


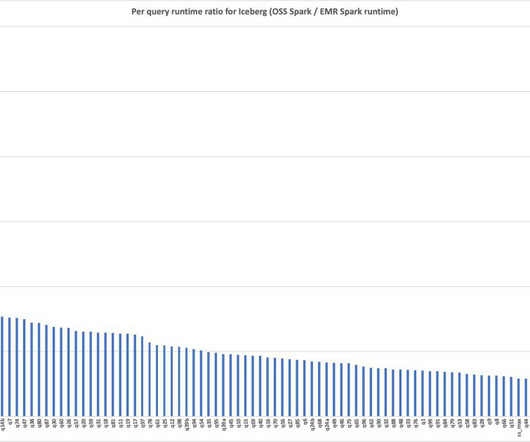
Amazon EMR 7.5 runtime for Apache Spark and Iceberg can run Spark workloads 3.6 times faster than Spark 3.5.3 and Iceberg 1.6.1
AWS Big Data
DECEMBER 27, 2024
jar,s3://blogpost-sparkoneks-us-east-1/blog/BLOG_TPCDS-TEST-3T-partitioned/, /home/hadoop/tpcds-kit/tools,parquet,3000,true, ,true,true],ActionOnFailure=CONTINUE --region Note the Hadoop catalog warehouse location and database name from the preceding step. You can track progress in /media/ephemeral0/spark_run.log. q14b-v2.13,q15-v2.13,q16-v2.13,




























Let's personalize your content