This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction There are so many performance evaluation measures when it comes to. The post Decluttering the performance measures of classification models appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
The post Interpretation of Performance Measures to Evaluate Models appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction In the last year of my bachelor’s degree, I.
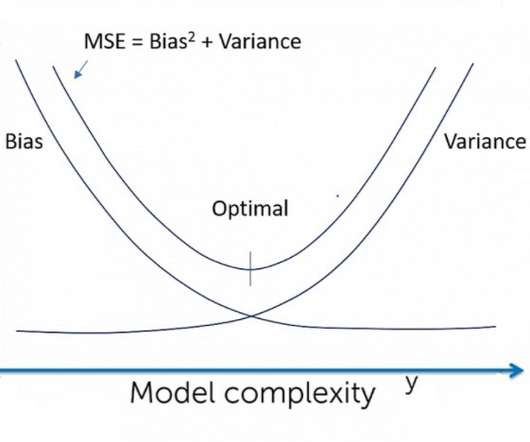
Introduction One of the most used matrices for measuringmodel performance is. The post A Measure of Bias and Variance – An Experiment appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
Large language models (LLMs) have become incredibly advanced and widely used, powering everything from chatbots to content creation. One critical measure is toxicityassessing whether AI […] The post Evaluating Toxicity in Large Language Models appeared first on Analytics Vidhya.
Speaker: Dave Mariani, Co-founder & Chief Technology Officer, AtScale; Bob Kelly, Director of Education and Enablement, AtScale
Given how data changes fast, there’s a clear need for a measuring stick for data and analytics maturity. Using data models to create a single source of truth. It includes on-demand video modules and a free assessment tool for prescriptive guidance on how to further improve your capabilities. Integrating data from third-party sources.
Introduction Large Language Models (LLMs) have captivated the world with their ability to generate human-quality text, translate languages, summarize content, and answer complex questions. As LLMs become more powerful and sophisticated, so does the importance of measuring the performance of LLM-based applications.
In low-income nations, where prices can be unpredictable and challenging to measure, a combination of surveys and machine learning predictions can produce […] The post World Bank’s Machine Learning Model to Save Lives in Low-Income Areas appeared first on Analytics Vidhya.
As indicated in machine learning and statistical modeling, the assessment of models impacts results significantly. Meet the F-Beta Score, a more unrestrictive measure that let the user weights precision over recall or […] The post What is F-Beta Score?
The Evolution of Expectations For years, the AI world was driven by scaling laws : the empirical observation that larger models and bigger datasets led to proportionally better performance. This fueled a belief that simply making models bigger would solve deeper issues like accuracy, understanding, and reasoning.
Speaker: Mike Rizzo, Founder & CEO, MarketingOps.com and Darrell Alfonso, Director of Marketing Strategy and Operations, Indeed.com
We will dive into the 7 P Model —a powerful framework designed to assess and optimize your marketing operations function. In this exclusive webinar led by industry visionaries Mike Rizzo and Darrell Alfonso, we’re giving marketing operations the recognition they deserve! Secure your seat and register today!
Thats where the SCOR model comes in. What is the SCOR model? The SCOR model is designed to evaluate your supply chain for effectiveness and efficiency of sales and operational planning (S&OP). What is the main focus of the SCOR model? model to further address the growing need for digitization of supply chains.
Imagine an AI that can write poetry, draft legal documents, or summarize complex research papersbut how do we truly measure its effectiveness? As Large Language Models (LLMs) blur the lines between human and machine-generated content, the quest for reliable evaluation metrics has become more critical than ever.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
Introduction Evaluation metrics are used to measure the quality of the model. Selecting an appropriate evaluation metric is important because it can impact your selection of a model or decide whether to put your model into production. This article was published as a part of the Data Science Blogathon.
