This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snapshots are crucial for data backup and disaster recovery in Amazon OpenSearch Service. These snapshots allow you to generate backups of your domain indexes and cluster state at specific moments and save them in a reliable storage location such as Amazon Simple Storage Service (Amazon S3). Snapshots are not instantaneous.
Amazon OpenSearch Service is a fully managed service offered by AWS that enables you to deploy, operate, and scale OpenSearch domains effortlessly. This post focuses on introducing an active-passive approach using a snapshot and restore strategy. OpenSearch is a distributed search and analytics engine, which is an open-source project.
It is appealing to migrate from self-managed OpenSearch and Elasticsearch clusters in legacy versions to Amazon OpenSearch Service to enjoy the ease of use, native integration with AWS services, and rich features from the open-source environment ( OpenSearch is now part of Linux Foundation ).
Icebergs concurrency model and conflict type Before diving into specific implementation patterns, its essential to understand how Iceberg manages concurrent writes through its table architecture and transaction model. Metadata layer Contains metadata files that track table history, schema evolution, and snapshot information.
Some challenges include data infrastructure that allows scaling and optimizing for AI; data management to inform AI workflows where data lives and how it can be used; and associated data services that help data scientists protect AI workflows and keep their models clean. I’m excited to give you a preview of what’s around the corner for ONTAP.
in Amazon OpenSearch Service , we introduced SnapshotManagement , which automates the process of taking snapshots of your domain. SnapshotManagement helps you create point-in-time backups of your domain using OpenSearch Dashboards, including both data and configuration settings (for visualizations and dashboards).
In this post, we focus on data management implementation options such as accessing data directly in Amazon Simple Storage Service (Amazon S3), using popular data formats like Parquet, or using open table formats like Iceberg. Data management is the foundation of quantitative research.
Management reporting is a source of business intelligence that helps business leaders make more accurate, data-driven decisions. In this blog post, we’re going to give a bit of background and context about management reports, and then we’re going to outline 10 essential best practices you can use to make sure your reports are effective.
Open table formats are emerging in the rapidly evolving domain of big data management, fundamentally altering the landscape of data storage and analysis. The adoption of open table formats is a crucial consideration for organizations looking to optimize their data management practices and extract maximum value from their data.
The architecture uses AWS serverless computing and managed services, including Step Functions, Lambda, and EventBridge, providing a highly flexible and scalable design. By using Amazon Neptune, this solution provides comprehensive end-to-end lineage analysis.
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. We recommend you use Secrets Manager for storing Amazon Redshift user credentials because it allows you to configure safer secret rotation, customize fine-grained access control, and audit and monitor secrets centrally.
For existing users of Amazon Managed Service for Apache Flink who are excited about the recent announcement of support for Apache Flink runtime version 1.18, you can now statefully migrate your existing applications that use older versions of Apache Flink to a more recent version, including Apache Flink version 1.18.
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Iceberg creates a new version called a snapshot for every change to the data in the table. Iceberg creates a new version called a snapshot for every change to the data in the table.
When running Apache Flink applications on Amazon Managed Service for Apache Flink , you have the unique benefit of taking advantage of its serverless nature. With Managed Service for Apache Flink, you can add and remove compute with the click of a button. The third cost component is durable application backups, or snapshots.
One of the problems companies face is trying to setup a database that will be able to handle the large quantity of data that they need to manage. There are a number of solutions that can help companies manage their databases. They don’t even necessarily need to understand NoSQL to manage their databases.
To ensure that your customer-facing communications and efforts are constantly improving and evolving, investing in customer relationship management (CRM) is vital. A CRM report, or CRM reporting, is the presentational aspect of customer relationship management. Work through your narrative.
Unaligned checkpoints help, under specific conditions, to reduce checkpointing time for applications suffering temporary backpressure, and can be now enabled in Amazon Managed Service for Apache Flink applications running Apache Flink 1.15.2 When barriers from all upstream partitions have arrived, the sub-task takes a snapshot of its state.
