This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction One of the most important applications of Statistics is looking into how two or more variables relate. Measuring the strength of that relationship […]. The post Statistical Effect Size and Python Implementation appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Statistics. The post The Measure of Central Tendencies in Statistics -A Beginner’s Guide appeared first on Analytics Vidhya. Whenever I hear this term, I imagine of below Image.
Probability is a cornerstone of statistics and data science, providing a framework to quantify uncertainty and make predictions. Probability measures the likelihood of an event […] The post What are Joint, Marginal, and Conditional Probability? This article unpacks these concepts with clear explanations and examples.
Introduction There are so many performance evaluation measures when it comes to. The post Decluttering the performance measures of classification models appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
Examining five years of anonymous data from over 6 million users in 170+ countries, Spigit has discovered that a culture of innovation can be measured – with a 99% statistical confidence level – by a metric called "ideation rate." Download the eBook now for an in-depth look at this groundbreaking study.
As indicated in machine learning and statistical modeling, the assessment of models impacts results significantly. Meet the F-Beta Score, a more unrestrictive measure that let the user weights precision over recall or […] The post What is F-Beta Score?
The post 3 Central Tendency Measures – Mean, Mode, Median appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon. When we learn Data Science as beginners we came across.
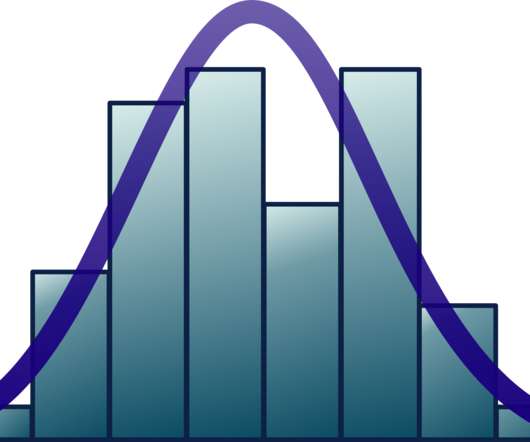
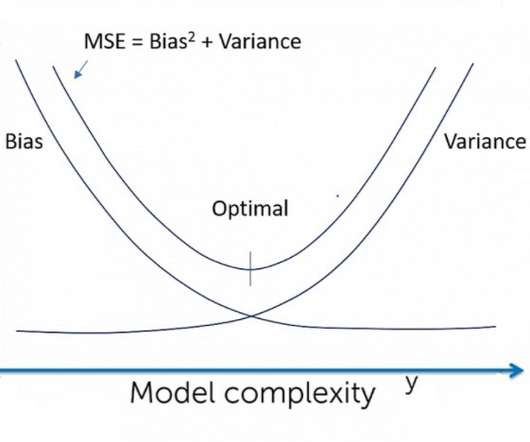
Introduction One of the most used matrices for measuring model performance is. The post A Measure of Bias and Variance – An Experiment appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
The post A/B Testing Measurement Frameworks ?- ?Every ArticleVideo Book This article was published as a part of the Data Science Blogathon. What is A/B testing? A/B Testing(split testing) is basically the. Every Data Scientist Should Know appeared first on Analytics Vidhya.
Introduction A fundamental component of statistical technique, regression analysis is essential for examining and measuring connections between variables. Its uses are numerous and diverse, from forecasting financial trends to evaluating medical results.
It covers examples such as drink sizes and professional ranks, applications in subjective evaluations like customer satisfaction surveys, appropriate statisticalmeasures, and the qualitative nature of ordinal data.
I use the term external data to include any information about the world outside an organization (including economic and market statistics), competitors (such as pricing and locations) and customers. Until recently, it was adequate for organizations to regard external data as a nice to have item, but that is no longer the case.
Here is the type of data insurance companies use to measure a client’s potential risk and determine rates. Statistics show that married people have fewer car accidents than singletons. Insurance companies have access to crime statistics and can track the number of car theft and break-ins per neighborhood. Demographics.
presented the TRACE framework for measuring results, which showed how GraphRAG achieves an average performance improvement of up to 14.03%. As a result, GraphRAG mixes two bodies of “AI” research: the more symbolic reasoning which knowledge graphs represent and the more statistical approaches of machine learning.
