This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why companies are turning to specialized machinelearning tools like MLflow. A few years ago, we started publishing articles (see “Related resources” at the end of this post) on the challenges facing data teams as they start taking on more machinelearning (ML) projects. The upcoming 0.9.0
This article was published as a part of the Data Science Blogathon. A centralized location for research and production teams to govern models and experiments by storing metadata throughout the ML model lifecycle. A Metadata Store for MLOps appeared first on Analytics Vidhya. Keeping track of […]. The post Neptune.ai?—?A
This article was published as a part of the Data Science Blogathon. Any type of contextual information, like device context, conversational context, and metadata, […]. Any type of contextual information, like device context, conversational context, and metadata, […].
Just 20% of organizations publish data provenance and data lineage. Almost half (48%) of respondents say they use data analysis, machinelearning, or AI tools to address data quality issues. These include the basics, such as metadata creation and management, data provenance, data lineage, and other essentials.
Improve accuracy and resiliency of analytics and machinelearning by fostering data standards and high-quality data products. In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machinelearning applications. This process is shown in the following figure.
In 2017, we published “ How Companies Are Putting AI to Work Through Deep Learning ,” a report based on a survey we ran aiming to help leaders better understand how organizations are applying AI through deep learning. We found companies were planning to use deep learning over the next 12-18 months.
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machinelearning (ML). AI products are automated systems that collect and learn from data to make user-facing decisions. We won’t go into the mathematics or engineering of modern machinelearning here.
In their wisdom, the editors of the book decided that I wrote “too much” So, they correctly shortened my contribution by about half in the final published version of my Foreword for the book. I publish this in its original form in order to capture the essence of my point of view on the power of graph analytics.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machinelearning services to streamline the user journey from data to insight.
For instance, Domain A will have the flexibility to create data products that can be published to the divisional catalog, while also maintaining the autonomy to develop data products that are exclusively accessible to teams within the domain. A data portal for consumers to discover data products and access associated metadata.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
To achieve this, they plan to use machinelearning (ML) models to extract insights from data. Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products. The data security officer sets permissions in Amazon DataZone to allow users to access the data portal.
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machinelearning models from malicious actors. Like many others, I’ve known for some time that machinelearning models themselves could pose security risks. Data poisoning attacks. General concerns.
In this example, the MachineLearning (ML) model struggles to differentiate between a chihuahua and a muffin. We will learn what it is, why it is important and how Cloudera MachineLearning (CML) is helping organisations tackle this challenge as part of the broader objective of achieving Ethical AI.
Extract, transform, and load (ETL) is the process of combining, cleaning, and normalizing data from different sources to prepare it for analytics, artificial intelligence (AI), and machinelearning (ML) workloads. The data is also registered in the Glue Data Catalog , a metadata repository.
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data fabric Metadata-rich integration layer across distributed systems. Implementation complexity, relies on robust metadata management.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machinelearning (ML) models and AI-powered applications. Collaboration is seamless, with straightforward publishing and subscribing workflows, fostering a more connected and efficient work environment.
Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, data lake analytics, machinelearning (ML), and data monetization.
This fragmented, repetitive, and error-prone experience for data connectivity is a significant obstacle to data integration, analysis, and machinelearning (ML) initiatives. If you want to revert a draft notebook to its last published state, choose Revert to published version to roll back to the most recently published version.
It focuses on the key aspect of the solution, which was enabling data providers to automatically publish data assets to Amazon DataZone, which served as the central data mesh for enhanced data discoverability. Data domain producers publish data assets using datasource run to Amazon DataZone in the Central Governance account.
Metadata enrichment is about scaling the onboarding of new data into a governed data landscape by taking data and applying the appropriate business terms, data classes and quality assessments so it can be discovered, governed and utilized effectively.
Instead of a central data platform team with a data warehouse or data lake serving as the clearinghouse of all data across the company, a data mesh architecture encourages distributed ownership of data by data producers who publish and curate their data as products, which can then be discovered, requested, and used by data consumers.
This data needs to be ingested into a data lake, transformed, and made available for analytics, machinelearning (ML), and visualization. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views.
Companies such as Adobe , Expedia , LinkedIn , Tencent , and Netflix have published blogs about their Apache Iceberg adoption for processing their large scale analytics datasets. . In CDP we enable Iceberg tables side-by-side with the Hive table types, both of which are part of our SDX metadata and security framework.
Aptly named, metadata management is the process in which BI and Analytics teams manage metadata, which is the data that describes other data. In other words, data is the context and metadata is the content. Without metadata, BI teams are unable to understand the data’s full story. It is published by Robert S.
