This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction This article aims to compare four different deep learning and. The post Email Spam Detection – A Comparative Analysis of 4 MachineLearningModels appeared first on Analytics Vidhya.
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. at Facebook—both from 2020.
Introduction Let’s have a simple overview of what MachineLearning is. MachineLearning is the method of teaching computer programs to do a specific task accurately (essentially a prediction) by training a predictive model using various statistical algorithms leveraging data.
Large language models (LLMs) just keep getting better. In just about two years since OpenAI jolted the news cycle with the introduction of ChatGPT, weve already seen the launch and subsequent upgrades of dozens of competing models. From Llama3.1 to Gemini to Claude3.5 From Llama3.1 to Gemini to Claude3.5
This article was published as a part of the Data Science Blogathon “You can have data without information but you cannot have information without data” – Daniel Keys Moran Introduction If you are here then you might be already interested in MachineLearning or Deep Learning so I need not explain what it is?
This article was published as a part of the Data Science Blogathon Introduction Let’s look at a practical application of the supervised NLP fastText model for detecting sarcasm in news headlines. About 80% of all information is unstructured, and text is one of the most common types of unstructureddata.
Overview This article dives into the key question – is class sensitivity in a classification problem model-dependent? The authors analyze four popular deep learning. The post Is Class Sensitivity Model Dependent? Analyzing 4 Popular Deep Learning Architectures appeared first on Analytics Vidhya.
This article reflects some of what Ive learned. The hype around large language models (LLMs) is undeniable. They promise to revolutionize how we interact with data, generating human-quality text, understanding natural language and transforming data in ways we never thought possible. Theyre impressive, no doubt.
Whether it’s a financial services firm looking to build a personalized virtual assistant or an insurance company in need of ML models capable of identifying potential fraud, artificial intelligence (AI) is primed to transform nearly every industry. And the results for those who embrace a modern data architecture speak for themselves.
With organizations seeking to become more data-driven with business decisions, IT leaders must devise data strategies gear toward creating value from data no matter where — or in what form — it resides. Unstructureddata resources can be extremely valuable for gaining business insights and solving problems.
Unstructureddata is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. You can integrate different technologies or tools to build a solution.
Now that AI can unravel the secrets inside a charred, brittle, ancient scroll buried under lava over 2,000 years ago, imagine what it can reveal in your unstructureddata–and how that can reshape your work, thoughts, and actions. Unstructureddata has been integral to human society for over 50,000 years.
Introduction Overfitting or high variance in machinelearningmodels occurs when the accuracy of your training dataset, the dataset used to “teach” the model, The post How to Treat Overfitting in Convolutional Neural Networks appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. The post Topic Modelling in Natural Language Processing appeared first on Analytics Vidhya. Introduction Natural language processing is the processing of languages used.
We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machinelearning, AI, data governance, and data security operations. . Dagster / ElementL — A data orchestrator for machinelearning, analytics, and ETL. .
When I think about unstructureddata, I see my colleague Rob Gerbrandt (an information governance genius) walking into a customer’s conference room where tubes of core samples line three walls. While most of us would see dirt and rock, Rob sees unstructureddata. have encouraged the creation of unstructureddata.
This article was published as a part of the Data Science Blogathon. The post Boost Model Accuracy of Imbalanced COVID-19 Mortality Prediction Using GAN-based Oversampling Technique appeared first on Analytics Vidhya. Introduction The article covers the use of Generative Adversarial Networks (GAN), an.
Here we mostly focus on structured vs unstructureddata. In terms of representation, data can be broadly classified into two types: structured and unstructured. Structured data can be defined as data that can be stored in relational databases, and unstructureddata as everything else.
But the grouping and summarizing just wasn’t exciting enough for the data addicts. They’d grown tired of learning what is; now they wanted to know what’s next. Stage 2: Machinelearningmodels Hadoop could kind of do ML, thanks to third-party tools. Those algorithms packaged with scikit-learn?
According to PwC, organizations can experience incremental value at scale through AI, with 20% to 30% gains in productivity, speed to market, and revenue, on top of big leaps such as new business models. [2]
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Let’s say you have a client who has a publishing. The post Topic Modeling and Latent Dirichlet Allocation(LDA) using Gensim and Sklearn : Part 1 appeared first on Analytics Vidhya.
Two big things: They bring the messiness of the real world into your system through unstructureddata. People have been building data products and machinelearning products for the past couple of decades. They tried various prompts and models and, based on vibes, decided some were better than others.
For a model-driven enterprise, having access to the appropriate tools can mean the difference between operating at a loss with a string of late projects lingering ahead of you or exceeding productivity and profitability forecasts. What Are Modeling Tools? Importance of Modeling Tools. Types of Modeling Tools.
One example of Pure Storage’s advantage in meeting AI’s data infrastructure requirements is demonstrated in their DirectFlash® Modules (DFMs), with an estimated lifespan of 10 years and with super-fast flash storage capacity of 75 terabytes (TB) now, to be followed up with a roadmap that is planning for capacities of 150TB, 300TB, and beyond.