Measuring developer productivity has long been a Holy Grail of business. The US Bureau of Labor Statistics has projected that the number of software developers will grow 25% from 2021-31. In addition, system, team, and individual productivity all need to be measured. And like the Holy Grail, it has been elusive.
To counter such statistics, CIOs say they and their C-suite colleagues are devising more thoughtful strategies. How does our AI strategy support our business objectives, and how do we measure its value? So the organization as a whole has to have a clear way of measuring ROI, creating KPIs and OKRs or whatever framework theyre using.
Once you have your data analytics questions, you need to have some standard KPIs that you can use to measure them. OK – so far, you’ve picked out some data analysis questions, and you’ve found KPIs to measure them. There are basically 4 types of scales: *Statistics Level Measurement Table*. Did the best according to what?
In this blog post, we discuss the key statistics and prevention measures that can help you better protect your business in 2021. Cyber fraud statistics and preventions that every internet business needs to know to prevent data breaches in 2021. One bad breach and you are potentially risking your business in the hands of hackers.
Measuring AI ROI As the complexity of deploying AI within the enterprise becomes more apparent in 2025, concerns over ROI will also grow. Measuring the impact of new technologies from a financial and productivity perspective has been a challenge for many years. Part of the problem is the lack of common standards for measuring returns.
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. Enabling AWS Glue Data Catalog column statistics further improved performance by 3x versus last year.
There are also many important considerations that go beyond optimizing a statistical or quantitative metric. As we deploy ML in many real-world contexts, optimizing statistical or business metics alone will not suffice. Classification parity means that one or more of the standard performance measures (e.g.,
In this post, we outline planning a POC to measure media effectiveness in a paid advertising campaign. We chose to start this series with media measurement because “Results & Measurement” was the top ranked use case for data collaboration by customers in a recent survey the AWS Clean Rooms team conducted. and CTV.Co
Introduction What is the first measure coming into your mind. ArticleVideo Book This article was published as a part of the Data Science Blogathon. The post Confusion Matrix: Detailed intuition and trick to learn appeared first on Analytics Vidhya.
The surge of Big Data has ushered in a new era, where businesses grapple with massive amounts of data measured in petabytes […] The post What is the Difference Between Data Science and Machine Learning? They are utilized by various entities, ranging from novice computer science students to major organizations like Netflix and Amazon.
AWS Glue Data Quality reduces the effort required to validate data from days to hours, and provides computing recommendations, statistics, and insights about the resources required to run data validation. In this post, we provide benchmark results of running increasingly complex data quality rulesets over a predefined test dataset.
A recent O’Reilly survey found that those with mature AI practices (as measured by how long they’ve had models in production) cited “Lack of data or data quality issues” as the main bottleneck holding back further adoption of AI technologies. business and quality rules, policies, statistical signals in the data, etc.).
By implementing the right reporting tools and understanding how to analyze as well as to measure your data accurately, you will be able to make the kind of data driven decisions that will drive your business forward. Qualitative data analysis is based on observation rather than measurement. 9) Set measurable goals for decision making.
Web and application developers rely on synthetic monitoring that simulate user interactions at scale to measure performance and availability for different scenarios, locations, and devices instead of waiting for real users to hit problem areas or to test new apps and features before launch.
Once you’ve set your data sources, started to gather the raw data you consider to offer potential value, and established clearcut questions you want your insights to answer, you need to set a host of key performance indicators (KPIs) that will help you track, measure, and shape your progress in a number of key areas. Establish your questions.
Yet, before any serious data interpretation inquiry can begin, it should be understood that visual presentations of data findings are irrelevant unless a sound decision is made regarding scales of measurement. Interval: a measurement scale where data is grouped into categories with orderly and equal distances between the categories.
In addition, they can use statistical methods, algorithms and machine learning to more easily establish correlations and patterns, and thus make predictions about future developments and scenarios. Companies should then monitor the measures and adjust them as necessary. Big data and analytics provide valuable support in this regard.
