This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now With Actionable, Automatic, Data Quality Dashboards Imagine a tool that can point at any dataset, learn from your data, screen for typical data quality issues, and then automatically generate and perform powerful tests, analyzing and scoring your data to pinpoint issues before they snowball. DataOps just got more intelligent.
Writing SQL queries requires not just remembering the SQL syntax rules, but also knowledge of the tables metadata, which is data about table schemas, relationships among the tables, and possible column values. Although LLMs can generate syntactically correct SQL queries, they still need the table metadata for writing accurate SQL query.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
Customers maintain multiple MWAA environments to separate development stages, optimize resources, manage versions, enhance security, ensure redundancy, customize settings, improve scalability, and facilitate experimentation. micro, remember to monitor its performance using the recommended metrics to maintain optimal operation.
Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. Query optimization in databases is a long standing area of research, with much emphasis on finding near optimal query plans.
Amazon Q generative SQL for Amazon Redshift uses generative AI to analyze user intent, query patterns, and schema metadata to identify common SQL query patterns directly within Amazon Redshift, accelerating the query authoring process for users and reducing the time required to derive actionable data insights.
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations. with Spark 3.3.2,
We won’t be writing code to optimize scheduling in a manufacturing plant; we’ll be training ML algorithms to find optimum performance based on historical data. have a large body of tools to choose from: IDEs, CI/CD tools, automated testing tools, and so on. If humans are no longer needed to write enterprise applications, what do we do?
Starting today, the Athena SQL engine uses a cost-based optimizer (CBO), a new feature that uses table and column statistics stored in the AWS Glue Data Catalog as part of the table’s metadata. Let’s discuss some of the cost-based optimization techniques that contributed to improved query performance.
In a previous post , we noted some key attributes that distinguish a machine learning project: Unlike traditional software where the goal is to meet a functional specification, in ML the goal is to optimize a metric. A catalog or a database that lists models, including when they were tested, trained, and deployed.
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data fabric Metadata-rich integration layer across distributed systems. Implementation complexity, relies on robust metadata management.
As the use of Hydro grows within REA, it’s crucial to perform capacity planning to meet user demands while maintaining optimal performance and cost-efficiency. To address this, we used the AWS performance testing framework for Apache Kafka to evaluate the theoretical performance limits.
First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead. We have enhanced autonomics algorithms to generate and implement smarter and quicker optimal data layout recommendations for distribution and sort keys, further optimizing performance.
For decades, data modeling has been the optimal way to design and deploy new relational databases with high-quality data sources and support application development. That’s because it’s the best way to visualize metadata , and metadata is now the heart of enterprise data management and data governance/ intelligence efforts.
Recall the following key attributes of a machine learning project: Unlike traditional software where the goal is to meet a functional specification , in ML the goal is to optimize a metric. A catalog or a database that lists models, including when they were tested, trained, and deployed.
Cloudinary is a cloud-based media management platform that provides a comprehensive set of tools and services for managing, optimizing, and delivering images, videos, and other media assets on websites and mobile applications. This concept makes Iceberg extremely versatile.
With all these diverse metadata sources, it is difficult to understand the complicated web they form much less get a simple visual flow of data lineage and impact analysis. The metadata-driven suite automatically finds, models, ingests, catalogs and governs cloud data assets. GDPR, CCPA, HIPAA, SOX, PIC DSS).
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
Data Pipeline Observability: Optimizes pipelines by monitoring data quality, detecting issues, tracing data lineage, and identifying anomalies using live and historical metadata. This capability includes monitoring, logging, and business-rule detection.
Data Governance/Catalog (Metadata management) Workflow – Alation, Collibra, Wikis. Tools influence their optimal iteration cycle time, e.g., months/weeks/days. Observability – Testing inputs, outputs, and business logic at each stage of the data analytics pipeline. Tools determine their approach to solving problems.
You can now test the newly created application by running the following command: npm run dev By default, the application is available on port 5173 on your local machine. Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table.
S3 Tables are specifically optimized for analytics workloads, resulting in up to 3 times faster query throughput and up to 10 times higher transactions per second compared to self-managed tables. These metadata tables are stored in S3 Tables, the new S3 storage offering optimized for tabular data.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
L1 is usually the raw, unprocessed data ingested directly from various sources; L2 is an intermediate layer featuring data that has undergone some form of transformation or cleaning; and L3 contains highly processed, optimized, and typically ready for analytics and decision-making processes.
Everything is being tested, and then the campaigns that succeed get more money put into them, while the others aren’t repeated. This methodology of “test, look at the data, adjust” is at the heart and soul of business intelligence. Your Chance: Want to try a professional BI analytics software? Let’s see it with a real-world example.
