This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. The post Model Risk Management And the Role of Explainable Models(With Python Code) appeared first on Analytics Vidhya. Photo by h heyerlein on Unsplash Introduction Similar to rule-based mathematical.
Entity resolution merges the entities which appear consistently across two or more structureddata sources, while preserving evidence decisions. A generalized, unbundled workflow A more accountable approach to GraphRAG is to unbundle the process of knowledge graph construction, paying special attention to data quality.
The post Leveraging Machine Learning for Efficiency in Supply Chain Management appeared first on Analytics Vidhya. Machine learning, deep learning, and AI are enabling transformational change in all fields from medicine to music. It is helping businesses from procuring to.
This article was published as a part of the Data Science Blogathon. Introduction Since the 1970s, relational database management systems have solved the problems of storing and maintaining large volumes of structureddata.
They primarily address the requirements of contemporary applications handling high-dimensional data. Traditional databases use tables and rows to store and query structureddata.
Introduction For decades the datamanagement space has been dominated by relational databases(RDBMS); that’s why whenever we have been asked to store any volume of data, the default storage is RDBMS.
Once the province of the data warehouse team, datamanagement has increasingly become a C-suite priority, with data quality seen as key for both customer experience and business performance. But along with siloed data and compliance concerns , poor data quality is holding back enterprise AI projects.
According to Kari Briski, VP of AI models, software, and services at Nvidia, successfully implementing gen AI hinges on effective datamanagement and evaluating how different models work together to serve a specific use case. Datamanagement, when done poorly, results in both diminished returns and extra costs.
Philosophers and economists may argue about the quality of the metaphor, but there’s no doubt that organizing and analyzing data is a vital endeavor for any enterprise looking to deliver on the promise of data-driven decision-making. And to do so, a solid datamanagement strategy is key. Data storage costs are exploding.
While this process is complex and data-intensive, it relies on structureddata and established statistical methods. This is where an LLM could become invaluable, providing the ability to analyze this unstructured data and integrate it with the existing structureddata models.
It encompasses the people, processes, and technologies required to manage and protect data assets. The DataManagement Association (DAMA) International defines it as the “planning, oversight, and control over management of data and the use of data and data-related sources.”
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structureddata.
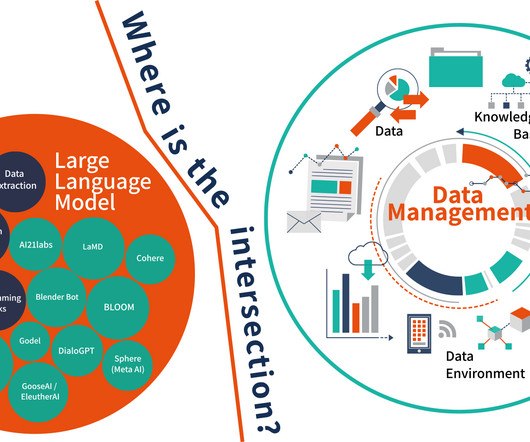
I did some research because I wanted to create a basic framework on the intersection between large language models (LLM) and datamanagement. I urge early adopters to think of this as an extension of their existing efforts to get the data and associated processes within your organization defined, managed, and governed.
These improvements collectively reinforce Amazon Redshifts focus as a leading cloud data warehouse solution, offering unparalleled performance and value to customers. General availability of multi-data warehouse writes Amazon Redshift allows you to seamlessly scale with multi-cluster deployments.
Soumya Seetharam, CDIO at Corning, said the manufacturer has been on its data journey for a few years, with more than 70% of its business transaction data being ingested into a data platform. But that’s only structureddata, she emphasized.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. With the addition of these technologies alongside existing systems like terminal operating systems (TOS) and SAP, the number of data producers has grown substantially.
This article was published as a part of the Data Science Blogathon. Introduction on Django The GCP Console is a tool that allows you to manage your Google Cloud Platform, and it addresses your Google Cloud projects and provides a web-based graphical UI. Popular services of Google Cloud: 1. Compute Engine 2. Cloud Storage 3.
These required specialized roles and teams to collect domain-specific data, prepare features, label data, retrain and manage the entire lifecycle of a model. Take, for example, an app for recording and managing travel expenses. A manager wants to assess the general mood of the team during a specific week.
In fact, data professionals spend 80 percent of their time looking for and preparing data and only 20 percent of their time on analysis , according to IDC. To flip this 80/20 rule, they need an automated metadata management solution for: • Discovering data – Identify and interrogate metadata from various datamanagement silos.
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it cost-effective to analyze your data using standard SQL and business intelligence tools. However, if you want to test the examples using sample data, download the sample data. Raza Hafeez is a Senior Product Manager at Amazon Redshift.
