This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
We want to publish this data to Amazon DataZone as discoverable S3 data. Custom subscription workflow architecture diagram To implement the solution, we complete the following steps: As a data producer, publish an unstructured S3 based data asset as S3ObjectCollectionType to Amazon DataZone.
This article was published as a part of the Data Science Blogathon. Any type of contextual information, like device context, conversational context, and metadata, […]. Any type of contextual information, like device context, conversational context, and metadata, […].
This article was published as a part of the Data Science Blogathon. A centralized location for research and production teams to govern models and experiments by storing metadata throughout the ML model lifecycle. A Metadata Store for MLOps appeared first on Analytics Vidhya. Keeping track of […]. The post Neptune.ai?—?A
Just 20% of organizations publish data provenance and data lineage. These include the basics, such as metadata creation and management, data provenance, data lineage, and other essentials. They’re still struggling with the basics: tagging and labeling data, creating (and managing) metadata, managing unstructured data, etc.
way we package information has a lot to do with metadata. The somewhat conventional metaphor about metadata is the one of the library card. This metaphor has it that books are the data and library cards are the metadata helping us find what we need, want to know more about or even what we don’t know we were looking for.
Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter. To be able to automate these operations and maintain sufficient data quality, enterprises have started implementing the so-called data fabrics , that employ diverse metadata sourced from different systems. Metadata about Relationships Come in Handy.
Metadata has been defined as the who, what, where, when, why, and how of data. Without the context given by metadata, data is just a bunch of numbers and letters. But going on a rampage to define, categorize, and otherwise metadata-ize your data doesn’t necessarily give you the key to the value in your data. Hold on tight!
This need to improve data governance is therefore at the forefront of many AI strategies, as highlighted by the findings of The State of Data Intelligence report published in October 2024 by Quest, which found the top drivers of data governance were improving data quality (42%), security (40%), and analytics (40%).
To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
Will content creators and publishers on the open web ever be directly credited and fairly compensated for their works’ contributions to AI platforms? At the same time, Miso went about an in-depth chunking and metadata-mapping of every book in the O’Reilly catalog to generate enriched vector snippet embeddings of each work.
Whether youre a data analyst seeking a specific metric or a data steward validating metadata compliance, this update delivers a more precise, governed, and intuitive search experience. Refer to the product documentation to learn more about how to set up metadata rules for subscription and publishing workflows.
In 2017, we published “ How Companies Are Putting AI to Work Through Deep Learning ,” a report based on a survey we ran aiming to help leaders better understand how organizations are applying AI through deep learning. Data scientists and data engineers are in demand.
For instance, Domain A will have the flexibility to create data products that can be published to the divisional catalog, while also maintaining the autonomy to develop data products that are exclusively accessible to teams within the domain. A data portal for consumers to discover data products and access associated metadata.
One vehicle might be an annual report, one similar to those that have been published for years by public companies—10ks and 10qs and all those other filings by which stakeholders judge a company’s performance, posture, and potential. And don’t just rattle off project metadata. Such a report has a legacy already, if only a short one.
We automate running queries using Step Functions with Amazon EventBridge schedules, build an AWS Glue Data Catalog on query outputs, and publish dashboards using QuickSight so they automatically refresh with new data. QuickSight is used to query, build visualizations, and publish dashboards using the data from the query results.
In their wisdom, the editors of the book decided that I wrote “too much” So, they correctly shortened my contribution by about half in the final published version of my Foreword for the book. I publish this in its original form in order to capture the essence of my point of view on the power of graph analytics.
Kinesis Data Streams not only offers the flexibility to use many out-of-box integrations to process the data published to the streams, but also provides the capability to build custom stream processing applications that can be deployed on your compute fleet. KCL uses DynamoDB to store metadata such as shard-worker mapping and checkpoints.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
Reading Time: 3 minutes While cleaning up our archive recently, I found an old article published in 1976 about data dictionary/directory systems (DD/DS). Nowadays, we no longer use the term DD/DS, but “data catalog” or simply “metadata system”. It was written by L.
This article was published as a part of the Data Science Blogathon. Introduction The purpose of a data warehouse is to combine multiple sources to generate different insights that help companies make better decisions and forecasting. It consists of historical and commutative data from single or multiple sources.
Business analysts enhance the data with business metadata/glossaries and publish the same as data assets or data products. Users can search for assets in the Amazon DataZone catalog, view the metadata assigned to them, and access the assets. Amazon Athena is used to query, and explore the data.
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data fabric Metadata-rich integration layer across distributed systems. Implementation complexity, relies on robust metadata management.
An Iceberg table’s metadata stores a history of snapshots, which are updated with each transaction. Over time, this creates multiple data files and metadata files as changes accumulate. Additionally, they can impact query performance due to the overhead of handling large amounts of metadata.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machine learning services to streamline the user journey from data to insight.
Organizations with particularly deep data stores might need a data catalog with advanced capabilities, such as automated metadata harvesting to speed up the data preparation process. Three Types of Metadata in a Data Catalog. The metadata provides information about the asset that makes it easier to locate, understand and evaluate.