It delivers cyber and disaster recovery for VMware Cloud Foundation infrastructure under a unified management experience. VMware Live Recovery support for Google Cloud empowers customers with more choices for their cyber and disaster recovery strategies, said Manoj Sharma, Director of Product Management, Google Cloud.
To mitigate this, Amazon Managed Service for Apache Flink has built a new layer of resilience by allowing customers to opt for the system-rollback feature that will seamlessly revert the application to a previous running version, thereby improving application stability and high availability.
Our Benchmark Snapshot summarizes how recent events have affected customer experience in the recent months. Most teams responding to customers are now in a work from home environment, putting additional strain on their ability to respond to customers effectively. For many of us, that means learning and adjusting as we go.
Amazon Managed Service for Apache Flink , formerly known as Amazon Kinesis Data Analytics, is the AWS service offering fully managed Apache Flink. Buffer debloating and unaligned checkpoints can be enabled on Amazon Managed Service for Apache Flink version 1.15. The application is coordinated by a job manager.
Monitoring and tracking issues in the data management lifecycle are essential for achieving operational excellence in data lakes. This is where Apache Iceberg comes into play, offering a new approach to data lake management. It enables users to track changes over time and manage version history effectively.
Even though it’s generally understood that experience management programs help businesses to be more efficient, profitable, and higher performing, customer experience (CX) professionals are consistently challenged to prove the economic impact of their programs. Download here.
In this article we discuss the various methods to replicate HBase data and explore why Replication Manager is the best choice for the job with the help of a use case. Cloudera Replication Manager is a key Cloudera Data Platform (CDP) service, designed to copy and migrate data between environments and infrastructures across hybrid clouds.
Customer relationship management (CRM) platforms are very reliant on big data. Complex Salesforce orgs can work just fine if they are properly managed. Metazoa is the company behind the Salesforce ecosystem’s top software toolset for org management, Metazoa Snapshot. Tools like Metazoa Snapshot make it painless, however.
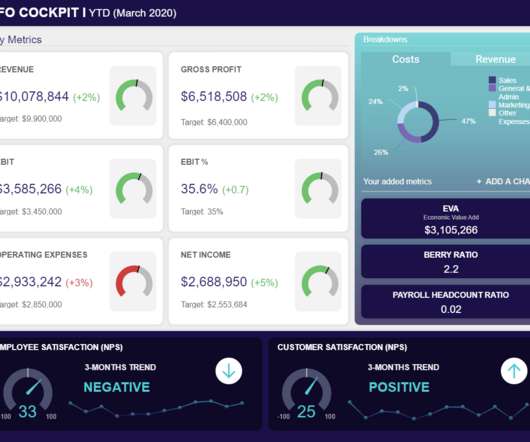
This powerful CFO dashboard example allows you to connect another dashboard within its framework with ease while integrating additional insights, including market indicators, consumer analysis, investor relations, monetary management, and more.
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage your data warehouse infrastructure. You can define your own key and value for your resource tag, so that you can easily manage and filter your resources. Tags allows you to assign metadata to your AWS resources. Create cost reports.
By managing customer data the right way, you stand to reap incredible rewards. This consumer-centric information, if well-managed, can form the building block of a business’s long-term success. Customer data management is the key to sustainable commercial success. What Is Customer Data Management (CDM)?
History management in data systems is fundamental for compliance, business intelligence, data quality, and time-based analysis. When combined with Change Data Capture (CDC), which identifies and captures database changes, history management becomes even more potent. Lets explore this concept with a practical example.
Amazon Managed Service for Apache Flink , which offers a fully managed, serverless experience in running Apache Flink applications, now supports Apache Flink 1.18.1 , the latest version of Apache Flink at the time of writing. and supported in Amazon Managed Service for Apache Flink. The dependency for Apache Flink 1.18
Apache Iceberg manages these schema changes in a backward-compatible way through its innovative metadata table evolution architecture. Due to the security requirements of different organizations, they need to manage fine-grained access control for the analysts through Lake Formation. Iceberg creates snapshots for the table contents.
