This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer. This ensures that each change is tracked and reversible, enhancing data governance and auditability.
A recent survey investigated how companies are approaching their AI and ML practices, and measured the sophistication of their efforts. On the other hand, we wanted to measure the sophistication of their use of these components. On one hand, we wanted to see whether companies were building out key components.
Metadata is the pertinent, practical details about data assets: what they are, what to use them for, what to use them with. Without metadata, data is just a heap of numbers and letters collecting dust. Where does metadata come from? What is a metadata management tool? What are examples of metadata management tools?
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
The analytics that drive AI and machine learning can quickly become compliance liabilities if security, governance, metadata management, and automation aren’t applied cohesively across every stage of the data lifecycle and across all environments.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data quality must be embedded into how data is structured, governed, measured and operationalized. Publish metadata, documentation and use guidelines.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight. With Lake Formation, creating these duplicates is no longer necessary.
From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. The data in the central data warehouse in Amazon Redshift is then processed for analytical needs and the metadata is shared to the consumers through Amazon DataZone. This process is shown in the following figure.
Data catalogs combine physical system catalogs, critical data elements, and key performance measures with clearly defined product and sales goals in certain circumstances. You also can manage the effectiveness of your business and ensure you understand what critical systems are for business continuity and measuring corporate performance.
SCM is complex, and S&OP implementation can be difficult, but the SCOR model is intended to help standardize the process and create a measurable way to track results. The updated version includes more emerging drivers of supply chain success, covering topics such as omnichannel, metadata, and blockchain , according to the ASCM.
With this approach, you create a new Amazon MWAA environment, migrate your metadata, and manage the transition between environments. The Airflow scheduler automatically populates some metadata tables (dag, dag_tag, and dag_code) in your new environment. Back up your current environment configuration and metadata.
This platform will incorporate robust cataloging, making sure the data is easily searchable, and will enforce the necessary security and governance measures for selective sharing among business stakeholders, data engineers, analysts, security and governance officers. Amazon Athena is used to query, and explore the data.
There’s an expression: measure twice, cut once. Data modeling is the upfront “measuring tool” that helps organizations reduce time and avoid guesswork in a low-cost environment. Design-layer metadata can also be connected from conceptual through logical to physical data models.
It reads metadata from your structured data store to generate SQL queries. Under Default storage metadata , select Amazon Redshift databases and for Database , choose dev. Security and compliance When integrating Amazon Bedrock with Amazon Redshift, implementing robust security measures is crucial. Choose Next.
5) How Do You Measure Data Quality? In this article, we will detail everything which is at stake when we talk about DQM: why it is essential, how to measure data quality, the pillars of good quality management, and some data quality control techniques. How Do You Measure Data Quality? Table of Contents. 2) Why Do You Need DQM?
You might have millions of short videos , with user ratings and limited metadata about the creators or content. Job postings have a much shorter relevant lifetime than movies, so content-based features and metadata about the company, skills, and education requirements will be more important in this case.
A catalog of validation data sets and the accuracy measurements of stored models. Metadata and artifacts needed for a full audit trail. Measuring online accuracy per customer / geography / demographic group is important both to monitor bias and to ensure accuracy for a growing customer base.
This measures the consistency of annotations when more than one person is involved in the process. What Are The Benefits Of Using Ontotext Metadata Studio? Ontotext Metadata Studio’s modeling power and flexibility enables out-of-the-box rapid NLP prototyping and development.
For the files with unknown structures, AWS Glue crawlers are used to extract metadata and create table definitions in the Data Catalog. These table definitions are used as the metadata repository for external tables in Amazon Redshift.
Common themes were the growing importance of governance metadata, especially in the areas of business value, success measurement and reduction in operational and data risk. The future lies in metadata management. Governance metadata management […].
Know thy data: understand what it is (formats, types, sampling, who, what, when, where, why), encourage the use of data across the enterprise, and enrich your datasets with searchable (semantic and content-based) metadata (labels, annotations, tags). The latter is essential for Generative AI implementations.
Consent" in medicine is limited: whether or not you understand what you're consenting to, you are consenting to a single procedure (plus emergency measures if things go badly wrong). The doctor can't come back and do a second operation without further consent.
The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. HandleTime – This customer service metric measures the length of a customer’s call. Use the following code: import boto3 import json # Create S3 object s3_client = boto3.client("s3")
Without a way to define and measure data confidence, AI model training environments, data analytics systems, automation engines, and so on must simply trust that the data has not been simulated, corrupted, poisoned, or otherwise maliciously generated—increasing the risks of downtime and other disasters.
Active metadata will play a critical role in automating such updates as they arise. This has been the dominant approach for nearly 50 years, and in my opinion, was born out of the work of Thomas McCabe in the 1970’s to measure the complexity of Cobol programs. Why Focus on Lineage? Support for all technologies.
Now that pulling stakeholders into a room has been disrupted … what if we could use this as 40 opportunities to update the metadata PER DAY? Overcoming the 80/20 Rule with Micro Governance for Metadata. What if we could buck the trend, and overcome the 80/20 rule?
It shows the quality of the dataset and number of columns with listing down the missing values, duplicates, and measure and dimension columns. Column Metadata – Provides information on the dataset’s recency, such as the last update and publication dates.