Solution overview AWS AppSync creates serverless GraphQL and pub/sub APIs that simplify application development through a single endpoint to securely query, update, or publish data. Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table.
erwin positioned as a Leader in Gartner’s “2019 Magic Quadrant for Metadata Management Solutions”. We were excited to announce earlier today that erwin was named as a Leader in the @Gartner _inc “2019 Magic Quadrant for Metadata Management Solutions.”. This graphic was published by Gartner, Inc. GET THE REPORT NOW.
This post describes the process of using the business data catalog resource of Amazon DataZone to publish data assets so theyre discoverable by other accounts. Data publishers : Users in producer AWS accounts. Create the necessary publish project for AWS Glue and Amazon Redshift in the producer account.
Spelling, pronunciation, and examples of usage are included in the dictionary definition of a word, which is a good example of one of the many uses of metadata, namely to provide a definition, description, and context for data. In practice, I haven’t encountered a metadata dictionary that could deliver on that promise.
In a series of follow-up posts, we will review the source code and walkthrough published examples of the Lambda ingestion framework in the AWS Samples GitHub repo. The framework can be modified for use in containers to help address companies that have longer processing times for large files published in Security Lake.
The domain requires a team that creates/updates/runs the domain, and we can’t forget metadata: catalogs, lineage, test results, processing history, etc., …. It’s convenient to publish a set of URLs that provide access to domain-related data and services. Figure 5: Domain interfaces as URLs. How does one get access to a domain?
Unraveling Data Complexities with Metadata Management. Metadata management will be critical to the process for cataloging data via automated scans. Essentially, metadata management is the administration of data that describes other data, with an emphasis on associations and lineage. Data lineage to support impact analysis.
A few years ago, we started publishing articles (see “Related resources” at the end of this post) on the challenges facing data teams as they start taking on more machine learning (ML) projects. Metadata and artifacts needed for audits: as an example, the output from the components of MLflow will be very pertinent for audits.
Metadata enrichment is about scaling the onboarding of new data into a governed data landscape by taking data and applying the appropriate business terms, data classes and quality assessments so it can be discovered, governed and utilized effectively. With public API you can now manage metadata enrichment from external tools and workflows.
The retail team, acting as the data producer, publishes the necessary data assets to Amazon DataZone, allowing you, as a consumer, to discover and subscribe to these assets. Publish data assets – As the data producer from the retail team, you must ingest individual data assets into Amazon DataZone.
It focuses on the key aspect of the solution, which was enabling data providers to automatically publish data assets to Amazon DataZone, which served as the central data mesh for enhanced data discoverability. Data domain producers publish data assets using datasource run to Amazon DataZone in the Central Governance account.
In this blog, we discuss the technical challenges faced by Cargotec in replicating their AWS Glue metadata across AWS accounts, and how they navigated these challenges successfully to enable cross-account data sharing. Solution overview Cargotec required a single catalog per account that contained metadata from their other AWS accounts.
It also offers reference implementation of an object model to persist metadata along with integration to major data and analytics tools. Lineage form types – Form types, or facets , provide additional metadata or context about lineage entities or events, enabling richer and more descriptive lineage information.
Aptly named, metadata management is the process in which BI and Analytics teams manage metadata, which is the data that describes other data. In other words, data is the context and metadata is the content. Without metadata, BI teams are unable to understand the data’s full story. It is published by Robert S.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. You can also create new data lake tables using Redshift Managed Storage (RMS) as a native storage option.
Instead of a central data platform team with a data warehouse or data lake serving as the clearinghouse of all data across the company, a data mesh architecture encourages distributed ownership of data by data producers who publish and curate their data as products, which can then be discovered, requested, and used by data consumers.
An Amazon DataZone domain contains an associated business data catalog for search and discovery, a set of metadata definitions to decorate the data assets that are used for discovery purposes, and data projects with integrated analytics and ML tools for users and groups to consume and publish data assets.
Now that pulling stakeholders into a room has been disrupted … what if we could use this as 40 opportunities to update the metadata PER DAY? Overcoming the 80/20 Rule with Micro Governance for Metadata. Companies like Twitter, Shopify and Box have announced that they are moving to a permanent work-from-home status as their new normal.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















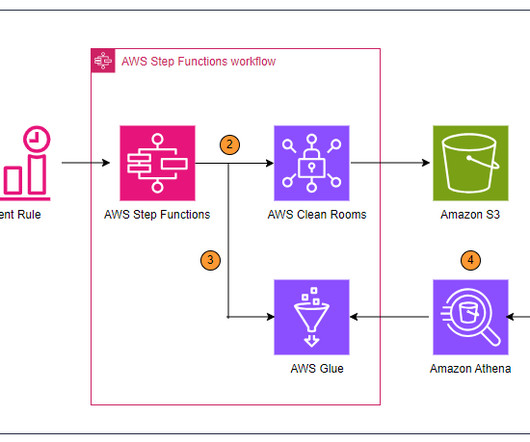



































Let's personalize your content