campaign. We chose to start this series with media measurement because “Results & Measurement” was the top ranked use case for data collaboration by customers in a recent survey the AWS Clean Rooms team conducted.
This type of structure is foundational at REA for building microservices and timely data processing for real-time and batch use cases like time-sensitive outbound messaging, personalization, and machinelearning (ML). We obtained a more comprehensive understanding of the cluster’s performance by conducting these various test scenarios.
The objective of this blog is to show how to use Cloudera MachineLearning (CML) , running Cloudera Data Platform (CDP) , to build a predictive maintenance model based on advanced machinelearning concepts. The Process. Airlines design their aircraft to operate at 99.999% reliability. Fig 1: Turbofan jet engine.
Third-party testing and validation can help CIOs find security products that do what they say they do and meet the specific infrastructure needs of their organization. Even worse, some technology testing firms still allow vendors to manipulate their methodologies to skew the test results in their favor.
Model developers will test for AI bias as part of their pre-deployment testing. Quality test suites will enforce “equity,” like any other performance metric. Continuous testing, monitoring and observability will prevent biased models from deploying or continuing to operate. Companies Commit to Remote.
If you don’t believe me, feel free to test it yourself with the six popular NLP cloud services and libraries listed below. In a test done during December 2018, of the six engines, the only medical term (which only two of them recognized) was Tylenol as a product. IBM Watson NLU. Azure Text Analytics. spaCy Named Entity Visualizer.
In our previous post , we talked about how red AI means adding computational power to “buy” more accurate models in machinelearning , and especially in deep learning. We also talked about the increased interest in green AI, in which we not only measure the quality of a model based on accuracy but also how big and complex it is.
There is measurable progress, however, as data from the company’s connected products are collected in its own platform, where customers have access to information via a portal. “In The company is also applying machinelearning (ML) to gather information from various public sources that can be used internally for market and product analysis.
Some will argue that observability is nothing more than testing and monitoring applications using tests, metrics, logs, and other artifacts. Below we will explain how to virtually eliminate data errors using DataOps automation and the simple building blocks of data and analytics testing and monitoring. . Tie tests to alerts.
In addition, they can use statistical methods, algorithms and machinelearning to more easily establish correlations and patterns, and thus make predictions about future developments and scenarios. If a database already exists, the available data must be tested and corrected.
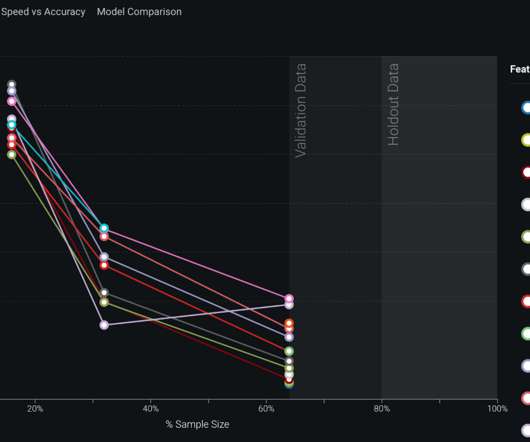
In this example, the MachineLearning (ML) model struggles to differentiate between a chihuahua and a muffin. blueberry spacing) is a measure of the model’s interpretability. MachineLearning Model Lineage. MachineLearning Model Visibility . Figure 04: Applied MachineLearning Prototypes (AMPs).
Machinelearning (ML) models are computer programs that draw inferences from data — usually lots of data. As the industry’s understanding of AI bias matures, model developers are getting better at defining and measuring bias. When you buy a car, you can be sure that the factory has tested every component and subsystem.
Data quality must be embedded into how data is structured, governed, measured and operationalized. Implementing Service Level Agreements (SLAs) for data quality and availability sets measurable standards, promoting responsibility and trust in data assets. Continuous measurement of data quality. Accountability and embedded SLAs.
Often seen as the highest foe-friend of the human race in movies ( Skynet in Terminator, The Machines of Matrix or the Master Control Program of Tron), AI is not yet on the verge to destroy us, in spite the legit warnings of some reputed scientists and tech-entrepreneurs. 1 for data analytics trends in 2020.
Organizations are able to monitor integrity, quality drift, performance trends, real-time demand, SLA (service level agreement) compliance metrics, and anomalous behaviors (in devices, applications, and networks) to provide timely alerting, early warnings, and other confidence measures. “Don’t be a SOAR loser!
You can use Amazon Redshift to analyze structured and semi-structured data and seamlessly query data lakes and operational databases, using AWS designed hardware and automated machinelearning (ML)-based tuning to deliver top-tier price performance at scale. Amazon Redshift delivers price performance right out of the box.
In this paper, I show you how marketers can improve their customer retention efforts by 1) integrating disparate data silos and 2) employing machinelearning predictive analytics. Your marketing strategy is only as good as your ability to deliver measurable results. genetic counseling, genetic testing).
Yet, before any serious data interpretation inquiry can begin, it should be understood that visual presentations of data findings are irrelevant unless a sound decision is made regarding scales of measurement. Interval: a measurement scale where data is grouped into categories with orderly and equal distances between the categories.
In the context of Data in Place, validating data quality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets. Running these automated tests as part of your DataOps and Data Observability strategy allows for early detection of discrepancies or errors.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content