Best practice blends the application of advanced data models with the experience, intuition and knowledge of sales management, to deeply understand the sales pipeline. This process helps sales managersmanage and invest in their team and anticipate opportunities that lead to exceeding revenue goals. Sales data can get messy.
Amazon Managed Service for Apache Flink offers a fully managed, serverless experience in running Apache Flink applications and now supports Apache Flink 1.19.1 , the latest stable version of Apache Flink at the time of writing. Managed Service for Apache Flink currently uses the Python 3.11 support Python 3.11 Python 3.11
Organizations with legacy, on-premises, near-real-time analytics solutions typically rely on self-managed relational databases as their data store for analytics workloads. We introduce you to Amazon Managed Service for Apache Flink Studio and get started querying streaming data interactively using Amazon Kinesis Data Streams.
Since software engineers manage to build ordinary software without experiencing as much pain as their counterparts in the ML department, it begs the question: should we just start treating ML projects as software engineering projects as usual, maybe educating ML practitioners about the existing best practices? Orchestration. Versioning.
Designing for high throughput with 11 9s of durability OpenSearch Service manages tens of thousands of OpenSearch clusters. This makes sure that in the event of a cluster-manager quorum loss, which is a common failure mode in non-dedicated cluster-manager setups, OpenSearch can reliably recover the last acknowledged metadata.
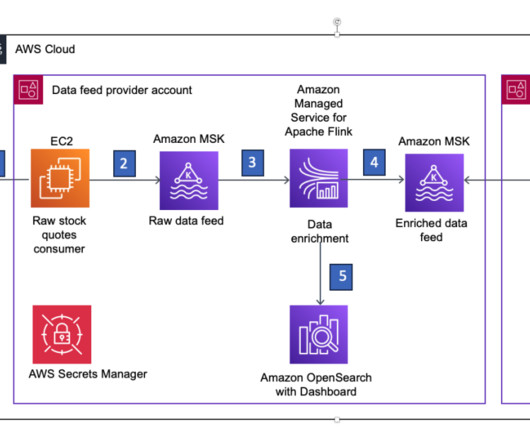
In this post, we demonstrate how you can publish an enriched real-time data feed on AWS using Amazon Managed Streaming for Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink. Amazon MSK is a fully managed service that makes it easy for you to build and run applications on AWS that use Kafka to process streaming data.
All else being equal, a shorter sales cycle is better, and so this graph’s ability to compare your different sales managers/representatives closing rates can show you who your top performers are. Just make sure to see the size of the deals your managers are closing, and keep track of the CLV of those customers. click to enlarge**.
Smarten announces the launch of SnapShot Anomaly Monitoring Alerts for Smarten Augmented Analytics. SnapShot Monitoring provides powerful data analytical features that reveal trends and anomalies and allow the enterprise to map targets and adapt to changing markets with clear, prescribed actions for continuous improvement.
Zero-ETL is a set of fully managed integrations by AWS that minimizes the need to build ETL data pipelines. We take care of the ETL for you by automating the creation and management of data replication. Zero-ETL provides service-managed replication. Glue ETL offers customer-managed data ingestion. What is zero-ETL?
Amazon Managed Service for Apache Flink is a fully managed service that reduces the complexity of building and managing Apache Flink applications. Amazon Managed Service for Apache Flink manages the underlying Apache Flink components that provide durable application state, metrics, logs, and more.
These formats enable ACID (atomicity, consistency, isolation, durability) transactions, upserts, and deletes, and advanced features such as time travel and snapshots that were previously only available in data warehouses. For more information, refer to Amazon S3: Allows read and write access to objects in an S3 Bucket.
Iceberg tables maintain metadata to abstract large collections of files, providing data management features including time travel, rollback, data compaction, and full schema evolution, reducing management overhead. Snowflake integrates with AWS Glue Data Catalog to retrieve the snapshot location.
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. With built-in features such as automated snapshots and cross-Region replication, you can enhance your disaster resilience with Amazon Redshift. Using backups Backing up data is an important part of data management.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content