This article was published as a part of the Data Science Blogathon Introduction Google’s BigQuery is an enterprise-grade cloud-native data warehouse. Since its inception, BigQuery has evolved into a more economical and fully manageddata warehouse that can run lightning-fast […].
It describes the system from different viewpoints like developers, engineers, project managers or stakeholders. Introduction 4+1 architectural views represent the overall architecture of the software incentive system. These 4 views are logical, process, development and physical. The +1 view represents the scenarios view, which […].
In this post, we show you how to establish the data ingestion pipeline between Google Analytics 4, Google Sheets, and an Amazon Redshift Serverless workgroup. It also helps you securely access your data in operational databases, data lakes, or third-party datasets with minimal movement or copying of data.
Data Warehouses and Data Lakes in a Nutshell. A data warehouse is used as a central storage space for large amounts of structureddata coming from various sources. On the other hand, data lakes are flexible storages used to store unstructured, semi-structured, or structured raw data.
For everything to be well coordinated you require tools that will effectively manage the orders, stocks and […] The post Difference Between Non Relational Database and Relational Database appeared first on Analytics Vidhya.
Imagine a future where artificial intelligence (AI) seamlessly collaborates with existing supply chain solutions, redefining how organizations manage their assets. Let’s look at some of those challenges to generative AI for asset performance management. Undoubtedly. But what if you could optimize even further?
A data scientist’s approach to data analysis depends on their industry and the specific needs of the business or department they are working for. Before a data scientist can find meaning in structured or unstructured data, business leaders and department managers must communicate what they’re looking for.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structureddata stores such as data warehouses to multi-format data stores like data lakes. Trulens), but this can be much more complex at an enterprise-level to manage.
The two pillars of data analytics include data mining and warehousing. They are essential for data collection, management, storage, and analysis. Both are associated with data usage but differ from each other.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in data science and for managingdata infrastructure.
This fragmentation can delay decision-making and erode trust in available data. Amazon DataZone , a datamanagement service, helps you catalog, discover, share, and govern data stored across AWS, on-premises systems, and third-party sources. This approach streamlines data access while ensuring proper governance.
Introduction In this constantly growing era, the volume of data is increasing rapidly, and tons of data points are produced every second. Now, businesses are looking for different types of data storage to store and manage their data effectively.
However, enterprise data generated from siloed sources combined with the lack of a data integration strategy creates challenges for provisioning the data for generative AI applications. As part of the transformation, the objects need to be treated to ensure data privacy (for example, PII redaction).
Introduction on Databases like MySQL Nowadays data is growing exponentially in this world. But we need a way to store, process, and use this data efficiently in the future. Databases are used to manage the data […]. This led to the evolution of Databases.
Preparing and annotating data IBM watsonx.data helps organizations put their data to work, curating and preparing data for use in AI models and applications. “Being able to organize the data around that structure helps us to efficiently query, retrieve and use the information downstream, for example for AI narration.”
“Without big data, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore, management consultant, and author. In a world dominated by data, it’s more important than ever for businesses to understand how to extract every drop of value from the raft of digital insights available at their fingertips.
Intelligent document processing (IDP) is changing the dynamic of a longstanding enterprise content management problem: dealing with unstructured content. Gartner estimates unstructured content makes up 80% to 90% of all new data and is growing three times faster than structureddata 1. 20, 2023.
That’s why a business needs a proper analytical report that will help filter important data and improve the creation of the full management report that can lead to a successful business operation. The American Journal of Managed Care even stated in its own research that the total waiting amount is 121 minutes.
A lot of data to structure Work is also underway to structuredata thats scattered in many places. Theres a considerable amount of old data, specifically from old trains, and there has to be robust traceability when it comes to train traffic.
Let’s explore the continued relevance of data modeling and its journey through history, challenges faced, adaptations made, and its pivotal role in the new age of data platforms, AI, and democratized data access. These systems had limitations in terms of flexibility and scalability.
The key is to make data actionable for AI by implementing a comprehensive datamanagement strategy. That’s because data is often siloed across on-premises, multiple clouds, and at the edge. Getting the right and optimal responses out of GenAI models requires fine-tuning with industry and company-specific data.
However, they do contain effective datamanagement, organization, and integrity capabilities. As a result, users can easily find what they need, and organizations avoid the operational and cost burdens of storing unneeded or duplicate data copies. On the other hand, they don’t support transactions or enforce data quality.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Structured Query Language (SQL) has long been the standard for managing and querying relational databases, providing a powerful toolset for extracting insights from structureddata.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content