This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Statisticalmodels are significant for understanding and predicting complex data. A viable area for statisticalmodeling is time-series analysis. Statisticalmodels […] The post Learning Time Series Analysis & Modern StatisticalModels appeared first on Analytics Vidhya.
The post How MachineLearningModels Fail to Deliver in Real-World Scenarios appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Introduction Yesterday, my brother broke an antique at home. I began to.
A key idea in data science and statistics is the Bernoulli distribution, named for the Swiss mathematician Jacob Bernoulli. It is crucial to probability theory and a foundational element for more intricate statisticalmodels, ranging from machinelearning algorithms to customer behaviour prediction.
Overview Evaluating a model is a core part of building an effective machinelearningmodel There are several evaluation metrics, like confusion matrix, cross-validation, The post 11 Important Model Evaluation Metrics for MachineLearning Everyone should know appeared first on Analytics Vidhya.
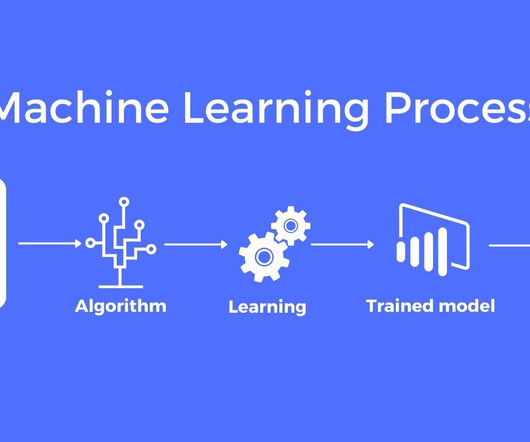
Introduction Let’s have a simple overview of what MachineLearning is. MachineLearning is the method of teaching computer programs to do a specific task accurately (essentially a prediction) by training a predictive model using various statistical algorithms leveraging data.
For all the excitement about machinelearning (ML), there are serious impediments to its widespread adoption. Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML.
Considerations for a world where ML models are becoming mission critical. As the data community begins to deploy more machinelearning (ML) models, I wanted to review some important considerations. Interest on the part of companies means the demand side for “machinelearning talent” is healthy.
They recently wrote a survey paper, “A Critical Review of Fair MachineLearning,” where they carefully examined the standard statistical tools used to check for fairness in machinelearningmodels. Continue reading Why it’s hard to design fair machinelearningmodels.
As indicated in machinelearning and statisticalmodeling, the assessment of models impacts results significantly. Accuracy falls short of capturing these trade-offs as a means to work with imbalanced datasets, especially in terms of precision and recall ratios.
The normal distribution, also known as the Gaussian distribution, is one of the most widely used probability distributions in statistics and machinelearning. Understanding its core properties, mean and variance, is important for interpreting data and modelling real-world phenomena.
Introduction Few concepts in mathematics and information theory have profoundly impacted modern machinelearning and artificial intelligence, such as the Kullback-Leibler (KL) divergence.
Introduction One of the key challenges in MachineLearningModel is the explainability of the ML Model that we are building. In general, ML Model is a Black Box. As Data scientists, we may understand the algorithm & statistical methods used behind the scene. […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Whenever we build any machinelearningmodel, we feed it. The post 4 Ways to Evaluate your MachineLearningModel: Cross-Validation Techniques (with Python code) appeared first on Analytics Vidhya.
Introduction Machinelearning is about building a predictive model using historical data. The post Quick Guide to Evaluation Metrics for Supervised and Unsupervised MachineLearning appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
Introduction “Data Science” and “MachineLearning” are prominent technological topics in the 25th century. They are utilized by various entities, ranging from novice computer science students to major organizations like Netflix and Amazon. appeared first on Analytics Vidhya.
At times it may seem MachineLearning can be done these days without a sound statistical background but those people are not really understanding the different nuances. Code written to make it easier does not negate the need for an in-depth understanding of the problem.
As companies use machinelearning (ML) and AI technologies across a broader suite of products and services, it’s clear that new tools, best practices, and new organizational structures will be needed. What cultural and organizational changes will be needed to accommodate the rise of machine and learning and AI?
Introduction to Imbalanced Datasets The accuracy achieved by many of the machinelearningmodels using traditional statistical algorithms increases by just around 2% or so when the size of the training dataset is increased from 20% to 80%. This article was published as a part of the Data Science Blogathon.
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machinelearningmodels from malicious actors. Like many others, I’ve known for some time that machinelearningmodels themselves could pose security risks.
With franchise leagues like IPL and BBL, teams rely on statisticalmodels and tools for competitive edge. The analysis benefits fantasy […] The post The Science of T20 Cricket: Decoding Player Performance with Predictive Modeling appeared first on Analytics Vidhya.
Time series analysis is a statistical technique used to analyze data […] The post How to Build Your Time Series Model? Before we take up a time series problem, we must familiarise ourselves with the concept of forecasting. So now the question is, what is a time series? appeared first on Analytics Vidhya.
So, it is essential to incorporate external data in forecasting, planning and budgeting, especially for predictive analytics and machinelearning to support artificial intelligence. This provides useful information about what to do next time to achieve a better outcome and how to refine the model to improve its accuracy.
