This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction This article aims to compare four different deep learning and. The post Email Spam Detection – A Comparative Analysis of 4 MachineLearning Models appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. The post Google Earth Engine MachineLearning for Land Cover Classification (with Code) appeared first on Analytics Vidhya. Introducing Earth Engine and Remote Sensing Earth Engine, also referred.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Sounds can become wrangled within the data science field through. The post Visualizing Sounds Using Librosa MachineLearning Library! appeared first on Analytics Vidhya.
In this article, we are going to prepare our personal image dataset using OpenCV for any kind of machinelearning. The post Create Your own Image Dataset using Opencv in MachineLearning appeared first on Analytics Vidhya. ArticleVideo Book Hello Geeks!
Introduction Let’s have a simple overview of what MachineLearning is. MachineLearning is the method of teaching computer programs to do a specific task accurately (essentially a prediction) by training a predictive model using various statistical algorithms leveraging data. Source: [link] For […].
Then connect the graph nodes and relations extracted from unstructureddata sources, reusing the results of entity resolution to disambiguate terms within the domain context. Chunk your documents from unstructureddata sources, as usual in GraphRAG. Let’s revisit the point about RAG borrowing from recommender systems.
Introduction In the modern world, data science(DS) has emerged as one of the most sought-after careers. Fundamentally, it is the art of transforming unstructureddata into a usable format and then drawing actionable insights from it.
Unstructureddata represents one of today’s most significant business challenges. Unlike defined data – the sort of information you’d find in spreadsheets or clearly broken down survey responses – unstructureddata may be textual, video, or audio, and its production is on the rise. Centralizing Information.
With organizations seeking to become more data-driven with business decisions, IT leaders must devise data strategies gear toward creating value from data no matter where — or in what form — it resides. Unstructureddata resources can be extremely valuable for gaining business insights and solving problems.
This article was published as a part of the Data Science Blogathon Introduction Let’s look at a practical application of the supervised NLP fastText model for detecting sarcasm in news headlines. About 80% of all information is unstructured, and text is one of the most common types of unstructureddata.
Unstructureddata is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructureddata.
Machinelearning (ML) is a form of AI that is becoming more widely used in the market because of the rising number of AI vendors in the banking industry. Why MachineLearning? What MachineLearning Means to Asset Managers. Data Analysis. But is AI becoming the end-all and be-all of asset management ?
This article was published as a part of the Data Science Blogathon. Introduction A data lake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructureddata. It can store data in its native format and process any type of data, regardless of size.
They promise to revolutionize how we interact with data, generating human-quality text, understanding natural language and transforming data in ways we never thought possible. From automating tedious tasks to unlocking insights from unstructureddata, the potential seems limitless. You get the picture.
Now that AI can unravel the secrets inside a charred, brittle, ancient scroll buried under lava over 2,000 years ago, imagine what it can reveal in your unstructureddata–and how that can reshape your work, thoughts, and actions. Unstructureddata has been integral to human society for over 50,000 years.
Introduction In the era of big data, organizations are inundated with vast amounts of unstructured textual data. The sheer volume and diversity of information present a significant challenge in extracting insights.
This article was published as a part of the Data Science Blogathon Introduction Analyzing texts is far more complicated than analyzing typical tabulated data (e.g. retail data) because texts fall under unstructureddata. Different people express themselves quite differently when it comes to […].
Introduction Textual data from social media posts, customer feedback, and reviews are valuable resources for any business. There is a host of useful information in such unstructureddata that we can discover. Making sense of this unstructureddata can help companies better understand […].
Then there’s the data lakehouse—an analytics system that allows data to be processed, analyzed, and stored in both structured and unstructured forms. A data mesh delivers greater ownership and governance to the IT team members who work closest to the data in question.
When I think about unstructureddata, I see my colleague Rob Gerbrandt (an information governance genius) walking into a customer’s conference room where tubes of core samples line three walls. While most of us would see dirt and rock, Rob sees unstructureddata. have encouraged the creation of unstructureddata.
Introduction Text Mining is also known as Text Data Mining or Text Analytics or is an artificial intelligence (AI) technology that uses natural language processing (NLP) to extract essential data from standard language text. It is a process to transform the unstructureddata (text […].
Here we mostly focus on structured vs unstructureddata. In terms of representation, data can be broadly classified into two types: structured and unstructured. Structured data can be defined as data that can be stored in relational databases, and unstructureddata as everything else.
I was recently asked to identify key modern data architecture trends. Data architectures have changed significantly to accommodate larger volumes of data as well as new types of data such as streaming and unstructureddata. Here are some of the trends I see continuing to impact data architectures.
Introduction In recent years, the evolution of technology has increased tremendously, and nowadays, deep learning is widely used in many domains. This has achieved great success in many fields, like computer vision tasks and natural language processing.
