This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Tour of Evaluation Metrics for MachineLearning After we train our. The post A Tour of Evaluation Metrics for MachineLearning appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
Introduction Few concepts in mathematics and information theory have profoundly impacted modern machinelearning and artificial intelligence, such as the Kullback-Leibler (KL) divergence.
Overview Evaluating a model is a core part of building an effective machinelearning model There are several evaluation metrics, like confusion matrix, cross-validation, The post 11 Important Model Evaluation Metrics for MachineLearning Everyone should know appeared first on Analytics Vidhya.
Introduction Machinelearning is about building a predictive model using historical data. The post Quick Guide to Evaluation Metrics for Supervised and Unsupervised MachineLearning appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
As the data community begins to deploy more machinelearning (ML) models, I wanted to review some important considerations. We recently conducted a survey which garnered more than 11,000 respondents—our main goal was to ascertain how enterprises were using machinelearning. Let’s begin by looking at the state of adoption.
For all the excitement about machinelearning (ML), there are serious impediments to its widespread adoption. There are several known attacks against machinelearning models that can lead to altered, harmful model outcomes or to exposure of sensitive training data. [8] 2] The Security of MachineLearning. [3]
The post HOW TO CHOOSE EVALUATION METRICS FOR CLASSIFICATION MODEL appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. INTRODUCTION Yay!! So you have successfully built your classification model. What should.
Unlike traditional AUC scores, partial AUC scores concentrate on a specific region of the ROC (Receiver Operating Characteristic) curve, offering a more detailed evaluation of the model’s […] The post Partial AUC Scores: A Better Metric for Binary Classification appeared first on Analytics Vidhya.
Introduction Click-through Rate (CTR) is a crucial metric that shows the percentage of visitors who click on an ad, providing insights into ad effectiveness. Businesses might considerably benefit from studying the click-through rate when developing their advertising tactics.
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machinelearning (ML). AI products are automated systems that collect and learn from data to make user-facing decisions. We won’t go into the mathematics or engineering of modern machinelearning here.
While RAG leverages nearest neighbor metrics based on the relative similarity of texts, graphs allow for better recall of less intuitive connections. As a result, GraphRAG mixes two bodies of “AI” research: the more symbolic reasoning which knowledge graphs represent and the more statistical approaches of machinelearning.
Data is typically organized into project-specific schemas optimized for business intelligence (BI) applications, advanced analytics, and machinelearning. Similarly, downstream business metrics in the Gold layer may appear skewed due to missing segments, which can impact high-stakes decisions.
The first step in building an AI solution is identifying the problem you want to solve, which includes defining the metrics that will demonstrate whether you’ve succeeded. It sounds simplistic to state that AI product managers should develop and ship products that improve metrics the business cares about. Agreeing on metrics.
2) “Deep Learning” by Ian Goodfellow, Yoshua Bengio and Aaron Courville. Best for: This best data science book is especially effective for those looking to enter the data-driven machinelearning and deep learning avenues of the field. 4) “MachineLearning Yearning” by Andrew Ng.
Data analysis method focuses on strategic approaches to taking raw data, mining for insights that are relevant to the business’s primary goals, and drilling down into this information to transform metrics, facts, and figures into initiatives that benefit improvement. Conduct statistical analysis. Build a data management roadmap.
Extract, transform, and load (ETL) is the process of combining, cleaning, and normalizing data from different sources to prepare it for analytics, artificial intelligence (AI), and machinelearning (ML) workloads. Amazon CloudWatch , a monitoring and observability service, collects logs and metrics from the data integration process.
A data scientist must be skilled in many arts: math and statistics, computer science, and domain knowledge. Statistics and programming go hand in hand. Mastering statistical techniques and knowing how to implement them via a programming language are essential building blocks for advanced analytics. Linear regression.
On the one hand, basic statistical models (e.g. On the other hand, sophisticated machinelearning models are flexible in their form but not easy to control. Introduction Machinelearning models often behave unpredictably, as data scientists would be the first to tell you.
This was not a scientific or statistically robust survey, so the results are not necessarily reliable, but they are interesting and provocative. One could say that sentinel analytics is more like unsupervised machinelearning, while precursor analytics is more like supervised machinelearning.
While some experts try to underline that BA focuses, also, on predictive modeling and advanced statistics to evaluate what will happen in the future, BI is more focused on the present moment of data, making the decision based on current insights. But let’s see in more detail what experts say and how can we connect and differentiate the both.
Machinelearning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. What is machinelearning?
Business analytics is the practical application of statistical analysis and technologies on business data to identify and anticipate trends and predict business outcomes. Business analytics also involves data mining, statistical analysis, predictive modeling, and the like, but is focused on driving better business decisions.
Savvy data scientists are already applying artificial intelligence and machinelearning to accelerate the scope and scale of data-driven decisions in strategic organizations. Bureau of Labor Statistics predicts that the employment of data scientists will grow 36 percent by 2031, 1 much faster than the average for all occupations.
In this paper, I show you how marketers can improve their customer retention efforts by 1) integrating disparate data silos and 2) employing machinelearning predictive analytics. underspecified) due to omitted metrics. MachineLearning and Predictive Modeling of Customer Churn. Danger, Red, Yellow or Green).
In addition, they can use statistical methods, algorithms and machinelearning to more easily establish correlations and patterns, and thus make predictions about future developments and scenarios. It ensures that all relevant data and information is consolidated, evaluated and presented in a clear and concise form.
