This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Systems of this nature generate a huge number of small objects and need attention to compact them to a more optimal size for faster reading, such as 128 MB, 256 MB, or 512 MB. As of this writing, only the optimize-data optimization is supported. Note the last four newly added configurations in the following statement.
Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. Query optimization in databases is a long standing area of research, with much emphasis on finding near optimal query plans.
You can use big data analytics in logistics, for instance, to optimize routing, improve factory processes, and create razor-sharp efficiency across the entire supply chain. According to studies, 92% of data leaders say their businesses saw measurable value from their data and analytics investments.
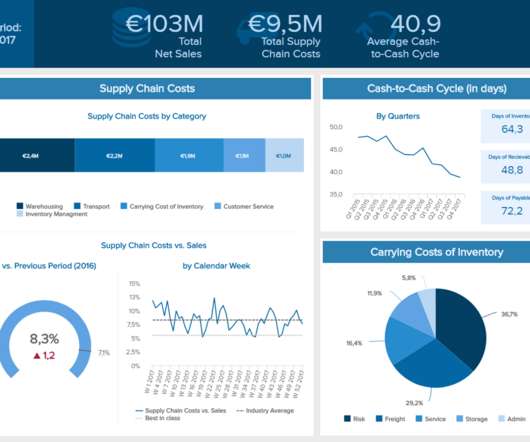
That’s why it’s critical to monitor and optimize relevant supply chain metrics. While there are numerous KPI examples you can select for your assessment and optimization, we have focused on a list that will enable you to identify potential bottlenecks and ensure sustainable development. Freight Bill Accuracy.
Amazon OpenSearch Service introduced the OpenSearch Optimized Instances (OR1) , deliver price-performance improvement over existing instances. For more details about OR1 instances, refer to Amazon OpenSearch Service Under the Hood: OpenSearch Optimized Instances (OR1). OR1 instances use a local and a remote store.
Internally, Apache Flink uses clever mechanisms to maintain exactly-once state consistency, while also optimizing for throughput and reduced latency. Each of the distributed components of an application asynchronously snapshots its state to an external persistent datastore. The default behavior works well for most use cases.
Despite their advantages, traditional data lake architectures often grapple with challenges such as understanding deviations from the most optimal state of the table over time, identifying issues in data pipelines, and monitoring a large number of tables. It is essential for optimizing read and write performance.
We’ve already discussed how checkpoints, when triggered by the job manager, signal all source operators to snapshot their state, which is then broadcasted as a special record called a checkpoint barrier. When barriers from all upstream partitions have arrived, the sub-task takes a snapshot of its state.
To manage the dynamism, we can resort to taking snapshots that represent immutable points in time: of models, of data, of code, and of internal state. However, none of these layers help with modeling and optimization. We cannot expect data scientists to write modeling frameworks like PyTorch or optimizers like Adam from scratch!
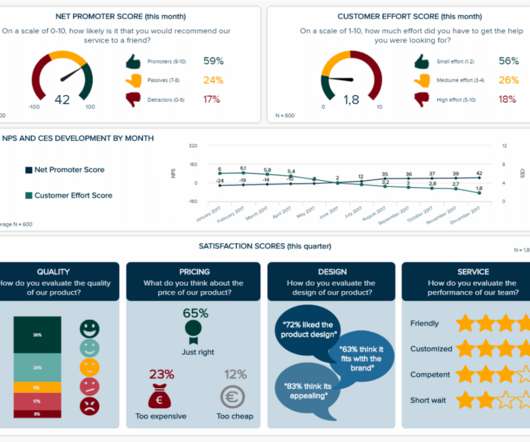
In today’s business world, competition is fierce across all industries and sectors, which means that to survive and thrive, working with measurable online data analysis and performance metrics is essential. As the saying goes: what gets measured can be improved. These metrics measure the success of your customer-centric operations.
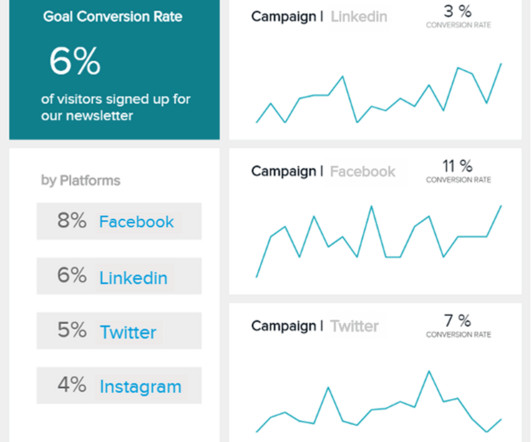
In a hyper-connected digital world driven by data, there has never been a better time for businesses to gather meaningful insights on their target prospects, in addition to measuring ongoing levels of commercial growth and performance. Social media KPIs are values that measure the performance of social media marketing (SMM) campaigns.
Operational optimization and forecasting. Every serious business uses key performance indicators to measure and evaluate success. Cost optimization. Another important factor to consider is cost optimization. Operational optimization and forecasting. Cost optimization. click to enlarge**.