Running Apache Airflow at scale puts proportionally greater load on the Airflow metadata database, sometimes leading to CPU and memory issues on the underlying Amazon Relational Database Service (Amazon RDS) cluster. A resource-starved metadata database may lead to dropped connections from your workers, failing tasks prematurely.
Many of these go slightly (but not very far) beyond your initial expectations: you can ask it to generate a list of terms for search engine optimization, you can ask it to generate a reading list on topics that you’re interested in. It was not optimized to provide correct responses. It has helped to write a book.
A catalog or a database that lists models, including when they were tested, trained, and deployed. Metadata and artifacts needed for audits. In particular, auditing and testing machine learning systems will rely on many of the tools I’ve described above. There are real, not just theoretical, risks and considerations.
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. Performance was tested on a Redshift serverless data warehouse with 128 RPU.
We dive into the various optimization techniques AppsFlyer employed, such as partition projection, sorting, parallel query runs, and the use of query result reuse. Additionally, we discuss the thorough testing, monitoring, and rollout process that resulted in a successful transition to the new Athena architecture.
Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. This metadata file is later used to read source file names during processing into the staging layer. These files follow the same naming pattern, with a daily system-generated timestamp appended to each file name.
With its scalability, reliability, and ease of use, Amazon OpenSearch Service helps businesses optimize data-driven decisions and improve operational efficiency. es.amazonaws.com' # e.g. my-test-domain.us-east-1.es.amazonaws.com, Jenkins retrieves JSON files from the GitHub repository and performs validation.
When you use Trino on Amazon EMR or Athena, you get the latest open source community innovations along with proprietary, AWS developed optimizations. and Athena engine version 2, AWS has been developing query plan and engine behavior optimizations that improve query performance on Trino. Starting from Amazon EMR 6.8.0
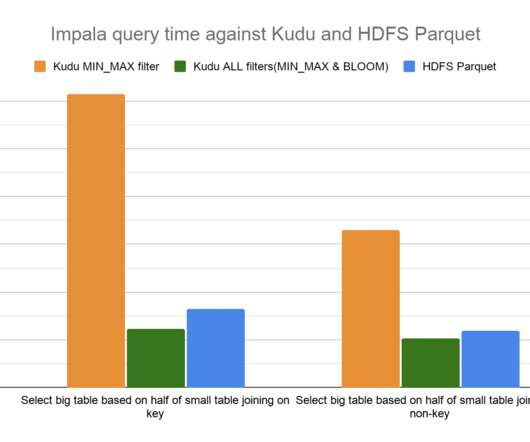
Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. The following test was performed on a 6 node cluster with CDP Runtime 7.1.5. CDP Runtime 7.1.5
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. You're choosing only one metric because you want to optimize it. Testing out a new feature. Identify, hypothesize, test, react. But it is not routine. So, how do we fix this problem?
However, these two processes are essentially distinct, and their testing needs differ in manyways. As enterprises extend their data pipelines, high-quality, automated testing for both transformations and conversions is critical to assuring data integrity, performance, and compliance across many platforms.
By optimizing the various CDP Data Services, including CDW, CDE, and Cloudera Machine Learning (CML) with Iceberg, Cloudera customers can define and manipulate datasets with SQL commands, build complex data pipelines using features like Time Travel operations, and deploy machine learning models built from Iceberg tables. What’s Next.
The Amazon EMR runtime for Apache Spark is a performance-optimized runtime that is 100% API compatible with open source Apache Spark. Amazon EMR on EC2 , Amazon EMR Serverless , Amazon EMR on Amazon EKS , and Amazon EMR on AWS Outposts all use this optimized runtime, which is 4.5 times faster than Apache Spark 3.5.1 and EMR 7.1.
They have dev, test, and production clusters running critical workloads and want to upgrade their clusters to CDP Private Cloud Base. Customer Environment: The customer has three environments: development, test, and production. Test and QA. Test and QA. Let’s take a look at one customer’s upgrade journey. Background: .
Despite these capabilities, data lakes are not databases, and object storage does not provide support for ACID processing semantics, which you may require to effectively optimize and manage your data at scale across hundreds or thousands of users using a multitude of different technologies.
They understand data modeling, including conceptualization and database optimization, and demonstrate a commitment to continuing education. According to Dataversity , good data architects have a solid understanding of the cloud, databases, and the applications and programs used by those databases.
In other words, using metadata about data science work to generate code. SQL optimization provides helpful analogies, given how SQL queries get translated into query graphs internally , then the real smarts of a SQL engine work over that graph. On deck this time ’round the Moon: program synthesis. SQL and Spark.
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. Also known as data validation, integrity refers to the structural testing of data to ensure that the data complies with procedures. Your Chance: Want to test a professional analytics software?
Our goal is to test whether GenAI can handle diverse domains effectively and determine if its a viable tool for domain-specific graph-building tasks. We also experimented with prompt optimization tools, however these experiments did not yield promising results.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content