When building a machine-learning-powered tool to predict the maintenance needs of its customers, Ensono found that its customers used multiple old apps to collect incident tickets, but those apps stored incident data in very different formats, with inconsistent types of data collected, he says. But they can be modernized.
In this interview from O’Reilly Foo Camp 2019, Hands-On Unsupervised Learning Using Python author Ankur Patel discusses the challenges and opportunities in making machinelearning and AI accessible and financially viable for enterprise applications. Then you have pre-trained models you can do transfer learning with.
Just 20% of organizations publish data provenance and data lineage. Adopting AI can help data quality. Almost half (48%) of respondents say they use data analysis, machinelearning, or AI tools to address data quality issues. Can AI be a catalyst for improved data quality?
They are using tools like Amazon SageMaker to take advantage of more powerful machinelearning capabilities. Amazon SageMaker is a hardware accelerator platform that uses cloud-based machinelearning technology. IBM Watson Studio is a very popular solution for handling machinelearning and data science tasks.
AI and machinelearning. Before you can have AI-driven apps, you need to train a machinelearningmodel to do the work. This means feeding the machine with vast amounts of data, from structured to unstructureddata, which will help the device learn how to think, process information, and act like humans.
Data scientists are analytical data experts who use data science to discover insights from massive amounts of structured and unstructureddata to help shape or meet specific business needs and goals. Data scientist job description. Semi-structured data falls between the two.
Geet our bite-sized free summary and start building your data skills! What Is A Data Science Tool? In the past, data scientists had to rely on powerful computers to manage large volumes of data. It offers many statistics and machinelearning functionalities such as predictive models for future forecasting.
Different types of information are more suited to being stored in a structured or unstructured format. Read on to explore more about structured vs unstructureddata, why the difference between structured and unstructureddata matters, and how cloud data warehouses deal with them both. Unstructureddata.
AI and related technologies, such as machinelearning (ML), enable content management systems to take away much of that classification work from users. Importantly, such tools can extract relevant data even from unstructureddata – including PDFs, email, and even images – and accurately classify it, making it easy to find and use. “AI
This year’s technology darling and other machinelearning investments have already impacted digital transformation strategies in 2023 , and boards will expect CIOs to update their AI transformation strategies frequently. Luckily, many are expanding budgets to do so. “94%
As enterprises navigate complex data-driven transformations, hybrid and multi-cloud models offer unmatched flexibility and resilience. Heres a deep dive into why and how enterprises master multi-cloud deployments to enhance their data and AI initiatives. The terms hybrid and multi-cloud are often used interchangeably.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machinelearning and generative AI. They’re trying to get a handle on their data estate right now.
Often the data resides in different databases, in diverse data centers, or in different clouds. Migrating the data into similar databases, and replicating data across multiple locations, provides the availability and speed required for AI applications. As much as 90% of an organization’s data is unstructured.
For most organizations, the effective use of AI is essential for future viability and, in turn, requires large amounts of accurate and accessible data. Across industries, 78 % of executives rank scaling AI and machinelearning (ML) use cases to create business value as their top priority over the next three years.
Generative AI and large language models (LLMs) like ChatGPT are only one aspect of AI. Model sizes: ~5 billion to >1 trillion parameters. Model sizes: ~Millions to billions of parameters. Great for: Extracting meaning from unstructureddata like network traffic, video & speech.
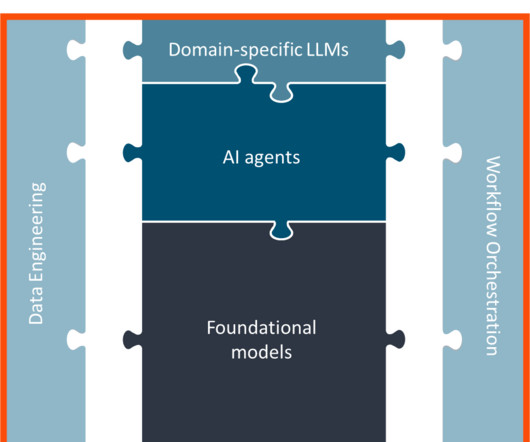
Today we are announcing our latest addition: a new family of IBM-built foundation models which will be available in watsonx.ai , our studio for generative AI, foundation models and machinelearning. Collectively named “Granite,” these multi-size foundation models apply generative AI to both language and code.
Anomalies are not inherently bad, but being aware of them, and having data to put them in context, is integral to understanding and protecting your business. The challenge for IT departments working in data science is making sense of expanding and ever-changing data points.
Usually, business or data analysts need to extract insights for reporting purposes, so data warehouses are more suitable for them. On the other hand, a data scientist may require access to unstructureddata to detect patterns or build a deep learningmodel, which means that a data lake is a perfect fit for them.
More than two-thirds of companies are currently using Generative AI (GenAI) models, such as large language models (LLMs), which can understand and generate human-like text, images, video, music, and even code. However, the true power of these models lies in their ability to adapt to an enterprise’s unique context.
How natural language processing works NLP leverages machinelearning (ML) algorithms trained on unstructureddata, typically text, to analyze how elements of human language are structured together to impart meaning. Transformer models take applications such as language translation and chatbots to a new level.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content