This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Generative AI models can translate natural language questions into valid SQL queries, a capability known as text-to-SQL generation.
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machine learning models from malicious actors. Like many others, I’ve known for some time that machine learning models themselves could pose security risks. This is like a denial-of-service (DOS) attack on your model itself.
We will explore Icebergs concurrency model, examine common conflict scenarios, and provide practical implementation patterns of both automatic retry mechanisms and situations requiring custom conflict resolution logic for building resilient data pipelines. Generate new metadata files. Commit the metadata files to the catalog.
And yeah, the real-world relationships among the entities represented in the data had to be fudged a bit to fit in the counterintuitive model of tabular data, but, in trade, you get reliability and speed. This is a graph of millions of edges and vertices – in enterprise data management terms it is a giant piece of master/reference data.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats. For more examples and references to other posts, refer to the following GitHub repository. This post is one of multiple posts about XTable on AWS.
Generative AI models are trained on large repositories of information and media. They are then able to take in prompts and produce outputs based on the statistical weights of the pretrained models of those corpora. In essence, the latest O’Reilly Answers release is an assembly line of LLM workers.
Even for experienced developers and data scientists, the process of developing a model could involve stringing together many steps from many packages, in ways that might not be as elegant or efficient as one might like. the experience is still rooted in the same goal: simple efficiency for the whole model development lifecycle.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. Refer to Service Quotas for more details.
Users discuss how they are putting erwin’s data modeling, enterprise architecture, business process modeling, and data intelligences solutions to work. IT Central Station members using erwin solutions are realizing the benefits of enterprise modeling and data intelligence. Data Modeling with erwin Data Modeler.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Lakehouse allows you to use preferred analytics engines and AI models of your choice with consistent governance across all your data.
The book is awesome, an absolute must-have reference volume, and it is free (for now, downloadable from Neo4j ). And this: perhaps the most powerful node in a graph model for real-world use cases might be “context”. How does one express “context” in a data model? Graph Algorithms book.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. There is no GitHub for data, though we are starting to see version control projects for machine learning models, such as DVC. Automation is more than model building. Toward a sustainable ML practice.
Additionally, customers adopting a federated deployment model find it challenging to provide isolated environments for different teams or departments, and at the same time optimize cost. Refer to Amazon Managed Workflows for Apache Airflow Pricing for rates and more details. The introduction of mw1.micro
Understanding the benefits of data modeling is more important than ever. Data modeling is the process of creating a data model to communicate data requirements, documenting data structures and entity types. In this post: What Is a Data Model? Why Is Data Modeling Important? What’s the Best Data Modeling Tool?
Instead of writing code with hard-coded algorithms and rules that always behave in a predictable manner, ML engineers collect a large number of examples of input and output pairs and use them as training data for their models. The model is produced by code, but it isn’t code; it’s an artifact of the code and the training data.
It’s important to understand that ChatGPT is not actually a language model. It’s a convenient user interface built around one specific language model, GPT-3.5, is one of a class of language models that are sometimes called “large language models” (LLMs)—though that term isn’t very helpful. with specialized training.
As a producer, you can also monetize your data through the subscription model using AWS Data Exchange. To achieve this, they plan to use machine learning (ML) models to extract insights from data. Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products.
This enables companies to directly access key metadata (tags, governance policies, and data quality indicators) from over 100 data sources in Data Cloud, it said. Additional to that, we are also allowing the metadata inside of Alation to be read into these agents.”
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. SageMaker simplifies the discovery, governance, and collaboration for data and AI across your lakehouse, AI models, and applications.
Part Two of the Digital Transformation Journey … In our last blog on driving digital transformation , we explored how enterprise architecture (EA) and business process (BP) modeling are pivotal factors in a viable digital transformation strategy. Ultimately, data is the foundation of the new digital business model.
While these will remain big data governance trends for 2020, we anticipate organizations will finally begin tapping into the true value of data as the foundation of the digital business model. Data Modeling: Drive Business Value and Underpin Governance with an Enterprise Data Model.
Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose. While the digital age has been successful in prompting innovation far and wide, it has also facilitated what is referred to as the “data crisis” – low-quality data. 2 – Data profiling.
Application data architect: The application data architect designs and implements data models for specific software applications. Data scientists are experts in applying computer science, mathematics, and statistics to building models.
