This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
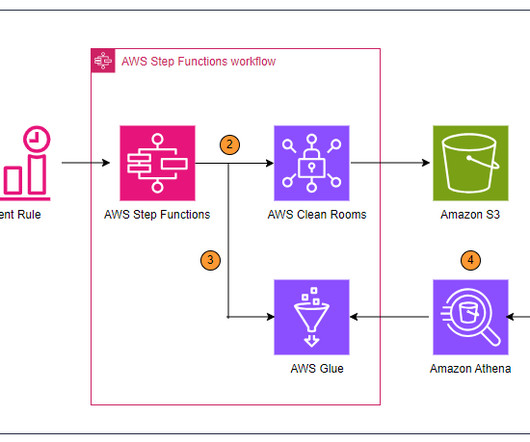
We want to publish this data to Amazon DataZone as discoverable S3 data. Custom subscription workflow architecture diagram To implement the solution, we complete the following steps: As a data producer, publish an unstructured S3 based data asset as S3ObjectCollectionType to Amazon DataZone.
Will content creators and publishers on the open web ever be directly credited and fairly compensated for their works’ contributions to AI platforms? At the same time, Miso went about an in-depth chunking and metadata-mapping of every book in the O’Reilly catalog to generate enriched vector snippet embeddings of each work.
The domain requires a team that creates/updates/runs the domain, and we can’t forget metadata: catalogs, lineage, test results, processing history, etc., …. It can orchestrate a hierarchy of directed acyclic graphs ( DAGS ) that span domains and integrates testing at each step of processing.
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data fabric Metadata-rich integration layer across distributed systems. Implementation complexity, relies on robust metadata management.
We automate running queries using Step Functions with Amazon EventBridge schedules, build an AWS Glue Data Catalog on query outputs, and publish dashboards using QuickSight so they automatically refresh with new data. QuickSight is used to query, build visualizations, and publish dashboards using the data from the query results.
Collaborating closely with our partners, we have tested and validated Amazon DataZone authentication via the Athena JDBC connection, providing an intuitive and secure connection experience for users. Publish data assets – As the data producer from the retail team, you must ingest individual data assets into Amazon DataZone.
Solution overview AWS AppSync creates serverless GraphQL and pub/sub APIs that simplify application development through a single endpoint to securely query, update, or publish data. Unfiltered Table Metadata This tab displays the response of the AWS Glue API GetUnfilteredTableMetadata policies for the selected table.
There are no automated tests , so errors frequently pass through the pipeline. There is no process to spin up an isolated dev environment to quickly add a feature, test it with actual data and deploy it to production. The automated orchestration published the data to an AWS S3 Data Lake. Adding Tests to Reduce Stress.
We’re excited to announce a new feature in Amazon DataZone that offers enhanced metadata governance for your subscription approval process. With this update, domain owners can define and enforce metadata requirements for data consumers when they request access to data assets. Key benefits The feature benefits multiple stakeholders.
A few years ago, we started publishing articles (see “Related resources” at the end of this post) on the challenges facing data teams as they start taking on more machine learning (ML) projects. A catalog or a database that lists models, including when they were tested, trained, and deployed.
I can also ask for a reading list about plagues in 16th century England, algorithms for testing prime numbers, or anything else. The response to the second question is a piece of software that could take the place of something a previous author has written and published on GitHub. But Google has the best search engine in the world.
Hydro is powered by Amazon MSK and other tools with which teams can move, transform, and publish data at low latency using event-driven architectures. To address this, we used the AWS performance testing framework for Apache Kafka to evaluate the theoretical performance limits.
It focuses on the key aspect of the solution, which was enabling data providers to automatically publish data assets to Amazon DataZone, which served as the central data mesh for enhanced data discoverability. Data domain producers publish data assets using datasource run to Amazon DataZone in the Central Governance account.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and test data sources. The SageMaker Lakehouse data connection testing capability boosts your confidence in established connections. Now, lets start running queries on your notebook. Choose Run all.
To be clear, Hadoop code will display lots of exceptions in debug mode because it tests environment settings and looks for things that aren’t provisioned in your Lambda environment, like a Hadoop metrics collector. Your JAR file options are: Info-level settings for the Lambda code (default deployment) – lambda-s3-objecthandler-0.2.8.jar
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads.
Metadata enrichment is about scaling the onboarding of new data into a governed data landscape by taking data and applying the appropriate business terms, data classes and quality assessments so it can be discovered, governed and utilized effectively.
This has serious implications for software testing, versioning, deployment, and other core development processes. You might establish a baseline by replicating collaborative filtering models published by teams that built recommenders for MovieLens, Netflix, and Amazon. But this is a best-case scenario, and it’s not typical.
It also offers reference implementation of an object model to persist metadata along with integration to major data and analytics tools. Lineage form types – Form types, or facets , provide additional metadata or context about lineage entities or events, enabling richer and more descriptive lineage information.
Companies such as Adobe , Expedia , LinkedIn , Tencent , and Netflix have published blogs about their Apache Iceberg adoption for processing their large scale analytics datasets. . In CDP we enable Iceberg tables side-by-side with the Hive table types, both of which are part of our SDX metadata and security framework. What’s Next.
What’s covered in this post is already implemented and available in the Guidance for Connecting Data Products with Amazon DataZone solution, published in the AWS Solutions Library. It offers AWS Glue connections and AWS Glue crawlers as a means to capture the data asset’s metadata easily from their source database and keep it up to date.
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. connection testing, metadata retrieval, and data preview.
Datasets used for generating insights are curated using materialized views inside the database and published for business intelligence (BI) reporting. The second streaming data source constitutes metadata information about the call center organization and agents that gets refreshed throughout the day. We use two datasets in this post.
