This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
6) Data Quality Metrics Examples. Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports.
In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer. It supports two types of reports: one for commits and one for scans.
To win in business you need to follow this process: Metrics > Hypothesis > Experiment > Act. We are far too enamored with data collection and reporting the standard metrics we love because others love them because someone else said they were nice so many years ago. That metric is tied to a KPI.
Whether youre a data analyst seeking a specific metric or a data steward validating metadata compliance, this update delivers a more precise, governed, and intuitive search experience. This reduces time-to-insight and makes sure the right metric is used in reporting.
For example, you can use metadata about the Kinesis data stream name to index by data stream ( ${getMetadata("kinesis_stream_name") ), or you can use document fields to index data depending on the CloudWatch log group or other document data ( ${path/to/field/in/document} ).
According to a study from Rocket Software and Foundry , 76% of IT decision-makers say challenges around accessing mainframe data and contextual metadata are a barrier to mainframe data usage, while 64% view integrating mainframe data with cloud data sources as the primary challenge.
Pricing and availability Amazon MWAA pricing dimensions remains unchanged, and you only pay for what you use: The environment class Metadata database storage consumed Metadata database storage pricing remains the same. micro, remember to monitor its performance using the recommended metrics to maintain optimal operation.
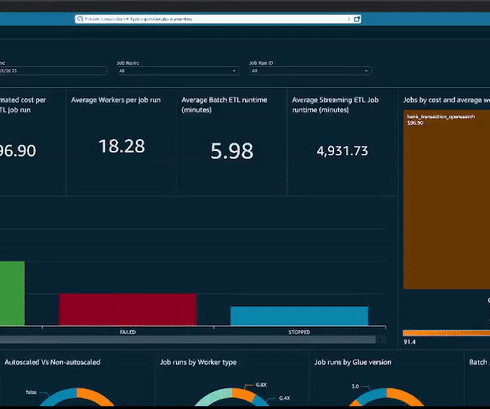
In this post, we explore how to combine AWS Glue usage information and metrics with centralized reporting and visualization using QuickSight. You have metrics available per job run within the AWS Glue console, but they don’t cover all available AWS Glue job metrics, and the visuals aren’t as interactive compared to the QuickSight dashboard.
How RFS works OpenSearch and Elasticsearch snapshots are a directory tree that contains both data and metadata. Metadata files exist in the snapshot to provide details about the snapshot as a whole, the source cluster’s global metadata and settings, each index in the snapshot, and each shard in the snapshot.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
You might have millions of short videos , with user ratings and limited metadata about the creators or content. Job postings have a much shorter relevant lifetime than movies, so content-based features and metadata about the company, skills, and education requirements will be more important in this case.
If you’re a mystery lover, I’m sure you’ve read that classic tale: Sherlock Holmes and the Case of the Deceptive Data, and you know how a metadata catalog was a key plot element. Maybe they have different definitions of conversions, which would certainly lead to metrics that don’t match up. Enter the metadata catalog.
In Part 2 of this series, we discussed how to enable AWS Glue job observability metrics and integrate them with Grafana for real-time monitoring. In this post, we explore how to connect QuickSight to Amazon CloudWatch metrics and build graphs to uncover trends in AWS Glue job observability metrics.
From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. The data in the central data warehouse in Amazon Redshift is then processed for analytical needs and the metadata is shared to the consumers through Amazon DataZone. This process is shown in the following figure.
The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products. A data portal for consumers to discover data products and access associated metadata. Subscription workflows that simplify access management to the data products.
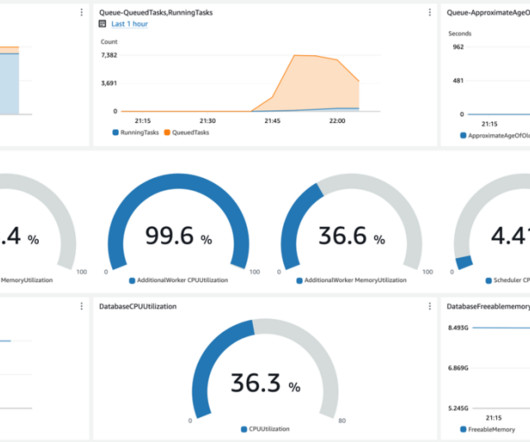
In this post, we explore how to deploy Amazon CloudWatch metrics using an AWS CloudFormation template to monitor an OpenSearch Service domain’s storage and shard skew. This allows write access to CloudWatch metrics and access to the CloudWatch log group and OpenSearch APIs. An OpenSearch Service domain. Choose Next.