This article was published as a part of the Data Science Blogathon. Introduction A data lake is a central data repository that allows us to store all of our structured and unstructureddata on a large scale. The post A Detailed Introduction on Data Lakes and Delta Lakes appeared first on Analytics Vidhya.
By leveraging AI technologies such as generative AI, machinelearning (ML), natural language processing (NLP), and computer vision in combination with robotic process automation (RPA), process and task mining, low/no-code development, and process orchestration, organizations can create smarter and more efficient workflows.
Introduction Overfitting or high variance in machinelearning models occurs when the accuracy of your training dataset, the dataset used to “teach” the model, The post How to Treat Overfitting in Convolutional Neural Networks appeared first on Analytics Vidhya.
We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machinelearning, AI, data governance, and data security operations. . Dagster / ElementL — A data orchestrator for machinelearning, analytics, and ETL. .
Instead of overhauling entire systems, insurers can assess their API infrastructure to ensure efficient data flow, identify critical data types, and define clear schemas for structured and unstructureddata. Incorporating custom knowledge graphs, enriched with domain expertise, further optimizes data consolidation.
At its core, that process involves extracting key information about the individual customer, unstructureddata from medical records and financial data and then analyzing that data to make an underwriting decision.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction to NLP: After I got acquainted with Machinelearning concepts, The post A simple start with Natural Language Processing! appeared first on Analytics Vidhya.
Introduction Source Sentiment Analysis or opinion mining is the analysis of emotions behind the words by using Natural Language Processing and MachineLearning. The post Fine-Grained Sentiment Analysis of Smartphone Review appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon In any Machinelearning task, cleaning or preprocessing the data is. The post Must Known Techniques for text preprocessing in NLP appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction The realities of the modern world are such that the analyst increasingly has to resort to the help of the latest machinelearning algorithms to identify certain deviations in the operation of the system under study.
This article was published as a part of the Data Science Blogathon “You can have data without information but you cannot have information without data” – Daniel Keys Moran Introduction If you are here then you might be already interested in MachineLearning or Deep Learning so I need not explain what it is?
We live in a data-rich, insights-rich, and content-rich world. Data collections are the ones and zeroes that encode the actionable insights (patterns, trends, relationships) that we seek to extract from our data through machinelearning and data science. Source: [link] I will finish with three quotes.
Introduction Every once in a while, a machinelearning framework or library changes the landscape of the field. Today, Facebook open sourced one such. The post Facebook AI Launches DEtection TRansformer (DETR) – A Transformer based Object Detection Approach! appeared first on Analytics Vidhya.
But the grouping and summarizing just wasn’t exciting enough for the data addicts. They’d grown tired of learning what is; now they wanted to know what’s next. Stage 2: Machinelearning models Hadoop could kind of do ML, thanks to third-party tools. Those algorithms packaged with scikit-learn?
This article was published as a part of the Data Science Blogathon The intersection of medicine and data science has always been relevant; perhaps the most obvious example is the implementation of neural networks in deep learning. As data science and machinelearning advance, so will medicine, but the opposite is also true.
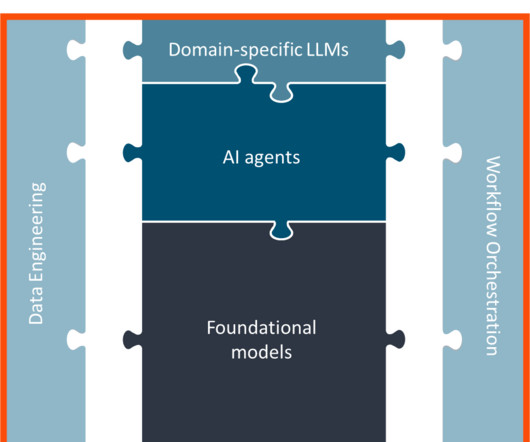
Before LLMs and diffusion models, organizations had to invest a significant amount of time, effort, and resources into developing custom machine-learning models to solve difficult problems. In many cases, this eliminates the need for specialized teams, extensive data labeling, and complex machine-learning pipelines.
Just 20% of organizations publish data provenance and data lineage. Adopting AI can help data quality. Almost half (48%) of respondents say they use data analysis, machinelearning, or AI tools to address data quality issues. Can AI be a catalyst for improved data quality?
When building a machine-learning-powered tool to predict the maintenance needs of its customers, Ensono found that its customers used multiple old apps to collect incident tickets, but those apps stored incident data in very different formats, with inconsistent types of data collected, he says. But they can be modernized.
One example of Pure Storage’s advantage in meeting AI’s data infrastructure requirements is demonstrated in their DirectFlash® Modules (DFMs), with an estimated lifespan of 10 years and with super-fast flash storage capacity of 75 terabytes (TB) now, to be followed up with a roadmap that is planning for capacities of 150TB, 300TB, and beyond.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content