It involves: Reviewing data in detail Comparing and contrasting the data to its own metadata Running statistical models Data quality reports. Also known as data validation, integrity refers to the structural testing of data to ensure that the data complies with procedures. Your Chance: Want to test a professional analytics software?
Cloudera and Cisco have tested together with dense storage nodes to make this a reality. . Can support billions of files ( tested up to 10 billion files) in contrast with HDFS which runs into scalability thresholds at 400 million files. Collects and aggregates metadata from components and present cluster state. Failure Handling.
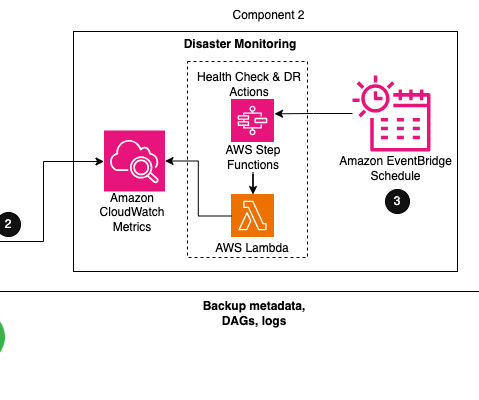
Within Airflow, the metadata database is a core component storing configuration variables, roles, permissions, and DAG run histories. A healthy metadata database is therefore critical for your Airflow environment. AWS publishes our most up-to-the-minute information on service availability on the Service Health Dashboard.
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets. Key Design Principles of a Data Mesh.
This separation means changes can be tested thoroughly before being deployed to live operations. Delta tables technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog. The overall structure can be represented in the following figure.
These services include the ability to auto-discover and classify data, to detect sensitive information, to analyze data quality, to link business terms to technical metadata and to publish data to the knowledge catalog.
Allows them to iteratively develop processing logic and test with as little overhead as possible. With the general availability of DataFlow Designer, developers can now implement their data pipelines by building, testing, deploying, and monitoring data flows in one unified user interface that meets all their requirements.
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. Centralized catalog for published data – Multiple producers release data currently governed by their respective entities. For consumer access, a centralized catalog is necessary where producers can publish their data assets.
AWS Glue Data Catalog stores information as metadata tables, where each table specifies a single data store. The AWS Glue crawler writes metadata to the Data Catalog by classifying the data to determine the format, schema, and associated properties of the data. We can query partitioned logs directly in Amazon S3 using standard SQL.
In data governance terms, an automation framework refers to a metadata-driven universal code generator that works hand in hand with enterprise data mapping for: Pre-ETL enterprise data mapping. Governing metadata. The 100-percent metadata-driven approach is critical to creating reliable and consistent CATs.
After all, it’s very likely that you are developing your flow against test systems but in production it needs to run against production systems, meaning that your source and destination connection configuration has to be adjusted. To meet this need we’ve introduced a new concept called test sessions with the DataFlow Designer. .
Its platform supports both publishers and advertisers so both can understand which creative work delivers the best results. Publishers find a privacy-safe way to deliver first-party information to advertisers while advertisers get the information they need to track performance across all of the publishing platforms in the open web.
Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. This metadata file is later used to read source file names during processing into the staging layer. The Redshift publish zone is a different set of tables in the same Redshift provisioned cluster.
This simplifies the process for data consumers to find datasets, understand their context through shared metadata, and access comprehensive datasets for specific use cases through a single workflow. With data products, Amazon DataZone now supports business use case based grouping, enhancing data publishing, discovery, and subscription.
We also share a Spark benchmark solution that suits all Amazon EMR deployment options, so you can replicate the process in your environment for your own performance test cases. The solution uses the TPC-DS dataset and unmodified data schema and table relationships, but derives queries from TPC-DS to support the SparkSQL test cases.
AWS has invested in native service integration with Apache Hudi and published technical contents to enable you to use Apache Hudi with AWS Glue (for example, refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started ).
It provides the core infrastructure for solutions where modeling agility, data integration, relationship exploration, cross-enterprise data publishing and consumption are critical. GraphDB: MongoDB Document Store Integration for Large-scale Metadata Management. Choose The Best RDF Database for Metadata Management.
These models originate from different use cases: distributed knowledge representation and open data publishing on the web vs graph analytics designed to be as easy to start with as possible. Interesting attendee question : Should I model my data, such as start and end date, as metadata with embedded triples or as N-ary concepts?
For example, it’s data generated as a result of text mining algorithms that includes document metadata attributes and annotations with links to the first type of information. For the following demonstration, we will use a subset of the LDBC Semantic Publishing Benchmark. Choose The Best RDF Database for Metadata Management.
Digital storytelling To entice a technical partner to build the digital site, the ODSE published an RFP and received 15 qualified IT specialists that wanted to take on the immense task of digitally recreating a multifloor museum.
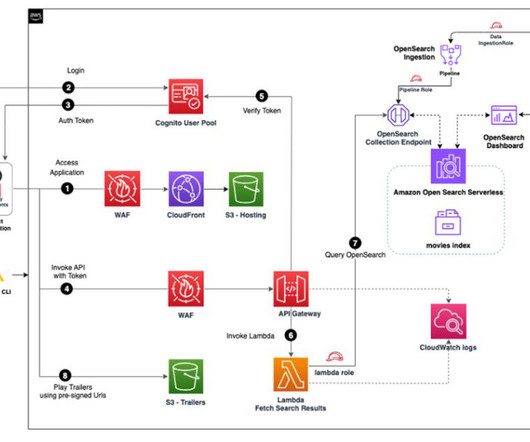
Amazon API Gateway is a fully managed service that makes it straightforward for developers to create, publish, maintain, monitor, and secure APIs at any scale. The Lambda function queries OpenSearch Serverless and returns the metadata for the search. Based on metadata, content is returned from Amazon S3 to the user.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content