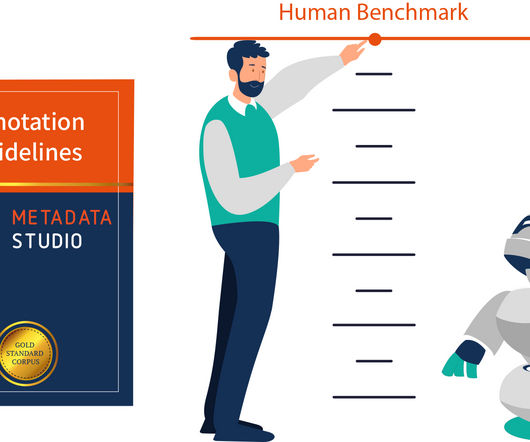
This data can then be easily analyzed to provide insights or used to train machine learning models. Ontotext’s approach is to optimize models and algorithms through human contribution and benchmarking in order to create better and more accurate AI. What Are The Benefits Of Using Ontotext Metadata Studio?
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable. A metadata layer helps build the relationship between the raw data and AI extracted output.
Also, a data model that allows table truncations at a regular frequency (for example, every 15 seconds) to store only relevant data in tables can cause locking and performance issues. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day.
Q: Is data modeling cool again? Amidst the evolving technological landscape, one constant remains despite the ongoing attacks from nay-sayers: the importance of data modeling as a foundational step in the delivery of data to these forward-thinking organizations. A: It always was and is getting cooler!!
One of its pillars are ontologies that represent explicit formal conceptual models, used to describe semantically both unstructured content and databases. There are more than 80 million pages with semantic, machine interpretable metadata , according to the Schema.org standard. Take this restaurant, for example.
The zero-copy pattern helps customers map the data from external platforms into the Salesforce metadatamodel, providing a virtual object definition for that object. “It When released, this will extend zero-copy data access to any open data lake or lakehouse that stores data in Iceberg or can provide Iceberg metadata for its table.
The Data Governance Institute defines it as “a system of decision rights and accountabilities for information-related processes, executed according to agreed-upon models which describe who can take what actions with what information, and when, under what circumstances, using what methods.”
Introduction to OpenLineage compatible data lineage The need to capture data lineage consistently across various analytical services and combine them into a unified object model is key in uncovering insights from the lineage artifact. The following diagram illustrates an example of the Amazon DataZone lineage data model.
’ It assigns unique identifiers to each data item—referred to as ‘payloads’—related to each event. Payload DJs facilitate capturing metadata, lineage, and test results at each phase, enhancing tracking efficiency and reducing the risk of data loss.
Working with large language models (LLMs) for enterprise use cases requires the implementation of quality and privacy considerations to drive responsible AI. Enterprises are doing this by using proprietary data with approaches like Retrieval Augmented Generation (RAG), fine-tuning, and continued pre-training with foundation models.
Gartner predicts that “By 2020, 50% of information governance initiatives will be enacted with policies based on metadata alone.”. Magic Quadrant for Metadata Management Solutions , Guido de Simoni and Roxane Edjlali, August 10, 2017. Metadata management no longer refers to a static technical repository.
Metadata management is essential to becoming a data-driven organization and reaping the competitive advantage your organization’s data offers. Gartner refers to metadata as data that is used to enhance the usability, comprehension, utility or functionality of any other data point. How the data has changed.
Backup and restore architecture The backup and restore strategy involves periodically backing up Amazon MWAA metadata to Amazon Simple Storage Service (Amazon S3) buckets in the primary Region. Refer to the detailed deployment steps in the README file to deploy it in your own accounts. The steps are as follows: [1.a]
To learn more about this process, refer to Enabling SAML 2.0 In the Create function pane, provide the following information: For Select a template , choose v2 Programming Model. For Programming Model , choose the HTTP trigger template. From there, the user can access the Redshift Query Editor V2. choose Next.
After developing a machine learning model, you need a place to run your model and serve predictions. If your company is in the early stage of its AI journey or has budget constraints, you may struggle to find a deployment system for your model. Also, a column in the dataset indicates if each flight had arrived on time or late.
Based on the study of the evaluation criteria of Gartner Magic Quadrant for analytics and Business Intelligence Platforms, I have summarized top 10 key features of BI tools for your reference. Metadata management. Overall, as users’ data sources become more extensive, their preferences for BI are changing. Analytics dashboards.
Addressing the Key Mandates of a Modern Model Risk Management Framework (MRM) When Leveraging Machine Learning . The regulatory guidance presented in these documents laid the foundation for evaluating and managing model risk for financial institutions across the United States.
We also detail how the feature works and what criteria was applied for the model and prompt selection while building on Amazon Bedrock. Solution overview The AI recommendations feature in Amazon DataZone was built on Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models.
Large language models (LLMs) are becoming increasing popular, with new use cases constantly being explored. This is where model fine-tuning can help. Before you can fine-tune a model, you need to find a task-specific dataset. Next, we use Amazon SageMaker JumpStart to fine-tune the Llama 2 model with the preprocessed dataset.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content