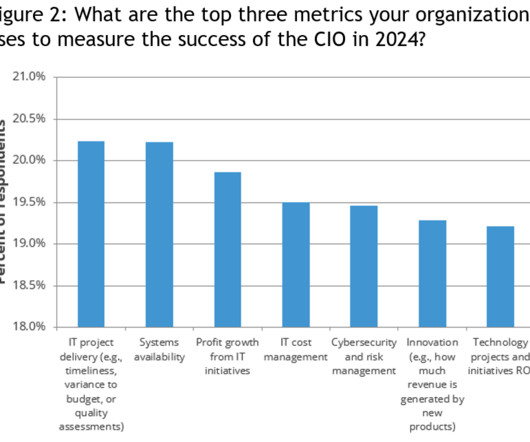
Regardless of where organizations are in their digital transformation, CIOs must provide their board of directors, executive committees, and employees definitions of successful outcomes and measurable key performance indicators (KPIs). He suggests, “Choose what you measure carefully to achieve the desired results.
Evaluating language models has always been a challenging task. How do we measure if a model truly understands language, generates coherent text, or produces accurate responses?
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., at Facebook—both from 2020.
Early tools applied rudimentary machine learning (ML) models to customer relationship management (CRM) exports, assigning win probability scores or advising on the ideal time to call. When evaluating any AI software provider, ignore sales and marketing hype and question the measurable business impact.
Large Language Models (LLMs) have become integral to modern AI applications, but evaluating their capabilities remains a challenge. Traditional benchmarks have long been the standard for measuring LLM performance, but with the rapid evolution of AI, many are questioning their continued relevance.
Kevlin Henney and I were riffing on some ideas about GitHub Copilot , the tool for automatically generating code base on GPT-3’s language model, trained on the body of code that’s in GitHub. The model will certainly need to be re-trained from time to time. Thomas Johnson said, “Perhaps what you measure is what you get.
Throughout this article, well explore real-world examples of LLM application development and then consolidate what weve learned into a set of first principlescovering areas like nondeterminism, evaluation approaches, and iteration cyclesthat can guide your work regardless of which models or frameworks you choose. How will you measure success?
In a startling revelation, researchers at Anthropic have uncovered a disconcerting aspect of Large Language Models (LLMs) – their capacity to behave deceptively in specific situations, eluding conventional safety measures.
Three protocols in particular Model Context Protocol (MCP), Agent Communication Protocol (ACP), and Agent2Agent show promise for helping IT leaders put two-plus years of failed proof-of-concept projects behind them, opening a new era of measurable AI progress , experts contend. Say theres 100,000 models out there, he says.
This is particularly true with enterprise deployments as the capabilities of existing models, coupled with the complexities of many business workflows, led to slower progress than many expected. Foundation models (FMs) by design are trained on a wide range of data scraped and sourced from multiple public sources.
In a bid to bolster cybersecurity measures, Google has unveiled Magika, an AI-driven file detection tool aimed at identifying malicious files with unprecedented speed and accuracy.
By articulating fitness functions automated tests tied to specific quality attributes like reliability, security or performance teams can visualize and measure system qualities that align with business goals. Documentation and diagrams transform abstract discussions into something tangible.
Take for instance large language models (LLMs) for GenAI. Then there’s reinforcement learning, a type of machine learning model that trains algorithms to make effective cybersecurity decisions. But when it comes to cybersecurity, AI has become a double-edged sword.
When developing AI solutions, training the model and reducing common AI problems like hallucination, data protection, privacy and unlearning the model can be costly on the real system and hence developing a digital twin solution in AI can help to simulate the real system and tune the system before deploying to productionized environments.
ISG Research asserts that by 2027, one-third of enterprises will incorporate comprehensive external measures to enable ML to support AI and predictive analytics and achieve more consistently performative planning models. Few go deeper or gather external data in a way that makes it accessible across an enterprise.
As digital transformation becomes a critical driver of business success, many organizations still measure CIO performance based on traditional IT values rather than transformative outcomes. This creates a disconnect between the strategic role that CIOs are increasingly expected to play and how their success is measured.
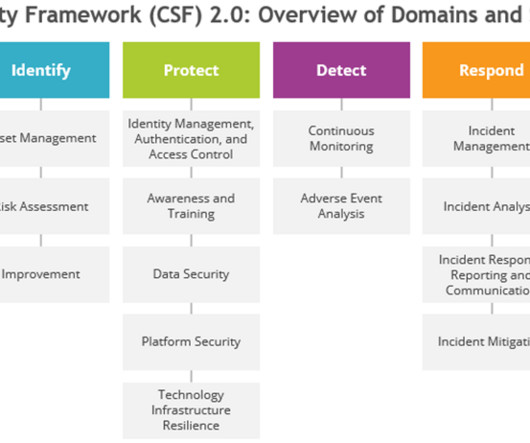
CISOs can only know the performance and maturity of their security program by actively measuring it themselves; after all, to measure is to know. However, CISOs aren’t typically measuring their security program proactively or methodically to understand their current security program. people, processes, and technology).