Data science for marketing is a discipline that combines statistical analysis, machinelearning, and predictive modeling to extract meaningful patterns […] The post How to Use Data Science for Marketing? appeared first on Analytics Vidhya.
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., at Facebook—both from 2020.
Table of contents Introduction Multilevel Models Advantages of Multilevel models When do we use Multilevel Models Types of Multilevel Model Random intercept model Random coefficient model Hypothesis testing: Likelihood Ratio Testing End-Note Introduction Suppose, you have a dataset of faculty salaries of a university […].
Introduction to Random Forest Missing values have always been a concern for any statistical analysis. They significantly reduce the study’s statistical powers, which may lead to faulty conclusions. Most of the algorithms used in statisticalmodellings such as Linear regression, Logistic Regression, […].
Credit evaluations have progressed from being subjective decisions by the bank’s credit experts to a more statistically advanced evaluation. The post Gaussian Naive Bayes Algorithm for Credit Risk Modelling appeared first on Analytics Vidhya. Banks rapidly recognize the increased need for comprehensive credit risk […].
This post will examine how statisticalmachine-learning […] The post End-to-End Case Study: Bike Sharing Demand Prediction appeared first on Analytics Vidhya. The purpose of this analysis is to understand the patterns and trends in bike usage and make predictions about future demand.
Introduction In order to build machinelearningmodels that are highly generalizable to a wide range of test conditions, training models with high-quality data is essential. Unfortunately, a large part of the data collected is not readily ideal for training machinelearningmodels, this increases […].
Introduction Conventionally, an automatic speech recognition (ASR) system leverages a single statistical language model to rectify ambiguities, regardless of context. This article was published as a part of the Data Science Blogathon. However, we can improve the system’s accuracy by leveraging contextual information.
If you’re already a software product manager (PM), you have a head start on becoming a PM for artificial intelligence (AI) or machinelearning (ML). AI products are automated systems that collect and learn from data to make user-facing decisions. We won’t go into the mathematics or engineering of modern machinelearning here.
Introduction Imagine you’re working on a dataset to build a MachineLearningmodel and don’t want to spend too much effort on exploratory data analysis codes. You may sometimes find it confusing to sort, filter, or group data to obtain the required information.
So you have successfully built your classification model. The post HOW TO CHOOSE EVALUATION METRICS FOR CLASSIFICATION MODEL appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. INTRODUCTION Yay!! What should.
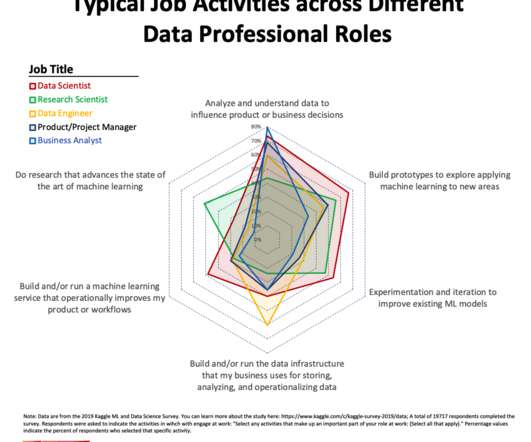
Only 1/4 of respondents said they do research to advance the state of the art of machinelearning. We know that data professionals, when working on data science and machinelearning projects, spend their time on a variety of different activities (e.g., Experimentation and iteration to improve existing ML models (39%).
Machinelearning solutions for data integration, cleaning, and data generation are beginning to emerge. “AI As model building become easier, the problem of high-quality data becomes more evident than ever. In this post, we shed some light on various efforts toward generating data for machinelearning (ML) models.
Machines, artificial intelligence (AI), and unsupervised learning are reshaping the way businesses vie for a place under the sun. With that being said, let’s have a closer look at how unsupervised machinelearning is omnipresent in all industries. What Is Unsupervised MachineLearning? Source ].
Introduction A popular and widely used statistical method for time series forecasting. The post How to Create an ARIMA Model for Time Series Forecasting in Python appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
Introduction Cross-validation is a machinelearning technique that evaluates a model’s performance on a new dataset. This prevents overfitting by encouraging the model to learn underlying trends associated with the data.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Logistic Regression is another statisticalmodel which is used for. The post Geometrical Approach To Understand Logistic Regression appeared first on Analytics Vidhya.
The post Decluttering the performance measures of classification models appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Introduction There are so many performance evaluation measures when it comes to.
Introduction Machinelearningmodels are garbage in garbage-out boxes, and it is essential to address any missing data before feeding it to your model. This article was published as a part of the Data Science Blogathon. Missing data in your dataset could be due to multiple reasons like 1) The data was not available.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In Machinelearning or Deep Learning, some of the models. The post How to transform features into Normal/Gaussian Distribution appeared first on Analytics Vidhya.
Learn how genetic algorithms and machinelearning can help hedge fund organizations manage a business. This article looks at how genetic algorithms (GA) and machinelearning (ML) can help hedge fund organizations. Modern machinelearning and back-testing; how quant hedge funds use it. Pre-train tests.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content