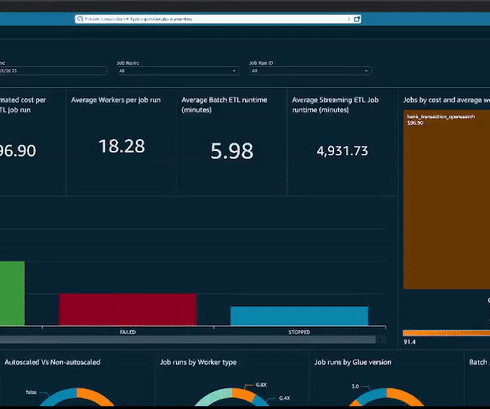
The metadata is extracted from each job run, including information like runtime, start time, end time, auto scaling, number of workers, and worker type, and is written to an Amazon DynamoDB table with TTL (time to live) enabled to ensure the table doesn’t grow too large. If the tables don’t exist, Athena creates them.
Finally, when your implementation is complete, you can track and measure your process. Monitoring Job Metadata. Figure 7 shows how the DataKitchen DataOps Platform helps to keep track of all the instances of a job being submitted and its metadata. DataOps Project Design and Implementation.
Metadata Caching. This is used to provide very low latency access to table metadata and file locations in order to avoid making expensive remote RPCs to services like the Hive Metastore (HMS) or the HDFS Name Node, which can be busy with JVM garbage collection or handling requests for other high latency batch workloads.
To perform the tests within a specific time frame and budget, we focused on the test scenarios that could efficiently measure the cluster’s capacity. It’s a preventative measure rather than a reactive response to a performance degradation. The following figure shows an example of a test cluster’s performance metrics.
Observability for your most secure data For your most sensitive, protected data, we understand even the metadata and telemetry about your workloads must be kept under close watch, and it must stay within your secured environment. Wouldn’t it be great if you could also have some observability into what tables are hot and cold?
Benchmark setup In our testing, we used the 3 TB dataset stored in Amazon S3 in compressed Parquet format and metadata for databases and tables is stored in the AWS Glue Data Catalog. The following graph shows performance improvements measured by the total query runtime (in seconds) for the benchmark queries. With Amazon EMR 6.10.0
The Digital Charter covers aspects of digital policy ranging from increased digital access for Canadians to measures that protect democracy and accurately identify hate speech. A key system to smooth out the bumps is a metadata management platform that includes automated data discovery and automated data lineage. Well, not quite yet.
It involves defining data standards, access controls, and data quality measures. Use Existing Catalog Metadata Standards Ensuring consistency and interoperability within your data catalog involves defining catalog metadata standards and data models. Such standards may stipulate uniform headers, mandatory descriptions, etc.,
Chapin also mentioned that measuring cycle time and benchmarking metrics upfront was absolutely critical. “It It takes them out of the craft world of people talking to people and praying, to one where there’s constant monitoring, constant measuring against baseline. [It Design for measurability. DataOps Maximizes Your ROI.
A domain is a unit that includes integrated or raw data, artifacts created from data, the code that acts upon the data, the team responsible for the data, and metadata such as data catalog, lineage, and processing history. Chris talks about the idea of a ‘domain’ as a principle of Data Mesh.
Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata. Key features include a collaborative business glossary, the ability to visualize data lineage, and generate data quality measurements based on business definitions.
This process embeds continuous improvement into the system through steps that monitor and measure performance to (1) glean insights and (2) integrate those lessons into the governance system. In other words, leaders must clarify how things will be governed, who is responsible, and how success or failure will be measured.
However, the software providers Intelligent Data Management Cloud addresses data-related capabilities, including data cataloging and metadata management, data engineering, application and application programming interface integration, data quality and observability, master data management, data sharing and data governance.
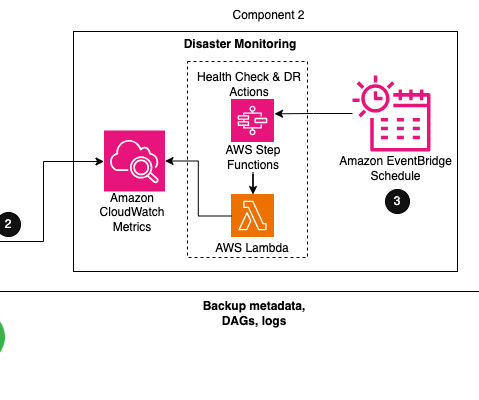
Within Airflow, the metadata database is a core component storing configuration variables, roles, permissions, and DAG run histories. A healthy metadata database is therefore critical for your Airflow environment. The third component is for creating and storing backups of all configurations and metadata that is required to restore.
First, you figure out what you want to improve; then you create an experiment; then you run the experiment; then you measure the results and decide what to do. For each of them, write down the KPI you're measuring, and what that KPI should be for you to consider your efforts a success. Measure and decide what to do.
The webinar looked at how to gauge the maturity and progress of data governance programs and why it is important for both IT and the business to be able to measure success. This webinar will discuss how to answer critical questions through data catalogs and business glossaries, powered by effective metadata management.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content