This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Although LLMs can generate syntactically correct SQL queries, they still need the table metadata for writing accurate SQL query.
We will also cover the pattern with automatic compaction through AWS Glue Data Catalog table optimization. Consider a streaming pipeline ingesting real-time event data while a scheduled compaction job runs to optimize file sizes. Load the tables latest metadata, and determine which metadata version is used as the base for the update.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
The adoption of open table formats is a crucial consideration for organizations looking to optimize their data management practices and extract maximum value from their data. For more details, refer to Iceberg Release 1.6.1. An Iceberg table’s metadata stores a history of snapshots, which are updated with each transaction.
Relational databases benefit from decades of tweaks and optimizations to deliver performance. This is a graph of millions of edges and vertices – in enterprise data management terms it is a giant piece of master/reference data. Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter.
Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. For a more in-depth description of these phases please refer to Impala: A Modern, Open-Source SQL Engine for Hadoop. Query Planner Design.
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance.
Customers maintain multiple MWAA environments to separate development stages, optimize resources, manage versions, enhance security, ensure redundancy, customize settings, improve scalability, and facilitate experimentation. Refer to Amazon Managed Workflows for Apache Airflow Pricing for rates and more details.
First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead. We have enhanced autonomics algorithms to generate and implement smarter and quicker optimal data layout recommendations for distribution and sort keys, further optimizing performance.
Whether youre a data analyst seeking a specific metric or a data steward validating metadata compliance, this update delivers a more precise, governed, and intuitive search experience. This supports data hygiene and infrastructure cost optimization.
This workload imbalance presents a challenge for customers seeking to optimize their resource utilization and stream processing efficiency. reduces the Amazon DynamoDB cost associated with KCL by optimizing read operations on the DynamoDB table storing metadata. x benefits, refer to Use features of the AWS SDK for Java 2.x.
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations.
Starting today, the Athena SQL engine uses a cost-based optimizer (CBO), a new feature that uses table and column statistics stored in the AWS Glue Data Catalog as part of the table’s metadata. Let’s discuss some of the cost-based optimization techniques that contributed to improved query performance.
BladeBridge provides a configurable framework to seamlessly convert legacy metadata and code into more modern services such as Amazon Redshift. For more details, refer to the BladeBridge Analyzer Demo. Refer to this BladeBridge documentation to get more details on SQL and expression conversion.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
Organizations with particularly deep data stores might need a data catalog with advanced capabilities, such as automated metadata harvesting to speed up the data preparation process. The most optimal and streamlined way to achieve this is by using a data catalog, which can provide a first stop for users ahead of working in BI platforms.
We won’t be writing code to optimize scheduling in a manufacturing plant; we’ll be training ML algorithms to find optimum performance based on historical data. With machine learning, the challenge isn’t writing the code; the algorithms are implemented in a number of well-known and highly optimized libraries.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. As stated earlier, the first step involves data ingestion.
Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table. Get table data and metadata for this user to see how Lake Formation permissions are enforced and so the two users can see different data (on the Authorized Data tab).
When you use Trino on Amazon EMR or Athena, you get the latest open source community innovations along with proprietary, AWS developed optimizations. and Athena engine version 2, AWS has been developing query plan and engine behavior optimizations that improve query performance on Trino. Starting from Amazon EMR 6.8.0
For instructions, refer to How to Set Up a MongoDB Cluster. Choose the table to view the schema and other metadata. Conclusion In this post, we showed how to set up an AWS Glue crawler to crawl over a MongoDB Atlas collection, gathering metadata and creating table records in the AWS Glue Data Catalog.
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. Some of the queries in our benchmark experienced up to 12x speed up.
Metadata management performs a critical role within the modern data management stack. However, as data volumes continue to grow, manual approaches to metadata management are sub-optimal and can result in missed opportunities. This puts into perspective the role of active metadata management. Improve data discovery.
Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. This metadata file is later used to read source file names during processing into the staging layer. These files follow the same naming pattern, with a daily system-generated timestamp appended to each file name.
Although we don’t cover optimizing your jobs for costs in this post, you can refer to Monitor and optimize cost on AWS Glue for Apache Spark to learn how to fine-tune your AWS Glue jobs for performance, efficiency ,and cost-optimization. Let’s dive in! If the tables don’t exist, Athena creates them.
Each storage format implements this functionality in slightly different ways; for a comparison, refer to Choosing an open table format for your transactional data lake on AWS. For more information, refer to Amazon S3: Allows read and write access to objects in an S3 Bucket.
Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose. While the digital age has been successful in prompting innovation far and wide, it has also facilitated what is referred to as the “data crisis” – low-quality data. 2 – Data profiling.