Key statistics highlight the severity of the issue: 57% of respondents in a 2024 dbt Labs survey rated data quality as one of the three most challenging aspects of data preparation (up from 41% in 2023). Early measurements provide valuable insights that can guide future improvements.
Finally, data drift checks examine whether the statistical properties of the data have significantly shifted compared to historical baselines, which can help identify unexpected changes or trends that may affect data accuracy or stability. Documentation and analysis become natural outcomes, not barriers to progress.
The measurement and monitoring of your end-to-end process can serve as an important tool in the battle to eliminate errors. We liken this methodology to the statistical process controls advocated by management guru Dr. Edward Deming. Week after week, it is measured with a million rows. Statistical Process Control.
Insights discovery from ubiquitous data collection (via the tens of billions of connected devices that will be measuring, monitoring, and tracking nearly everything internally in our business environment and contextually in the broader market and global community) is ultimately about value creation and business outcomes.
“Skewness essentially measures the symmetry of the distribution, while kurtosis. ArticleVideo Book This article was published as a part of the Data Science Blogathon. The post Shape of data: Skewness and Kurtosis appeared first on Analytics Vidhya.
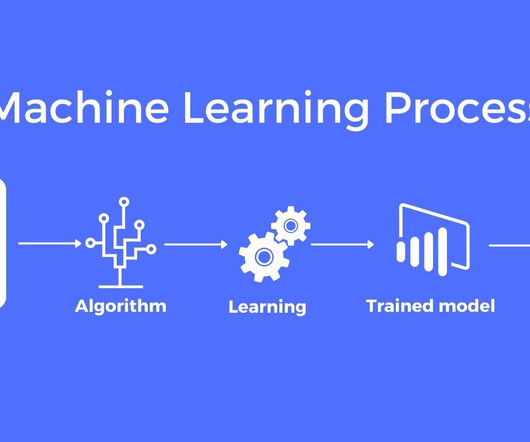
All you need to know for now is that machine learning uses statistical techniques to give computer systems the ability to “learn” by being trained on existing data. Measurement, tracking, and logging is less of a priority in enterprise software. Machine learning adds uncertainty.
We should clarify that SR 11-7 also covers models that aren’t necessarily based on machine learning: "quantitative method, system, or approach that applies statistical, economic, financial, or mathematical theories, techniques, and assumptions to process input data into quantitative estimates." Sources of model risk.
Business analytics is the practical application of statistical analysis and technologies on business data to identify and anticipate trends and predict business outcomes. Business analytics also involves data mining, statistical analysis, predictive modeling, and the like, but is focused on driving better business decisions.
4) How to Select Your KPIs 5) Avoid These KPI Mistakes 6) How To Choose A KPI Management Solution 7) KPI Management Examples Fact: 100% of statistics strategically placed at the top of blog posts are a direct result of people studying the dynamics of Key Performance Indicators, or KPIs. 3) What Are KPI Best Practices? What happens next?
This kind of humility is likely to deliver more meaningful progress and a more measured understanding of such progress. The claim is that AGI is now simply a matter of improving performance, both in hardware and software, and making models bigger, using more data and more kinds of data across more modes.
High throughput screening technologies have been developed to measure all the molecules of interest in a sample in a single experiment (e.g., Each of these behaviors wreak havoc on statistical analyses. Guest Post by Bill Shannon, Founder and Managing Partner of BioRankings. Introduction. Antimicrobial. Autoimmunity. IL-4, IL-13.
According to the US Bureau of Labor Statistics, demand for qualified business intelligence analysts and managers is expected to soar to 14% by 2026, with the overall need for data professionals to climb to 28% by the same year. The Bureau of Labor Statistics also states that in 2015, the annual median salary for BI analysts was $81,320.
The Curse of Dimensionality , or Large P, Small N, ((P >> N)) , problem applies to the latter case of lots of variables measured on a relatively few number of samples. Statistical methods for analyzing this two-dimensional data exist. This statistical test is correct because the data are (presumably) bivariate normal.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content