Solution overview The MSK clusters in Hydro are configured with a PER_TOPIC_PER_BROKER level of monitoring, which provides metrics at the broker and topic levels. These metrics help us determine the attributes of the cluster usage effectively. We then match these attributes to the relevant MSK metrics available.
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data fabric Metadata-rich integration layer across distributed systems. Implementation complexity, relies on robust metadata management.
They realized that the search results would probably not provide an answer to my question, but the results would simply list websites that included my words on the page or in the metadata tags: “Texas”, “Cows”, “How”, etc. The BI team may be focused on KPIs, forecasts, trends, and decision-support insights.
reduces the Amazon DynamoDB cost associated with KCL by optimizing read operations on the DynamoDB table storing metadata. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints. Other benefits in KCL 3.0 In addition to the stream processing cost savings, KCL 3.0 Key checklists when you choose to use KCL 3.0
In a previous post , we noted some key attributes that distinguish a machine learning project: Unlike traditional software where the goal is to meet a functional specification, in ML the goal is to optimize a metric. Metadata and artifacts needed for a full audit trail.
Metadata is at the heart of every report, dashboard, data warehouse, visualization, and anything else the BI team produces. Without an understanding of the organization’s metadata, the BI team can’t match the data from multiple sources to produce a single view of the business. Money Loser #1: Manual Data Discovery.
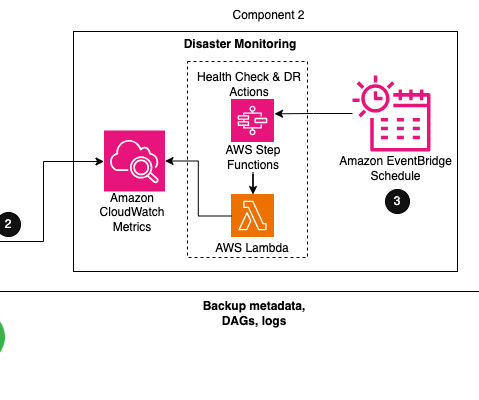
Backup and restore architecture The backup and restore strategy involves periodically backing up Amazon MWAA metadata to Amazon Simple Storage Service (Amazon S3) buckets in the primary Region. The pipeline includes a DAG deployed to the DAGs S3 bucket, which performs backup of your Airflow metadata. The steps are as follows: [1.a]
Recall the following key attributes of a machine learning project: Unlike traditional software where the goal is to meet a functional specification , in ML the goal is to optimize a metric. Metadata and artifacts needed for audits: as an example, the output from the components of MLflow will be very pertinent for audits.
Running Apache Airflow at scale puts proportionally greater load on the Airflow metadata database, sometimes leading to CPU and memory issues on the underlying Amazon Relational Database Service (Amazon RDS) cluster. A resource-starved metadata database may lead to dropped connections from your workers, failing tasks prematurely.
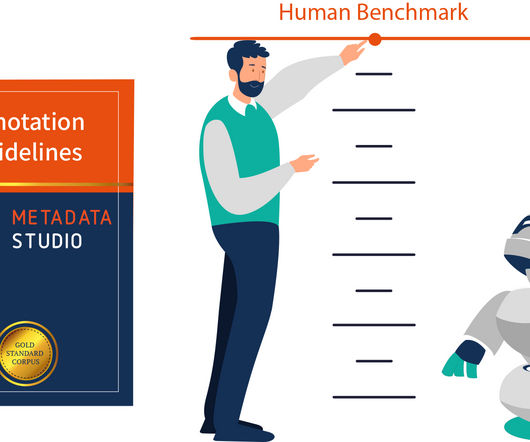
You’ll also be able to establish an inter-annotator agreement (IAA) metric. In order to empower enterprises to turn their static documents into actionable data, we’ve developed Ontotext Metadata Studio – an all-in-one environment facilitating the creation, evaluation and improvement of the quality of text analytics services.
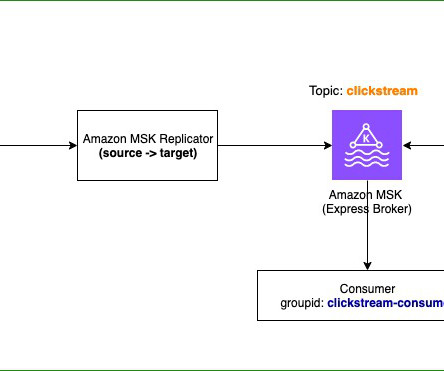
However, you can use Amazon MSK Replicator to copy all data and metadata from your existing MSK cluster to a new cluster comprising of Express brokers. MSK Replicator also replicates Kafka metadata , including topic configurations, access control lists (ACLs), and consumer group offsets. The MessageLag metric should come down to 0.