An effective modern means of extracting real value from your research results such as brand analysis, market research reports present and arrange data in a way that is digestible and logical in equal measures through professional online reporting software and tools. You can also modify each, and use it as a client dashboard.
Armed with powerful visualizations and real-time data, modern weekly summary reports enable businesses to closely monitor their performance and the progress of their strategies to extract relevant insights and optimize their processes to ensure constant growth. Your Chance: Want to build great weekly status reports on your own?
A call center dashboard is an intuitive visual reporting tool that displays a range of relevant call center metrics and KPIs that allow customer service managers and teams to monitor and optimize performance and spot emerging trends in a central location. Put simply, customer service is the beating heart of your entire operation.
This means that cost-optimization exercises can happen at any time—they no longer need to happen in the planning phase. These scalable properties of Apache Flink can be key to optimizing your cost in the cloud. The third cost component is durable application backups, or snapshots. per GB per month.
A procurement report allows an organization to demonstrate how its procurement activities deliver value for money, contribute to the realization of its broader goals and objectives, and provide a panoramic snapshot of the effectiveness of its procurement strategy. e) Take accurate measurements. Manage your spend data.
The measurement and monitoring of your end-to-end process can serve as an important tool in the battle to eliminate errors. Week after week, it is measured with a million rows. These labor-intensive evaluations of data quality can only be performed periodically, so at best they provide a snapshot of quality at a particular time.
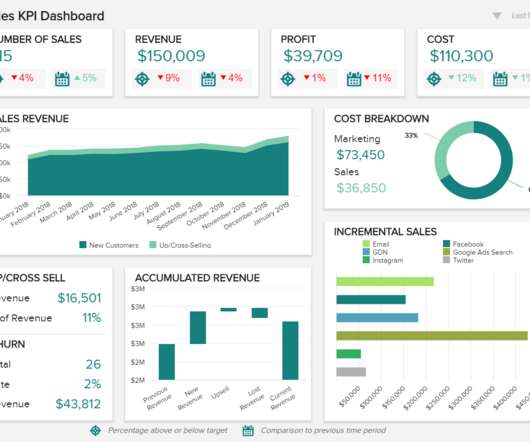
Incremental Sales Calculation As mentioned, incremental sales are used by businesses as a key performance indicator to measure the financial success of their promotional efforts. To ensure you yield the results you desire, first establish your goals, then decide on the metrics that you will need to track to measure your performance.
Further, how do you measure progress and convey to engineering that they are making progress? There is so much we cannot measure about the impact of a user experience. We can’t measure the little smile a product can put on someone’s face. Create a snapshot . Export the snapshot to the destination in the Cloud.
The importance of this finance dashboard lays within the fact that every finance manager can easily track and measure the whole financial overview of a specific company while gaining insights into the most valuable KPIs and metrics. click to enlarge**. What does this mean, exactly?
Example: Recrawl Logic within Google search Google search works because our software has previously crawled many billions of web pages, that is, scraped and snapshotted each one. These snapshots comprise what we refer to as our search index. Whenever a snapshot’s contents match its real-world counterpart, we call that snapshot ‘fresh.’
Usually, these reports are considered to be financial statements which include: a balance sheet: is a snapshot of a business at a specific time and shows the ending assets, liability, and equity balances as of the balance sheet date. It is useful to measure the financial reserves and liquidity of a business. The Balance Sheet.
To assess the nodes and find an optimal RA3 cluster configuration, we collaborated with AllCloud , the AWS premier consulting partner. To do this, we required the following: A reference cluster snapshot – This ensures that we can replay any tests starting from the same state. Take measurements 18 x DC2.
d) What KPIs, if measured, will help them reach their goals? Whatever the case, you want to know this – because if you don’t know how to make a dashboard that is better than their existing KPI measurement method, you’ll have wasted your time. Make Sure Your Dashboard Is Mobile-Optimized.
It provides a brief snapshot of the entire business. I humbly believe the challenge is that in a world of too much data, with lots more on the way, there is a deep desire amongst executives to get "summarize data," to get "just a snapshot," or to get the "top-line view." digital performance. Standstill.
Amazon Redshift delivers on that needed performance through a number of mechanisms such as caching, automated data model optimization, and automated query rewrites. String-optimized compression The Data Vault 2.0 You can use this mechanism to optimize merge operations while still making the data accessible from within Amazon Redshift.
Plus, metrics like click-through-rate will also help you gauge how engaging or effective specific marketing initiatives are, allowing you to make the tweaks necessary for optimal promotional success. You need to keep an optimal number of available staff to take care of patients and make sure you don’t overburden your employees.
Analytics and sales should partner to forecast new business revenue and manage pipeline, because sales teams that have an analyst dedicated to their data and trends, drive insights that optimize workflows and decision making. Key ways to optimize insights for sales. Daily snapshot of opportunities – a summary.