Use business terms to search, share, and access cataloged data, making data accessible to all the configured users to learn more about data they want to use with the business glossary. Automate data discovery and cataloging with machinelearning (ML).
What’s covered in this post is already implemented and available in the Guidance for Connecting Data Products with Amazon DataZone solution, published in the AWS Solutions Library. It offers AWS Glue connections and AWS Glue crawlers as a means to capture the data asset’s metadata easily from their source database and keep it up to date.
Fusion Data Intelligence — which can be viewed as an updated avatar of Fusion Analytics Warehouse — combines enterprise data, ready-to-use analytics along with prebuilt AI and machinelearning models to deliver business intelligence.
The new feature, which Claire Cheng, vice president of machinelearning and AI engineering at Salesforce said was in the works last month , has been launched as the Prompt Builder and has been made generally available.
Hydro is powered by Amazon MSK and other tools with which teams can move, transform, and publish data at low latency using event-driven architectures. In the future, we plan to profile workloads based on metadata, cross-check them with capacity metrics, and place them in the appropriate MSK cluster.
This launch brings together widely adopted AWS machinelearning (ML) and analytics capabilities and provides an integrated experience for analytics and AI with unified access to data and built-in governance. These metadata tables are stored in S3 Tables, the new S3 storage offering optimized for tabular data. With AWS Glue 5.0,
Solution overview OneData defines three personas: Publisher – This role includes the organizational and management team of systems that serve as data sources. Provide and keep up to date with technical metadata for loaded data. Use the latest data published by the publisher to update data as needed.
These services include the ability to auto-discover and classify data, to detect sensitive information, to analyze data quality, to link business terms to technical metadata and to publish data to the knowledge catalog.
Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. This metadata file is later used to read source file names during processing into the staging layer. The Redshift publish zone is a different set of tables in the same Redshift provisioned cluster.
analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of data warehouses and data lakes, aiming to support AI, BI, ML, and data engineering on a single platform.” This is the promise of the modern data lakehouse architecture.
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. Centralized catalog for published data – Multiple producers release data currently governed by their respective entities. For consumer access, a centralized catalog is necessary where producers can publish their data assets.
We have been working hard to build our cloud-native data services on Cloudera Data Platform (CDP), which include CDP Data Warehouse, CDP Operational Database, CDP MachineLearning, CDP Data Engineering and CDP Data Flow. Gartner and Magic Quadrant are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S.
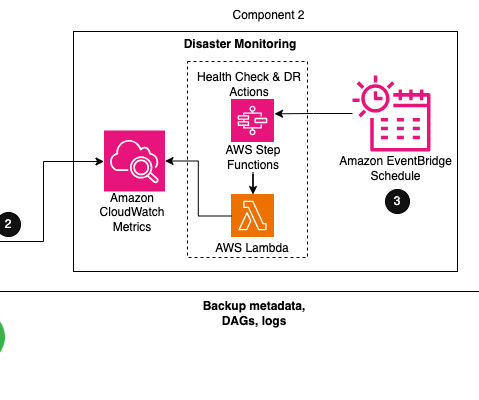
The need for Amazon MWAA disaster recovery Amazon MWAA, a fully managed service for Apache Airflow , brings immense value to organizations by automating workflow orchestration for extract, transform, and load (ETL), DevOps, and machinelearning (ML) workloads. This makes it difficult to implement a comprehensive DR strategy.
After some impressive advances over the past decade, largely thanks to the techniques of MachineLearning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. 1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments.
In the 2020 O’Reilly Data Quality survey only 20% of respondents say their organizations publish information about data provenance or data lineage internally. What’s more, SDX provides access to the lineage, metadata, and metrics associated with data utilization across environments. From Bad to Worse.
This article was originally published at Algorithimia’s website. The Amazon Product Reviews Dataset provides over 142 million Amazon product reviews with their associated metadata, allowing machinelearning practitioners to train sentiment models using product ratings as a proxy for the sentiment label. It provides 1.6
But now is the time to understand what “information” should be digitized and which digitized assets should be enriched and tagged with metadata so that they are searchable and can be connected to other relevant records. That means developers can use any technology stack and publish content consistently across various digital channels.
A data fabric utilizes continuous analytics over existing, discoverable and inferenced metadata to support the design, deployment and utilization of integrated and reusable datasets across all environments, including hybrid and multicloud platforms.” [1]. This improves data engineering productivity and time-to-value for data consumers.
In this post, we discuss how the Amazon Finance Automation team used AWS Lake Formation and the AWS Glue Data Catalog to build a data mesh architecture that simplified data governance at scale and provided seamless data access for analytics, AI, and machinelearning (ML) use cases.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content