Near-real-time streaming analytics captures the value of operational data and metrics to provide new insights to create business opportunities. These metrics help agents improve their call handle time and also reallocate agents across organizations to handle pending calls in the queue.
Within Airflow, the metadata database is a core component storing configuration variables, roles, permissions, and DAG run histories. A healthy metadata database is therefore critical for your Airflow environment. The third component is for creating and storing backups of all configurations and metadata that is required to restore.
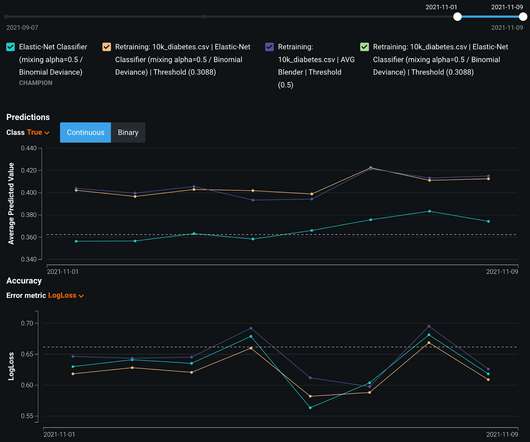
This also shows how the models compare on standard performance metrics and informative visualizations like Dual Lift. With DataRobot AI Cloud, you can see predicted values and accuracy for various metrics for the Champion as well as any Challenger models.]. Model Observability with Custom Metrics.
Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance. The Glue Data Catalog monitors tables daily, removes snapshots from table metadata, and removes the data files and orphan files that are no longer needed.
Alation is pleased to be named a dbt Metrics Partner and to announce the start of a partnership with dbt, which will bring dbt data into the Alation data catalog. Yet every dbt transformation contains vital metadata that is not captured – until now. Yet every dbt transformation contains vital metadata that is not captured – until now.
Metadata enrichment is about scaling the onboarding of new data into a governed data landscape by taking data and applying the appropriate business terms, data classes and quality assessments so it can be discovered, governed and utilized effectively. With public API you can now manage metadata enrichment from external tools and workflows.
It’s important to realize that we need visibility into lineage and relationships between all data and data-related assets, including business terms, metric definitions, policies, quality rules, access controls, algorithms, etc. Active metadata will play a critical role in automating such updates as they arise. Why Focus on Lineage?
Monitoring Job Metadata. Figure 7 shows how the DataKitchen DataOps Platform helps to keep track of all the instances of a job being submitted and its metadata. Figure 7: the DataKitchen DataOps Platform keeps track of all the instances of a job being submitted and its metadata.
The AWS Glue Data Catalog is a metastore of the location, schema, and runtime metrics of your data. AWS Glue Data Catalog stores information as metadata tables, where each table specifies a single data store. Running the crawler on a schedule updates AWS Glue Data Catalog with new partitions and metadata. Save and run the job.
New sensors are likely to be more precise and more accurate, customer support requests will be about newer versions of your products, or you’ll get more metadata about new prospects from their online footprint. Missing trends Cleaning old and new data in the same way can lead to other problems.
One of the keys for our success was really focusing that effort on what our key business initiatives were and what sorts of metrics mattered most to our customers. Chapin also mentioned that measuring cycle time and benchmarking metrics upfront was absolutely critical. “It GE formed its Digital League to create a data culture.
Without the right metadata and documentation, data consumers overlook valuable datasets relevant to their use case or spend more time going back and forth with data producers to understand the data and its relevance for their use case—or worse, misuse the data for a purpose it was not intended for.
Moreover, advanced metrics like Percentage Regional Sales Growth can provide nuanced insights into business performance. Vendor-specific offerings may provide some degree of data process error monitoring in Data in Place, focusing on data orchestration tools and logs, metrics, and status reports.
Apache Iceberg manages these schema changes in a backward-compatible way through its innovative metadata table evolution architecture. With Lake Formation, you can manage fine-grained access control for your data lake data on Amazon S3 and its metadata in the Data Catalog. Iceberg maintains the table state in metadata files.
The importance of metadata. Metadata is best defined as data that characterizes data. Metadata provides the who, what, where, when, why and how of that information. When companies have a properly engineered process to create, store and manage metadata, it benefits all focus areas of the business. ORDER BY SCHEDULED_TIME.
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. connection testing, metadata retrieval, and data preview.
This feature provides users the ability to explore metrics with natural language. Tableau Pulse will then send insights for that metric directly to the executive’s preferred communications platform: Slack, email, mobile device, etc. Metrics Bootstrapping. Metric Goals.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content