Extracting business insights based on factual data and not just simple intuition will lead companies to optimize several processes and ensure sustainable development. Improved decision-making: By providing real-time data from several sources, reporting monthly will significantly improve the decision-making process.
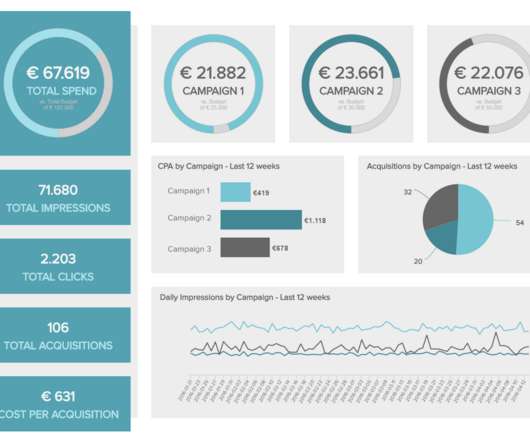
Some Marketers / Analysts use Click-thru Rate (CTR) to measure success of their acquisition campaigns. A smaller percent of those Marketers / Web Analysts will move beyond clicks and measure Visits / Visitors and Bounce Rates to measure success. How to optimally leverage value based segmentation & Lifetime Value.
KPIs make sure you can track and audit optimal implementation, achieve consumer satisfaction and trust, and minimize disruptions during the final transition. They measure workload trends, cost usage, data flow throughput, consumer data rendering, and real-life performance.
Once you have clearly identified your goals, it’s time to start thinking about the measurable values that you will use to track and determine your progress towards achieving them. HR managers are using supportive data and quantifiable measurements, like KPIs and metrics, to back up their employee hiring and retention related decisions.
Evolution: The ability to visualize your data will empower you to make continual improvements to your business, moving with the landscape around you by measuring and building upon your performance. Evidence: While this may seem like an abstract concept, when it comes to data analytics, the more panoramic a snapshot you can access, the better.
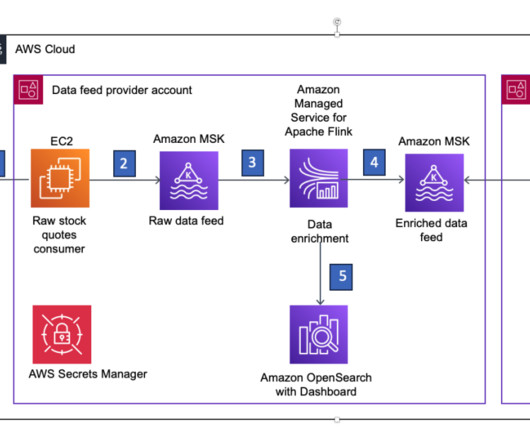
Real-time analytics architecture for time series Time series data is a sequence of data points recorded over a time interval for measuring events that change over time. State snapshot in Amazon S3 – You can store the state snapshot in Amazon S3 for tracking.
A bi-weekly scan of incomplete or erroneous records is essential to keep your database fully optimized and updated. It’s easy to get sidetracked with customer data management and optimize the particular CRM system in such a way that every available source of data is being tracked constantly. Focus on relevant data for relevant results.
Apache Flink is an opensource distributed processing engine, offering powerful programming interfaces for both stream and batch processing, with first-class support for stateful processing, event time semantics, checkpointing, snapshots and rollback. To run the application, choose Run , select Run with latest snapshot , and choose Run.
To optimize your CS offerings you need access to the right data, and this is where customer service reports come into play. It’s mainly about optimizing your processes and reaching the highest quality of your services with the lowest costs possible. It will also give you the most accurate view of your customer service data.
In the survey, 60% of senior decision makers report that their organization has not completely achieved maintaining performance measurement standards for applying data services to their operations at speed. Tactic 1: Maintain performance standards while keeping up with the pace. To find out more, click here.
A manufacturing Key Performance Indicator (KPI) or metric is a well defined and quantifiable measure that the manufacturing industry uses to gauge its performance over time. Manufacturing companies specifically use KPIs to monitor, analyze, and optimize operations, often comparing their efficiencies to those of competitors in the same sector.
InfiniSafe combines immutable snapshots of data, logical air gapping, a fenced forensic environment, and virtually instantaneous data recovery, and is now extended into the InfiniBox SSA II, as well as the entire InfiniBox family. .
The industry standard for measuring availability is class of nines. AWS also recommends choosing a primary shard count so that each shard is within an optimal size band. You can determine the optimal shard size through proof-of-concept testing with your data and traffic. minutes of downtime a month.
Staying ahead of increasing and evolving cybersecurity threats is a continuous effort that requires both a relentless focus on advancing your security posture and an optimized security stack that delivers on the promises made at purchase. Are there ways to optimize the current cost of our security posture? But is that really true?
Imagine you have a sequence of snapshots from a day in Justin Bieber’s life, and you want to label each image with the activity it represents (eating, sleeping, driving, etc.). One way is to ignore the sequential nature of the snapshots, and build a per-image classifier. Finding the Optimal Labeling. How can you do this?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content