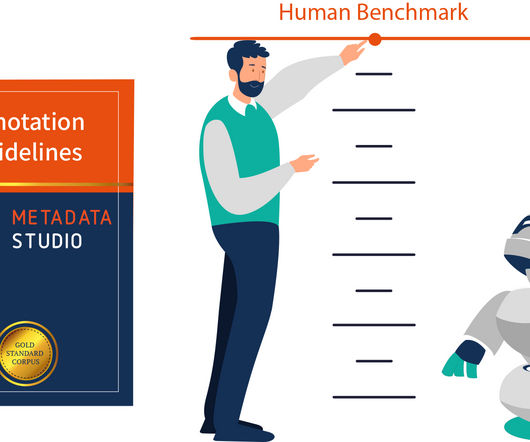
Ontotext’s approach is to optimize models and algorithms through human contribution and benchmarking in order to create better and more accurate AI. To be able to annotate the specified content consistently and unambiguously, these experts usually follow a set of specific conventions, which are referred to as “annotation guidelines”.
They understand data modeling, including conceptualization and database optimization, and demonstrate a commitment to continuing education. According to Dataversity , good data architects have a solid understanding of the cloud, databases, and the applications and programs used by those databases.
We group the new capabilities into four categories: Discover and secure Connect with data sharing Scale and optimize Audit and monitor Let’s dive deeper and discuss the new capabilities introduced in 2023. To learn more about DataZone, refer to the User Guide. This enhancement simplifies many use cases to avoid metadata duplication.
While data management has become a common term for the discipline, it is sometimes referred to as data resource management or enterprise information management (EIM). Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata.
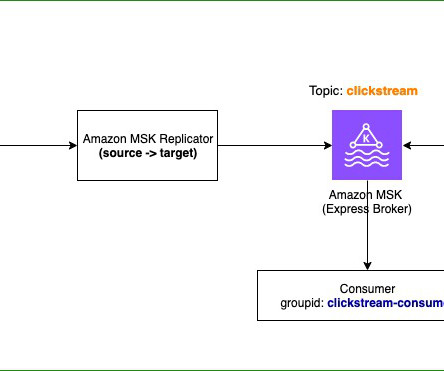
To learn more about Express brokers, refer to Introducing Express brokers for Amazon MSK to deliver high throughput and faster scaling for your Kafka clusters. However, you can use Amazon MSK Replicator to copy all data and metadata from your existing MSK cluster to a new cluster comprising of Express brokers.
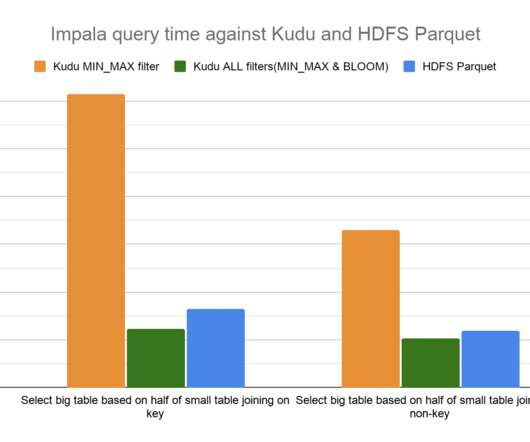
Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. See the references section below for details on the table schema, loading process, and queries that were run.
Despite these capabilities, data lakes are not databases, and object storage does not provide support for ACID processing semantics, which you may require to effectively optimize and manage your data at scale across hundreds or thousands of users using a multitude of different technologies.
Through their unique position in ports, at sea, and on roads, they optimize global cargo flows and create sustainable customer value. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views. An AWS Glue job (metadata exporter) runs daily on the source account.
Running Apache Airflow at scale puts proportionally greater load on the Airflow metadata database, sometimes leading to CPU and memory issues on the underlying Amazon Relational Database Service (Amazon RDS) cluster. A resource-starved metadata database may lead to dropped connections from your workers, failing tasks prematurely.
KGs bring the Semantic Web paradigm to the enterprises, by introducing semantic metadata to drive data management and content management to new levels of efficiency and breaking silos to let them synergize with various forms of knowledge management. Take this restaurant, for example. used across different systems in the enterprise.
BMW Group uses 4,500 AWS Cloud accounts across the entire organization but is faced with the challenge of reducing unnecessary costs, optimizing spend, and having a central place to monitor costs. For more information on this foundation, refer to A Detailed Overview of the Cost Intelligence Dashboard.
Many of these go slightly (but not very far) beyond your initial expectations: you can ask it to generate a list of terms for search engine optimization, you can ask it to generate a reading list on topics that you’re interested in. In the second, “it” refers to the pitcher. It was not optimized to provide correct responses.
In other words, using metadata about data science work to generate code. SQL optimization provides helpful analogies, given how SQL queries get translated into query graphs internally , then the real smarts of a SQL engine work over that graph. On deck this time ’round the Moon: program synthesis. SQL and Spark.
The Iceberg specification allows seamless table evolution such as schema and partition evolution, and its design is optimized for usage on Amazon S3. Iceberg stores the metadata pointer for all the metadata files. For more details on Iceberg format versions, refer to Format Versioning.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
The individual pieces of data within these streams are often referred to as records. Store large records in Amazon S3 with a reference in Kinesis Data Streams A useful approach for storing large records involves utilizing an alternative storage solution while employing a reference within Kinesis Data Streams.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content