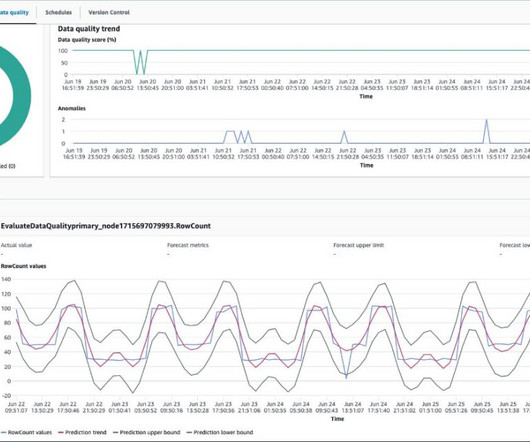
Run the job for 6 days and explore how AWS Glue Data Quality learns from data statistics and detects anomalies. For Statistics , enter RowCount. For Statistics , enter DistinctValuesCount and for Columns , enter pulocationid. Rules and analyzers gather data statistics or data profiles. Add a second analyzer.
According to the US Bureau of Labor Statistics, demand for qualified business intelligence analysts and managers is expected to soar to 14% by 2026, with the overall need for data professionals to climb to 28% by the same year. The Bureau of Labor Statistics also states that in 2015, the annual median salary for BI analysts was $81,320.
The data collection process is an ongoing process that starts with setting goals, defining success metrics , identifying what data needs to be collected, and how it will be gathered. The process is ongoing and starts with setting goals and defining success metrics before considering what data needs to be collected and how it will be gathered.
This enables more informed decision-making and innovative insights through various analytics and machinelearning applications. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer. It is essential for optimizing read and write performance.
While data science and machinelearning are related, they are very different fields. In a nutshell, data science brings structure to big data while machinelearning focuses on learning from the data itself. What is machinelearning? This post will dive deeper into the nuances of each field.
Get Rid of Blind Spots in Statistical Models With MachineLearning. Data-related blind spots could also exist in your statistical models. RiskSpan is a company that built a machinelearning algorithm that can flag error-prone parts of a statistical model and indicate which associated outputs may be unreliable.
Anomaly detection simply means defining “normal” patterns and metrics—based on business functions and goals—and identifying data points that fall outside of an operation’s normal behavior. A machinelearning model trained with labeled data will be able to detect outliers based on the examples it is given.
The Evolution of Data Collection in Football Traditionally, football relied on basic statistics such as goals, assists, and possession percentages to evaluate performance. Today, teams utilize sophisticated tracking systems, video analysis tools, and wearable devices to gather a wide range of performance metrics.
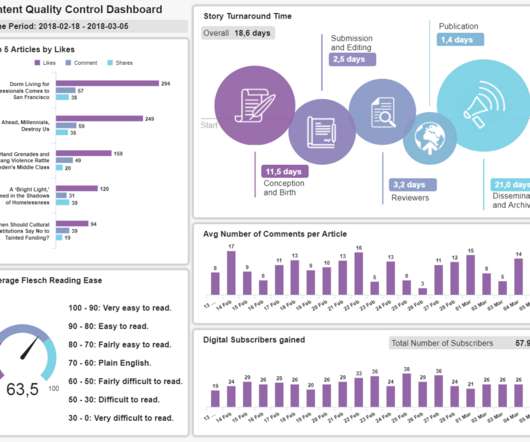
A content dashboard is an analytical tool that contains critical performance metrics to assess the success of all content-related initiatives. This most insightful of Google Analytics dashboards provide the perfect mix between overview metrics and more detailed insights. Let’s look at some of these metrics in more detail below.
Pete Skomoroch ’s “ Product Management for AI ”session at Rev provided a “crash course” on what product managers and leaders need to know about shipping machinelearning (ML) projects and how to navigate key challenges. Be aware that machinelearning often involves working on something that isn’t guaranteed to work.
Here are some statistics on the importance of AI in marketing : 48% of marketers feel AI makes a greater difference than anything else in affecting their relationship with customers 51% of e-commerce companies use AI to improve the customer experience 64% of B2B marketers use AI to guide their strategy. You can use AI to generate new content.
Fortunately, we live in a digital age rife with statistics, data, and insights that give us the power to spot potential issues and inefficiencies within the business. With so many areas to consider, deciding which KPIs to focus on while defining metric measurement periods can prove to be a challenge at the initial stages.
Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature. Among these, only statistical uncertainty has formal recognition.
After developing a machinelearning model, you need a place to run your model and serve predictions. Someone with the knowledge of SQL and access to a Db2 instance, where the in-database ML feature is enabled, can easily learn to build and use a machinelearning model in the database. NOT IN(SELECT FT.ID
In conferences and research publications, there is a lot of excitement these days about machinelearning methods and forecast automation that can scale across many time series. Nor can we learn prediction intervals across a large set of parallel time series, since we are trying to generate intervals for a single global time series.
Data scientists are becoming increasingly important in business, as organizations rely more heavily on data analytics to drive decision-making and lean on automation and machinelearning as core components of their IT strategies. Data scientist job description.
With the emergence of new advances and applications in machinelearning models and artificial intelligence, including generative AI, generative adversarial networks, computer vision and transformers, many businesses are seeking to address their most pressing real-world data challenges using both types of synthetic data: structured and unstructured.
Some will argue that observability is nothing more than testing and monitoring applications using tests, metrics, logs, and other artifacts. Best practices include continuous monitoring of machinelearning models for degradations in accuracy. . Statistical Process Control. Tie tests to alerts. Focus on the process.
Classical machinelearning: Patterns, predictions, and decisions Classical machinelearning is the proven backbone of pattern recognition, business intelligence, and rules-based decision-making; it produces explainable results. Model sizes: Uses algorithmic and statistical methods rather than neural network models.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content