The world changed on November 30, 2022 as surely as it did on August 12, 1908 when the first Model T left the Ford assembly line. If we want prosocial outcomes, we need to design and report on the metrics that explicitly aim for those outcomes and measure the extent to which they have been achieved.
There is a clear rise in phishing, and the malicious use of artificial intelligence (AI) is bypassing traditional security measures. The successful ones choose zero trust architecture rather than the network-centric, perimeter-based security models that are unequipped to face the threats of the digital era.
Additionally, while the tools available at the time enabled data teams to respond to quality issues, they did not provide a way to identify quality thresholds or measure improvement, making it difficult to demonstrate to the business the value of time spent remedying data-quality problems. With
Set clear, measurable metrics around what you want to improve with generative AI, including the pain points and the opportunities, says Shaown Nandi, director of technology at AWS. In HR, measure time-to-hire and candidate quality to ensure AI-driven recruitment aligns with business goals.
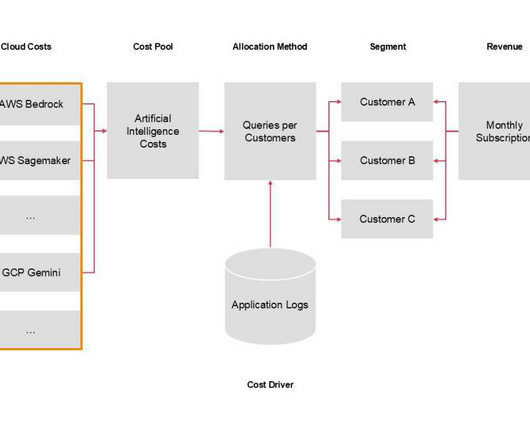
As a result, organisations are continually investing in cloud to re-invent existing business models and leapfrog their competitors. What began as a need to navigate complex pricing models to better control costs and gain efficiency has evolved into a focus on demonstrating the value of cloud through Unit Economics.
From the discussions, it is clear that today, the critical focus for CISOs, CIOs, CDOs, and CTOs centers on protecting proprietary AI models from attack and protecting proprietary data from being ingested by public AI models. isnt intentionally or accidentally exfiltrated into a public LLM model?
The government also plans to introduce measures to support businesses, particularly small and medium-sized enterprises (SMEs), in adopting responsible AI management practices through a new self-assessment tool. Meanwhile, the measures could also introduce fresh challenges for businesses, particularly SMEs.
Instead of seeing digital as a new paradigm for our business, we over-indexed on digitizing legacy models and processes and modernizing our existing organization. This only fortified traditional models instead of breaking down the walls that separate people and work inside our organizations. And its testing us all over again.
China is taking a significant step forward in regulating generative artificial intelligence (Generative AI) services with the release of draft measures by the Cyberspace Administration of China (CAC). These proposed rules aim to manage and regulate the use of Generative AI in the country.
Instead of writing code with hard-coded algorithms and rules that always behave in a predictable manner, ML engineers collect a large number of examples of input and output pairs and use them as training data for their models. The model is produced by code, but it isn’t code; it’s an artifact of the code and the training data.
Experimentation: It’s just not possible to create a product by building, evaluating, and deploying a single model. In reality, many candidate models (frequently hundreds or even thousands) are created during the development process. Modelling: The model is often misconstrued as the most important component of an AI product.
Depending on your needs, large language models (LLMs) may not be necessary for your operations, since they are trained on massive amounts of text and are largely for general use. As a result, they may not be the most cost-efficient AI model to adopt, as they can be extremely compute-intensive.
By 2028, 40% of large enterprises will deploy AI to manipulate and measure employee mood and behaviors, all in the name of profit. “AI CMOs view GenAI as a tool that can launch both new products and business models. AI has the capability to perform sentiment analysis on workplace interactions and communications.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content